min dalle
v0.4
YouTube Walk-Through oleh AI Epiphany
Ini adalah pelabuhan minimal yang cepat dan minimal dari Boris Dayma Dall · e mini (dengan berat mega). Telah dilucuti untuk inferensi dan dikonversi ke Pytorch. Satu -satunya dependensi pihak ketiga adalah Numpy, Permintaan, Bantal dan Obor.
Untuk menghasilkan grid 3x3 dari Dall · e mega yang dibutuhkan:
Berikut adalah rincian kinerja yang lebih rinci pada A100. Kredit untuk @technobird22 dan bot Neogen Discord -nya untuk grafik. 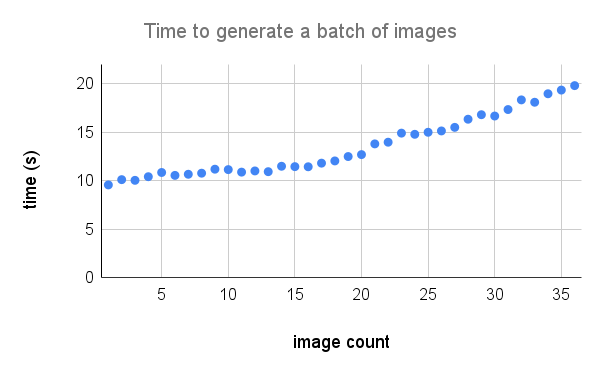
Model rami dan kode untuk mengubahnya menjadi obor dapat ditemukan di sini.
$ pip install min-dalleMuat parameter model sekali dan gunakan kembali model untuk menghasilkan banyak gambar.
from min_dalle import MinDalle
model = MinDalle (
models_root = './pretrained' ,
dtype = torch . float32 ,
device = 'cuda' ,
is_mega = True ,
is_reusable = True
) Model yang diperlukan akan diunduh ke models_root jika belum ada di sana. Atur dtype ke torch.float16 untuk menyimpan memori GPU. Jika Anda memiliki GPU arsitektur Ampere, Anda dapat menggunakan torch.bfloat16 . Atur device ke "CUDA" atau "CPU". Setelah semuanya selesai diinisialisasi, panggilan generate_image dengan beberapa teks sebanyak yang Anda inginkan. Gunakan seed positif untuk hasil yang dapat direproduksi. Nilai yang lebih tinggi untuk supercondition_factor menghasilkan kesepakatan yang lebih baik dengan teks tetapi variasi gambar yang dihasilkan lebih sempit. Setiap token gambar diambil sampelnya dari token top_k mungkin. Logit terbesar dikurangi dari log untuk menghindari INF. Logit kemudian dibagi berdasarkan temperature . Jika is_seamless benar, kisi -kisi gambar akan ubin di ruang token bukan ruang piksel.
image = model . generate_image (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 4 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 32 ,
is_verbose = False
)
display ( image )
Kredit ke @hardmaru untuk contoh
Gambar juga dapat dihasilkan sebagai FloatTensor jika Anda ingin memprosesnya secara manual.
images = model . generate_images (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 3 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)Untuk mendapatkan gambar ke dalam format PIL Anda harus terlebih dahulu memindahkan gambar ke CPU dan mengonversi tensor ke array yang tidak bagus.
images = images . to ( 'cpu' ). numpy () Lalu gambar
image = Image . fromarray ( images [ i ])
image . save ( 'image_{}.png' . format ( i )) Jika model sedang digunakan secara interaktif (misalnya dalam notebook) generate_image_stream dapat digunakan untuk menghasilkan aliran gambar karena model decoding. Detokenizer menambahkan sedikit penundaan untuk setiap gambar. Atur progressive_outputs ke True untuk mengaktifkan ini. Contoh diimplementasikan dalam colab.
image_stream = model . generate_image_stream (
text = 'Dali painting of WALL·E' ,
seed = - 1 ,
grid_size = 3 ,
progressive_outputs = True ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)
for image in image_stream :
display ( image )
Gunakan image_from_text.py untuk menghasilkan gambar dari baris perintah.
$ python image_from_text.py --text= ' artificial intelligence ' --no-mega


