prompt poet
1.0.0
O poeta rápido simplifica e simplifica o design imediato para desenvolvedores e usuários não técnicos com sua abordagem de baixo código. Usando uma mistura de YAML e JINJA2, o Poeta Prompante permite uma criação rápida e dinâmica flexível, aumentando a eficiência e a qualidade das interações com os modelos de IA. Ele economiza tempo em manipulações de cordas de engenharia, permitindo que todos se concentrem mais na elaboração das instruções ideais para seus usuários.
pip install prompt-poet import os
import getpass
from prompt_poet import Prompt
from langchain import ChatOpenAI
# Uncomment if you need to set OPENAI_API_KEY.
# os.environ["OPENAI_API_KEY"] = getpass.getpass()
raw_template = """
- name: system instructions
role: system
content: |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name: user query
role: user
content: |
{{ username}}: {{ user_query }}
- name: response
role: user
content: |
{{ character_name }}:
"""
template_data = {
"character_name" : "Character Assistant" ,
"username" : "Jeff" ,
"user_query" : "Can you help me with my homework?"
}
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data
)
model = ChatOpenAI ( model = "gpt-4o-mini" )
response = model . invoke ( prompt . messages )Os modelos de poeta imediato usam uma mistura de YAML e Jinja2. O processamento de modelos ocorre em dois estágios primários:
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Se você tiver elementos (por exemplo, mensagens) em uma lista, poderá analisá -los em seu modelo como assim.
{% for message in current_chat_messages %}
- name : chat_message
role : user
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} O comprimento do contexto é limitado e nem sempre pode se encaixar em todo o histórico de bate -papo - para que possamos definir uma prioridade de truncamento nas peças da mensagem e o Poeta Prompt truncará essas peças na ordem em que elas aparecem (mais antigas ao mais novo).
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} Para adaptar as instruções com base na modalidade atual do usuário (áudio ou texto).
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio. Keep your answers succinct.
{% endif %} Para incluir exemplos específicos do contexto, como a ajuda de lição de casa, quando necessário.
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %} O Poet Poet tirará o espaço em branco por padrão para evitar novas linhas indesejadas no seu prompt final. Se você deseja incluir um espaço explícito, use o marcador de espaço interno especial “<| espacial |>” para garantir a formatação adequada.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
<|space|>{{ username}}: {{ user_query }} A composicionalidade é uma força central dos modelos de poeta imediato, permitindo a criação de avisos complexos e dinâmicos.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio modality. Keep your answers succinct and to the point.
{% endif %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %}
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %}
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Para manter os princípios secos em seus modelos, divida -os em seções reutilizáveis que podem ser aplicadas em diferentes modelos, como quando A/B testando um novo prompt.
{% include 'sections/system_instruction.yml.j2' %}
{% include 'sections/audio_instruction.yml.j2' %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% include 'sections/homework_examples.yml.j2' %}
{% endif %}
{% include 'sections/chat_messages.yml.j2' %}
{% include 'sections/user_query.yml.j2' %}
{% include 'sections/reply_prompt.yml.j2' %}A pronta biblioteca de poetas fornece vários recursos e configurações, incluindo propriedades rápidas. Os principais recursos, como tokenização e truncamento, ajudam com cache eficiente e respostas de baixa latência
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
# Inspect prompt as a raw string.
prompt . string : str
> >> "..."
# Inpsect the prompt as raw tokens.
prompt . tokens : list [ int ]
> >> [...]
# Inspect the prompt as LLM API message dicts.
prompt . messages : list [ dict ]
> >> [...]
# Inspect the prompt as first class parts.
prompt . parts : list [ PromptPart ]
> >> [...]Jinja2 e Yaml se combinam para oferecer uma linguagem de modelagem incrivelmente extensível e expressiva. O JINJA2 facilita as ligações diretas de dados, as chamadas de função arbitrária e o fluxo de controle básico dentro dos modelos. A YAML fornece estrutura para nossos modelos (com profundidade = 1), permitindo que realizemos truncamento sofisticado quando o limite do token for atingido. Este emparelhamento de Jinja2 e Yaml não é único - principalmente é usado pela Ansible.
Um recurso de destaque do Jinja2 é a capacidade de invocar funções arbitrárias do Python diretamente dentro dos modelos em tempo de execução. Esse recurso é crucial para a recuperação de dados, manipulação e validação na fly-fly, simplificando como os avisos são construídos. Aqui extract_user_query_topic pode executar o processamento arbitrário da consulta do usuário usada no fluxo de controle do modelo-talvez executando uma viagem de ida e volta para um classificador de tópico.
