prompt poet
1.0.0
Приглашенный поэт оптимизирует и упрощает быстрый дизайн как для разработчиков, так и для нетехнических пользователей с его подходом с низким кодом. Используя смесь YAML и Jinja2, Prompt Poet позволяет создавать гибкое, динамическое быстрое создание, повышая эффективность и качество взаимодействия с моделями ИИ. Это экономит время на инженерных манипуляциях струн, позволяя каждому сосредоточиться на создании оптимальных подсказок для своих пользователей.
pip install prompt-poet import os
import getpass
from prompt_poet import Prompt
from langchain import ChatOpenAI
# Uncomment if you need to set OPENAI_API_KEY.
# os.environ["OPENAI_API_KEY"] = getpass.getpass()
raw_template = """
- name: system instructions
role: system
content: |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name: user query
role: user
content: |
{{ username}}: {{ user_query }}
- name: response
role: user
content: |
{{ character_name }}:
"""
template_data = {
"character_name" : "Character Assistant" ,
"username" : "Jeff" ,
"user_query" : "Can you help me with my homework?"
}
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data
)
model = ChatOpenAI ( model = "gpt-4o-mini" )
response = model . invoke ( prompt . messages )Шаблоны быстрого поэта используют смесь YAML и Jinja2. Обработка шаблона происходит на двух первичных этапах:
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Если у вас есть элементы (например, сообщения) в списке, вы можете проанализировать их в своем шаблоне так.
{% for message in current_chat_messages %}
- name : chat_message
role : user
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} Длина контекста ограничена и не всегда может соответствовать всей истории чата - поэтому мы можем установить приоритет усечения на частях сообщения, а поэт -подсказка усеет эти части в том порядке, в котором они появляются (самые старые по самым новым).
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} Адаптировать инструкции на основе текущей модальности пользователя (аудио или текст).
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio. Keep your answers succinct.
{% endif %} Чтобы включить конкретные примеры, такие как домашняя работа, когда это необходимо.
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %} Приглашенный поэт по умолчанию лишит пробелы, чтобы избежать нежелательных новичков в вашем окончательном подсказке. Если вы хотите включить явное пространство, используйте специальный встроенный маркер пространства «<| Space |>», чтобы обеспечить правильное форматирование.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
<|space|>{{ username}}: {{ user_query }} Композиционность является основной силой шаблонов быстрого поэта, обеспечивающего создание сложных, динамических подсказок.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio modality. Keep your answers succinct and to the point.
{% endif %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %}
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %}
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Чтобы поддерживать сухие принципы в ваших шаблонах, разбейте их на многоразовые секции, которые могут применяться в разных шаблонах, например, когда A/B тестирование новой подсказки.
{% include 'sections/system_instruction.yml.j2' %}
{% include 'sections/audio_instruction.yml.j2' %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% include 'sections/homework_examples.yml.j2' %}
{% endif %}
{% include 'sections/chat_messages.yml.j2' %}
{% include 'sections/user_query.yml.j2' %}
{% include 'sections/reply_prompt.yml.j2' %}Библиотека Prompt Poet предоставляет различные функции и настройки, включая свойства быстрого. Ключевые особенности, такие как токенизация и усечение, помогают с эффективным кэшированием и низкой задержкой ответов
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
# Inspect prompt as a raw string.
prompt . string : str
> >> "..."
# Inpsect the prompt as raw tokens.
prompt . tokens : list [ int ]
> >> [...]
# Inspect the prompt as LLM API message dicts.
prompt . messages : list [ dict ]
> >> [...]
# Inspect the prompt as first class parts.
prompt . parts : list [ PromptPart ]
> >> [...]Jinja2 и Yaml объединяются, чтобы предложить невероятно расширяемый и выразительный язык шаблон. Jinja2 облегчает прямые привязки данных, произвольные вызовы функций и базовый поток управления в шаблонах. YAML обеспечивает структуру для наших шаблонов (с глубиной = 1), позволяя нам выполнять сложное усечение, когда достигнут предел токена. Это спаривание Jinja2 и YAML не уникально - в частности, оно используется Ansible.
Одной из выдающихся особенностей Jinja2 является возможность вызывать произвольные функции Python непосредственно в шаблонах во время выполнения. Эта функция имеет решающее значение для поиска, манипулирования и проверки данных на лету, оптимизируя, как строятся подсказки. Здесь extract_user_query_topic может выполнить произвольную обработку запроса пользователя, используемого в потоке управления шаблона-возможно, выполняя поездку в обратном пути к классификатору темы.
