prompt poet
1.0.0
Der schnelle Poet optimiert und vereinfacht das schnelle Design sowohl für Entwickler als auch für nicht-technische Benutzer mit seinem niedrigen Code-Ansatz. Durch die Verwendung einer Mischung aus Yaml und Jinja2 ermöglicht der schnelle Dichter eine flexible, dynamische Erstellung von sofortiger Erstellung, wodurch die Effizienz und Qualität von Interaktionen mit KI -Modellen verbessert wird. Es spart Zeit für die Manipulationen für String -Saiten und ermöglicht es allen, sich mehr darauf zu konzentrieren, die optimalen Aufforderungen für seine Benutzer zu erstellen.
pip install prompt-poet import os
import getpass
from prompt_poet import Prompt
from langchain import ChatOpenAI
# Uncomment if you need to set OPENAI_API_KEY.
# os.environ["OPENAI_API_KEY"] = getpass.getpass()
raw_template = """
- name: system instructions
role: system
content: |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name: user query
role: user
content: |
{{ username}}: {{ user_query }}
- name: response
role: user
content: |
{{ character_name }}:
"""
template_data = {
"character_name" : "Character Assistant" ,
"username" : "Jeff" ,
"user_query" : "Can you help me with my homework?"
}
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data
)
model = ChatOpenAI ( model = "gpt-4o-mini" )
response = model . invoke ( prompt . messages )Schnurende Dichtervorlagen verwenden eine Mischung aus Yaml und Jinja2. Die Vorlagenverarbeitung erfolgt in zwei Primärstadien:
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Wenn Sie Elemente (z. B. Nachrichten) in einer Liste haben, können Sie sie so in Ihre Vorlage analysieren.
{% for message in current_chat_messages %}
- name : chat_message
role : user
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} Die Kontextlänge ist begrenzt und kann nicht immer in den gesamten Chat -Historie passen. Daher können wir die Meldungsteile Priorität festlegen, und der schnelle Dichter wird diese Teile in der Reihenfolge abschneiden, in der sie erscheinen (älteste bis neueste).
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} Anweisungen basierend auf der aktuellen Modalität des Benutzers (Audio oder Text).
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio. Keep your answers succinct.
{% endif %} Um kontextspezifische Beispiele wie Hausaufgaben bei Bedarf einzubeziehen.
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %} Der schnelle Dichter wird standardmäßig die Whitespace ausziehen, um unerwünschte Neulinge in Ihrer endgültigen Eingabeaufforderung zu vermeiden. Wenn Sie einen expliziten Platz einfügen möchten, verwenden Sie den speziellen integrierten Raummarker „<| Space |>“, um eine ordnungsgemäße Formatierung zu gewährleisten.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
<|space|>{{ username}}: {{ user_query }} Kompositionalität ist eine Kernstärke von schnellen Dichtervorlagen, die die Erstellung komplexer, dynamischer Aufforderungen ermöglichen.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio modality. Keep your answers succinct and to the point.
{% endif %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %}
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %}
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Um trockene Prinzipien in Ihren Vorlagen aufrechtzuerhalten, zeugen Sie sie in wiederverwendbare Abschnitte, die auf verschiedene Vorlagen angewendet werden können, z. B. beim Testen von A/B eine neue Eingabeaufforderung.
{% include 'sections/system_instruction.yml.j2' %}
{% include 'sections/audio_instruction.yml.j2' %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% include 'sections/homework_examples.yml.j2' %}
{% endif %}
{% include 'sections/chat_messages.yml.j2' %}
{% include 'sections/user_query.yml.j2' %}
{% include 'sections/reply_prompt.yml.j2' %}Die schnelle Poet -Bibliothek bietet verschiedene Funktionen und Einstellungen, einschließlich der schnellen Eigenschaften. Schlüsselmerkmale wie Tokenisierung und Kürzung helfen bei effizienten Caching und niedrigen Latenzreaktionen
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
# Inspect prompt as a raw string.
prompt . string : str
> >> "..."
# Inpsect the prompt as raw tokens.
prompt . tokens : list [ int ]
> >> [...]
# Inspect the prompt as LLM API message dicts.
prompt . messages : list [ dict ]
> >> [...]
# Inspect the prompt as first class parts.
prompt . parts : list [ PromptPart ]
> >> [...]Jinja2 und Yaml kombinieren eine unglaublich erweiterbare und ausdrucksstarke Vorlagensprache. Jinja2 erleichtert direkte Datenbindungen, willkürliche Funktionsaufrufe und grundlegende Steuerfluss innerhalb der Vorlagen. YAML bietet Struktur unseren Vorlagen (mit Tiefe = 1), sodass wir eine anspruchsvolle Kürzung durchführen können, wenn die Token -Grenze erreicht ist. Diese Paarung von Jinja2 und Yaml ist nicht einzigartig - vor allem wird sie von Ansible verwendet.
Ein herausragendes Merkmal von Jinja2 ist die Fähigkeit, willkürliche Python -Funktionen direkt innerhalb der Vorlagen zur Laufzeit aufzurufen. Diese Funktion ist entscheidend für das Abrufen, Manipulation und Validieren von Daten auf dem Fliege, um die Aufforderung zu optimieren. Hier kann extract_user_query_topic die im Steuerfluss der Vorlage verwendete Abfrage des Benutzers eine beliebige Verarbeitung durchführen-vielleicht durch Durchführung eines Rundwegs zu einem Themenklassifizierer.