{ % if extract_user_query_topic ( user_query ) == "homework_help" % }
{ % for homework_example in fetch_few_shot_homework_examples ( username , character_name ) % }
- name : homework_example_ {{ loop . index }}
role : user
content : |
{{ homework_example }}
{ % endfor % }
{ % endif % } Por padrão, o Poet Poet usará o tokenizador "O200K_BASE" do TikToken, embora os nomes de codificação alternativos possam ser fornecidos no tiktoken_encoding_name de nível superior. Como alternativa, os usuários podem fornecer sua própria função de codificação com o nível superior encode_func: Callable[[str], list[int]] .
from tiktoken import get_encoding
encode_func = get_encoding ( "o200k_base" )
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data ,
encode_func = encode_func
)
prompt . tokenize ()
prompt . tokens
> >> [...]Se o seu provedor LLM suportar a afinidade da GPU e o cache do prefixo, utilize o algoritmo de truncamento do caractere.ai para maximizar a taxa de prefixo. A taxa de cache do prefixo é definida como o número de tokens prompt recuperados do cache sobre o número total de tokens prompts. Encontre os valores ideais para a etapa de truncamento e o limite de token para o seu caso de uso. À medida que a etapa de truncamento aumenta, a taxa de cache do prefixo também aumenta, mas mais tokens são truncados a partir do prompt.
TOKEN_LIMIT = 128000
TRUNCATION_STEP = 4000
# Tokenize and truncate the prompt.
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
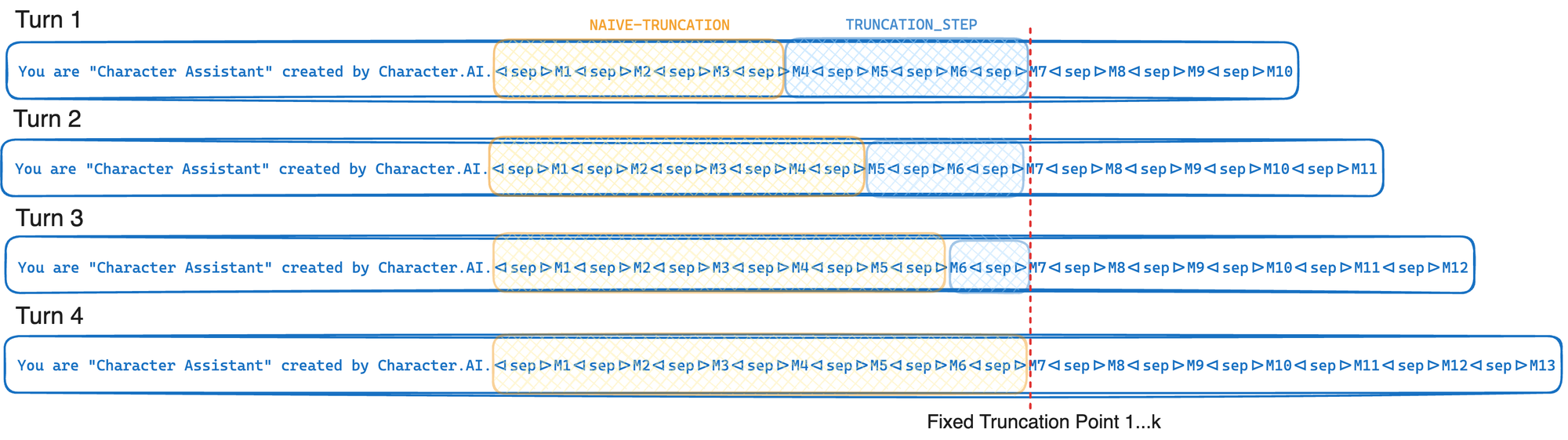
response = model . invoke ( prompt . messages )Em resumo, o truncamento cache cache trunca até um ponto de truncamento fixo toda vez que é invocado - movendo apenas esse ponto de truncamento em média a cada K voltas. Isso permite que seu provedor LLM explore o cache de prefixo da GPU ao máximo descrito na otimização de inferência. Se, em vez disso, simplesmente truncássemos até atingir o limite do token (l), esse ponto de truncamento moveria cada turno, o que causaria uma redução significativa na taxa de cache do prefixo. A troca nessa abordagem é que muitas vezes truncamos mais do que precisamos estritamente.
Um registro de modelo é simplesmente o conceito de armazenar modelos como arquivos no disco. Ao usar um registro de modelo, você pode isolar arquivos de modelo do seu código Python e carregar esses arquivos diretamente do disco. Nos sistemas de produção, esses arquivos de modelo podem opcionalmente ser carregados de um cache na memória em usos sucessivos, economizando na E/S do disco. No futuro, um registro de modelos pode se tornar um cidadão de primeira classe do Poeta Primeiro.
Nome do arquivo: chat_template.yml.j2
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : response
role : user
content : |
{{ character_name }}: Execute este código Python no mesmo diretório, você salvou o arquivo chat_template.yml.j2 .
from prompt_poet import Prompt
prompt = Prompt (
template_path = "chat_template.yml.j2" ,
template_data = template_data
)
print ( prompt . string )
> >> 'Your name is Character Assistant and you are meant to be helpful and never harmful to humans.Jeff: Can you help me with my homework?Character Assistant:'