{ % if extract_user_query_topic ( user_query ) == "homework_help" % }
{ % for homework_example in fetch_few_shot_homework_examples ( username , character_name ) % }
- name : homework_example_ {{ loop . index }}
role : user
content : |
{{ homework_example }}
{ % endfor % }
{ % endif % } По умолчанию поэт будет использовать Tiktoken Tiktoken «O200K_BASE», хотя альтернативные имена кодирования могут быть представлены в tiktoken_encoding_name . В качестве альтернативы пользователи могут предоставить свою собственную функцию ENCODE с помощью encode_func: Callable[[str], list[int]] .
from tiktoken import get_encoding
encode_func = get_encoding ( "o200k_base" )
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data ,
encode_func = encode_func
)
prompt . tokenize ()
prompt . tokens
> >> [...]Если ваш поставщик LLM поддерживает сродство графического процессора и кэш префикса, используйте алгоритм усечения характера. Скорость кэша префикса определяется как количество токенов, полученных из кэша, из -за общего количества токенов при быстрых требованиях. Найдите оптимальные значения для шага усечения и предела токена для вашего варианта использования. По мере увеличения этапа усечения скорость префикса также возрастает, но больше токенов усекаются с помощью подсказки.
TOKEN_LIMIT = 128000
TRUNCATION_STEP = 4000
# Tokenize and truncate the prompt.
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
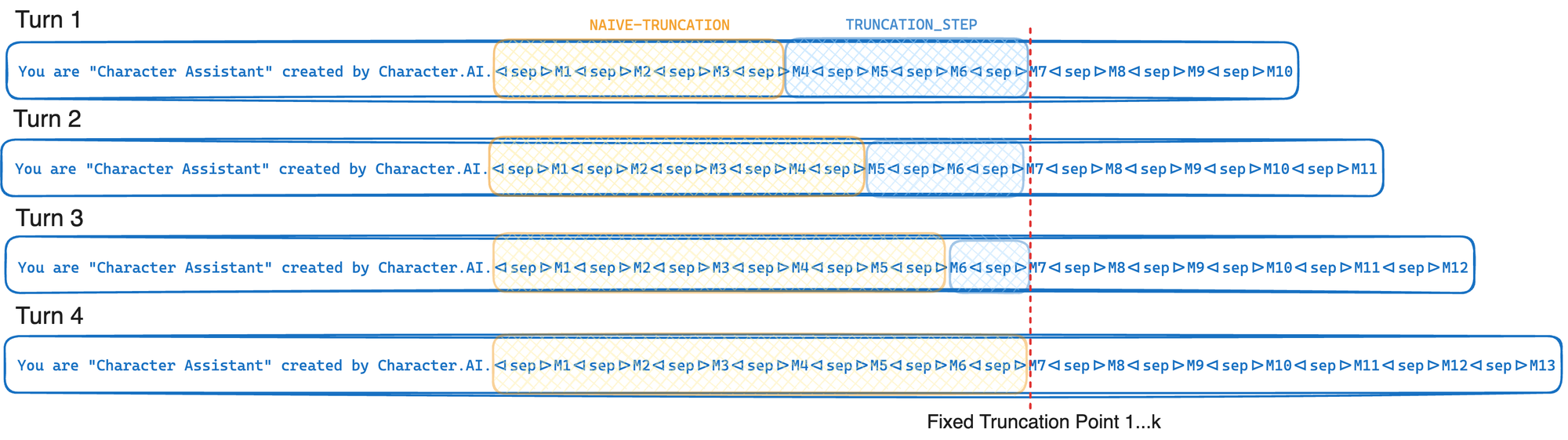
response = model . invoke ( prompt . messages )Короче говоря, усечение усечения кэша усекается до фиксированной точки усечения каждый раз, когда его вызывают - только перемещая эту точку усечения в среднем в каждом K. Это позволяет вашему поставщику LLM максимально использовать кэш префикса GPU, описанный при оптимизации вывода. Если вместо этого мы просто усекнули до достижения предела токена (L), эта точка усечения переместит каждый шаг, что вызовет значительное снижение скорости кэша префикса. Компромисс в этом подходе заключается в том, что мы часто усекаем больше, чем нам необходимо.
Реестр шаблонов - это просто концепция хранения шаблонов в качестве файлов на диске. Используя реестр шаблонов, вы можете выделить файлы шаблонов из кода Python и загружать эти файлы непосредственно с диска. В производственных системах эти файлы шаблонов можно загрузить из кэша в памяти при последовательном использовании, сохранение на дисковом вводе/выводе. В будущем реестр шаблонов может стать первоклассным гражданином быстрого поэта.
Имя файла: CHAT_TEMPLATE.YML.J2
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : response
role : user
content : |
{{ character_name }}: Запустите этот код Python из того же каталога, который вы сохранили файл chat_template.yml.j2 to.
from prompt_poet import Prompt
prompt = Prompt (
template_path = "chat_template.yml.j2" ,
template_data = template_data
)
print ( prompt . string )
> >> 'Your name is Character Assistant and you are meant to be helpful and never harmful to humans.Jeff: Can you help me with my homework?Character Assistant:'

