prompt poet
1.0.0
Penyair yang cepat merampingkan dan menyederhanakan desain yang cepat untuk pengembang dan pengguna non-teknis dengan pendekatan kode rendahnya. Menggunakan campuran YAML dan JINJA2, penyair cepat memungkinkan untuk pembuatan cepat yang fleksibel dan dinamis, meningkatkan efisiensi dan kualitas interaksi dengan model AI. Ini menghemat waktu pada manipulasi string rekayasa, memungkinkan semua orang untuk lebih fokus pada membuat prompt optimal untuk pengguna mereka.
pip install prompt-poet import os
import getpass
from prompt_poet import Prompt
from langchain import ChatOpenAI
# Uncomment if you need to set OPENAI_API_KEY.
# os.environ["OPENAI_API_KEY"] = getpass.getpass()
raw_template = """
- name: system instructions
role: system
content: |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name: user query
role: user
content: |
{{ username}}: {{ user_query }}
- name: response
role: user
content: |
{{ character_name }}:
"""
template_data = {
"character_name" : "Character Assistant" ,
"username" : "Jeff" ,
"user_query" : "Can you help me with my homework?"
}
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data
)
model = ChatOpenAI ( model = "gpt-4o-mini" )
response = model . invoke ( prompt . messages )Template penyair yang cepat menggunakan campuran Yaml dan Jinja2. Pemrosesan template terjadi pada dua tahap utama:
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Jika Anda memiliki elemen (misalnya pesan) dalam daftar, Anda dapat menguraikannya ke dalam templat Anda seperti itu.
{% for message in current_chat_messages %}
- name : chat_message
role : user
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} Panjang konteks terbatas dan tidak selalu sesuai dengan seluruh riwayat obrolan - sehingga kita dapat menetapkan prioritas pemotongan pada bagian pesan dan penyair yang cepat akan memotong bagian -bagian ini dalam urutan di mana mereka muncul (yang tertua hingga terbaru).
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} Untuk menyesuaikan instruksi berdasarkan modalitas pengguna saat ini (audio atau teks).
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio. Keep your answers succinct.
{% endif %} Untuk memasukkan contoh khusus konteks seperti bantuan pekerjaan rumah saat dibutuhkan.
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %} Penyair prompt akan menelanjangi Whitespace secara default untuk menghindari Newline yang tidak diinginkan di prompt akhir Anda. Jika Anda ingin memasukkan ruang eksplisit, gunakan penanda ruang bawaan khusus “<| space |>” untuk memastikan pemformatan yang tepat.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
<|space|>{{ username}}: {{ user_query }} Komposisionalitas adalah kekuatan inti dari templat penyair yang cepat, memungkinkan penciptaan petunjuk yang kompleks dan dinamis.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio modality. Keep your answers succinct and to the point.
{% endif %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %}
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %}
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Untuk mempertahankan prinsip -prinsip kering dalam templat Anda, memecahnya menjadi bagian yang dapat digunakan kembali yang dapat diterapkan di berbagai templat, seperti ketika A/B menguji prompt baru.
{% include 'sections/system_instruction.yml.j2' %}
{% include 'sections/audio_instruction.yml.j2' %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% include 'sections/homework_examples.yml.j2' %}
{% endif %}
{% include 'sections/chat_messages.yml.j2' %}
{% include 'sections/user_query.yml.j2' %}
{% include 'sections/reply_prompt.yml.j2' %}Perpustakaan Penyair Prompt menyediakan berbagai fitur dan pengaturan, termasuk properti prompt. Fitur Utama Seperti Tokenisasi dan Pemotongan Bantuan Dengan Caching yang Efisien dan Respons Latensi Rendah
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
# Inspect prompt as a raw string.
prompt . string : str
> >> "..."
# Inpsect the prompt as raw tokens.
prompt . tokens : list [ int ]
> >> [...]
# Inspect the prompt as LLM API message dicts.
prompt . messages : list [ dict ]
> >> [...]
# Inspect the prompt as first class parts.
prompt . parts : list [ PromptPart ]
> >> [...]Jinja2 dan YAML bergabung untuk menawarkan bahasa templating yang sangat luas dan ekspresif. Jinja2 memfasilitasi binding data langsung, panggilan fungsi sewenang -wenang, dan aliran kontrol dasar dalam templat. YAML menyediakan struktur untuk templat kami (dengan kedalaman = 1) memungkinkan kami untuk melakukan pemotongan canggih ketika batas token tercapai. Pasangan Jinja2 dan YAML ini tidak unik - terutama digunakan oleh Ansible.
Salah satu fitur yang menonjol dari Jinja2 adalah kemampuan untuk memohon fungsi python sewenang -wenang secara langsung dalam templat saat runtime. Fitur ini sangat penting untuk pengambilan data on-the-fly, manipulasi, dan validasi, merampingkan bagaimana petunjuk dibangun. Di sini extract_user_query_topic dapat melakukan pemrosesan sewenang-wenang dari kueri pengguna yang digunakan dalam aliran kontrol template-mungkin dengan melakukan perjalanan bundar ke pengklasifikasi topik.