{ % if extract_user_query_topic ( user_query ) == "homework_help" % }
{ % for homework_example in fetch_few_shot_homework_examples ( username , character_name ) % }
- name : homework_example_ {{ loop . index }}
role : user
content : |
{{ homework_example }}
{ % endfor % }
{ % endif % } Standardmäßig verwendet der Eingabeaufforderungsdichter den Tokenizer "O200K_Base" Tiktoken, obwohl alternative Codierungsnamen im oberen Ebenen tiktoken_encoding_name angegeben werden können. Alternativ können Benutzer ihre eigene Encode-Funktion mit der obersten Ebene encode_func: Callable[[str], list[int]] bereitstellen.
from tiktoken import get_encoding
encode_func = get_encoding ( "o200k_base" )
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data ,
encode_func = encode_func
)
prompt . tokenize ()
prompt . tokens
> >> [...]Wenn Ihr LLM-Anbieter die GPU-Affinität und den Präfix-Cache unterstützt, verwenden Sie den Abkürzungsalgorithmus von Character.AI, um den Präfix-Cache-Rate zu maximieren. Die Präfix -Cache -Rate wird definiert als die Anzahl der Eingabeaufforderungen, die aus dem Cache über die Gesamtzahl der Eingabeauffordern -Token abgerufen werden. Suchen Sie die optimalen Werte für den Schnellschritt und die Token -Grenze für Ihren Anwendungsfall. Mit zunehmender Kürzungsschritt steigt auch die Präfix -Cache -Rate, aber mehr Token werden aus der Eingabeaufforderung abgeschnitten.
TOKEN_LIMIT = 128000
TRUNCATION_STEP = 4000
# Tokenize and truncate the prompt.
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
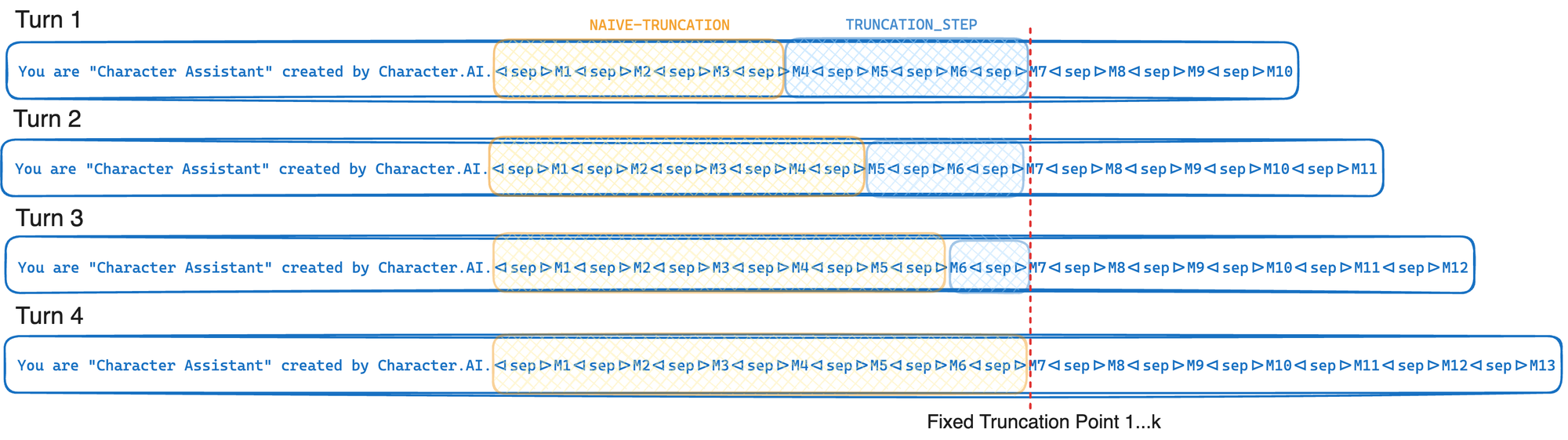
response = model . invoke ( prompt . messages )Kurz gesagt, Cache -Awes -Kürzung Kürzung bis zu einem festen Kürzungspunkt jedes Mal, wenn er aufgerufen wird - bewegt diesen Kürzungspunkt im Durchschnitt jedes K -Wendungen. Dies ermöglicht es Ihrem LLM -Anbieter, das in der Optimierung der Inferenz beschriebene GPU -Präfix -Cache maximal auszunutzen. Wenn wir stattdessen einfach abschneiden, bis wir die Token -Grenze (l) erreicht haben, wird dieser Kürzungspunkt in jeder Runde bewegen, was zu einer signifikanten Verringerung der Präfix -Cache -Rate führen würde. Der Kompromiss in diesem Ansatz ist, dass wir oft mehr abschneiden, als wir es mir ausdrücklich brauchen.
Eine Vorlagenregistrierung ist einfach das Konzept, Vorlagen als Dateien auf der Festplatte zu speichern. Bei Verwendung einer Vorlagenregistrierung können Sie Vorlagendateien aus Ihrem Python -Code isolieren und diese Dateien direkt von der Festplatte laden. In Produktionssystemen können diese Vorlagendateien optional aus einem In-Memory-Cache für aufeinanderfolgende Verwendungszwecke geladen werden, wodurch die Festplatten-E/A gespeichert werden. In Zukunft kann ein Vorlagenregister ein erstklassiger Bürger des schnellen Dichters werden.
Dateiname: chat_template.yml.j2
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : response
role : user
content : |
{{ character_name }}: Führen Sie diesen Python -Code aus demselben Verzeichnis aus. Sie haben die Datei chat_template.yml.j2 auf gespeichert.
from prompt_poet import Prompt
prompt = Prompt (
template_path = "chat_template.yml.j2" ,
template_data = template_data
)
print ( prompt . string )
> >> 'Your name is Character Assistant and you are meant to be helpful and never harmful to humans.Jeff: Can you help me with my homework?Character Assistant:'