{ % if extract_user_query_topic ( user_query ) == "homework_help" % }
{ % for homework_example in fetch_few_shot_homework_examples ( username , character_name ) % }
- name : homework_example_ {{ loop . index }}
role : user
content : |
{{ homework_example }}
{ % endfor % }
{ % endif % } Secara default penyair prompt akan menggunakan tokenizer Tiktoken "O200K_BASE" meskipun nama pengkodean alternatif dapat disediakan di tingkat atas tiktoken_encoding_name . Atau, pengguna dapat memberikan fungsi Encode mereka sendiri dengan level atas encode_func: Callable[[str], list[int]] .
from tiktoken import get_encoding
encode_func = get_encoding ( "o200k_base" )
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data ,
encode_func = encode_func
)
prompt . tokenize ()
prompt . tokens
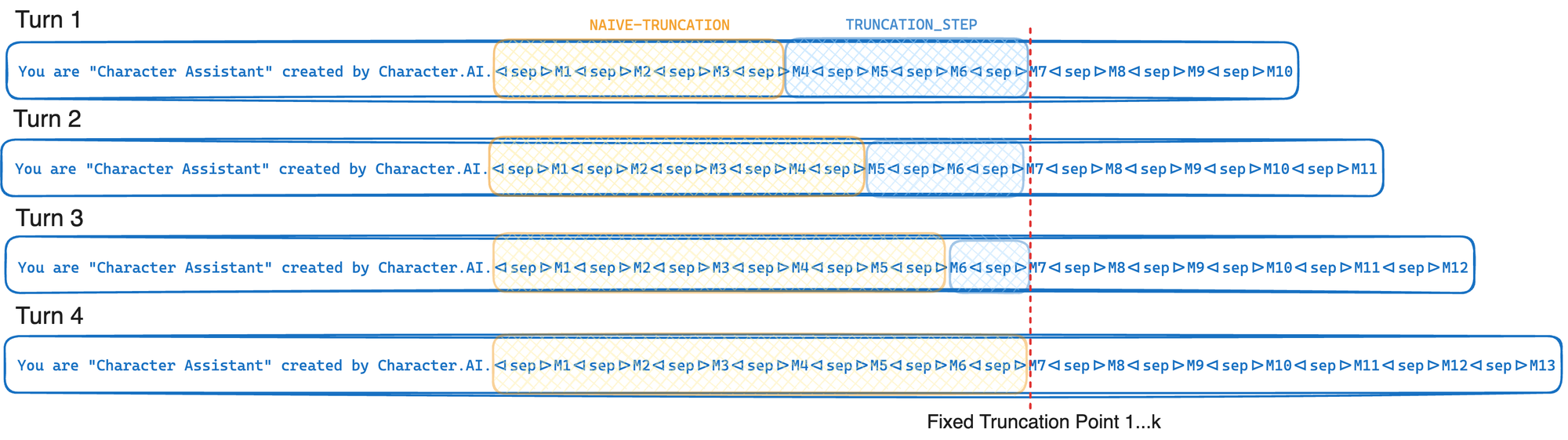
> >> [...]Jika penyedia LLM Anda mendukung afinitas GPU dan cache awalan, gunakan algoritma pemotongan karakter.ai untuk memaksimalkan laju cache awalan. Tingkat cache awalan didefinisikan sebagai jumlah token prompt yang diambil dari cache atas jumlah total token prompt. Temukan nilai optimal untuk langkah pemotongan dan batas token untuk kasus penggunaan Anda. Ketika langkah pemotongan meningkat, tingkat cache awalan juga naik, tetapi lebih banyak token dipotong dari prompt.
TOKEN_LIMIT = 128000
TRUNCATION_STEP = 4000
# Tokenize and truncate the prompt.
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
response = model . invoke ( prompt . messages )Singkatnya, pemotongan yang sadar cache dipotong hingga titik pemotongan tetap setiap kali dipanggil - hanya memindahkan titik pemotongan ini rata -rata setiap K belokan. Ini memungkinkan penyedia LLM Anda untuk mengeksploitasi cache awalan GPU secara maksimal yang dijelaskan dalam mengoptimalkan inferensi. Jika sebaliknya kita hanya terpotong sampai mencapai batas token (l) titik pemotongan ini akan bergerak setiap belokan yang akan menyebabkan pengurangan yang signifikan dalam tingkat cache awalan. Pengorbanan dalam pendekatan ini adalah bahwa kita sering memotong lebih dari yang kita butuhkan.
Registri template hanyalah konsep menyimpan templat sebagai file pada disk. Dalam menggunakan registri template, Anda dapat mengisolasi file template dari kode python Anda dan memuat file -file ini langsung dari disk. Dalam sistem produksi, file templat ini secara opsional dapat dimuat dari cache dalam memori pada penggunaan berturut-turut, menyimpan pada disk I/O. Di masa depan, pendaftaran template dapat menjadi warga negara penyair yang cepat.
Nama file: chat_template.yml.j2
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : response
role : user
content : |
{{ character_name }}: Jalankan kode Python ini dari direktori yang sama Anda telah menyimpan file chat_template.yml.j2 ke.
from prompt_poet import Prompt
prompt = Prompt (
template_path = "chat_template.yml.j2" ,
template_data = template_data
)
print ( prompt . string )
> >> 'Your name is Character Assistant and you are meant to be helpful and never harmful to humans.Jeff: Can you help me with my homework?Character Assistant:'

