prompt poet
1.0.0
Le poète rapide rationalise et simplifie la conception rapide pour les développeurs et les utilisateurs non techniques avec son approche de code bas. En utilisant un mélange de YAML et Jinja2, un poète rapide permet une création invite dynamique flexible, améliorant l'efficacité et la qualité des interactions avec les modèles d'IA. Il fait gagner du temps sur les manipulations de chaînes d'ingénierie, permettant à chacun de se concentrer davantage sur la fabrication des invites optimales pour leurs utilisateurs.
pip install prompt-poet import os
import getpass
from prompt_poet import Prompt
from langchain import ChatOpenAI
# Uncomment if you need to set OPENAI_API_KEY.
# os.environ["OPENAI_API_KEY"] = getpass.getpass()
raw_template = """
- name: system instructions
role: system
content: |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name: user query
role: user
content: |
{{ username}}: {{ user_query }}
- name: response
role: user
content: |
{{ character_name }}:
"""
template_data = {
"character_name" : "Character Assistant" ,
"username" : "Jeff" ,
"user_query" : "Can you help me with my homework?"
}
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data
)
model = ChatOpenAI ( model = "gpt-4o-mini" )
response = model . invoke ( prompt . messages )Les modèles de poète rapides utilisent un mélange de YAML et Jinja2. Le traitement du modèle se produit en deux étapes principales:
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Si vous avez des éléments (par exemple, des messages) dans une liste, vous pouvez les analyser dans votre modèle comme ça.
{% for message in current_chat_messages %}
- name : chat_message
role : user
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} La longueur du contexte est limitée et ne peut pas toujours s'adapter à l'historique complet du chat - nous pouvons donc définir une priorité de troncature sur les parties du message et le poète rapide tronquera ces pièces dans l'ordre dans lequel ils apparaissent (le plus ancien au plus récent).
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %} Pour adapter les instructions en fonction de la modalité actuelle de l'utilisateur (audio ou texte).
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio. Keep your answers succinct.
{% endif %} Inclure des exemples spécifiques au contexte comme l'aide aux devoirs en cas de besoin.
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %} Le poète invite dépouillera les espaces par défaut pour éviter les nouvelles lignes indésirables dans votre invite finale. Si vous souhaitez inclure un espace explicite, utilisez le marqueur d'espace intégré spécial «<| espace |>» pour assurer un formatage approprié.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
<|space|>{{ username}}: {{ user_query }} La compositionnalité est une résistance centrale des modèles de poète rapides, permettant la création d'invites dynamiques complexes et dynamiques.
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
{% if modality == "audio" %}
- name : special audio instruction
role : system
content : |
{{ username }} is currently using audio modality. Keep your answers succinct and to the point.
{% endif %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}
- name : homework_example_{{ loop.index }}
role : user
content : |
{{ homework_example }}
{% endfor %}
{% endif %}
{% for message in current_chat_messages %}
- name : chat_message
role : user
truncation_priority : 1
content : |
{{ message.author }}: {{ message.content }}
{% endfor %}
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : reply_prompt
role : user
content : |
{{ character_name }}: Pour maintenir les principes secs dans vos modèles, décomposez-les en sections réutilisables qui peuvent être appliquées sur différents modèles, comme lors du test A / B d'une nouvelle invite.
{% include 'sections/system_instruction.yml.j2' %}
{% include 'sections/audio_instruction.yml.j2' %}
{% if extract_user_query_topic(user_query) == "homework_help" %}
{% include 'sections/homework_examples.yml.j2' %}
{% endif %}
{% include 'sections/chat_messages.yml.j2' %}
{% include 'sections/user_query.yml.j2' %}
{% include 'sections/reply_prompt.yml.j2' %}La bibliothèque de poète invite fournit diverses fonctionnalités et paramètres, y compris les propriétés invites. Des caractéristiques clés comme la tokenisation et la troncature d'aide avec une mise en cache efficace et des réponses à faible latence
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
# Inspect prompt as a raw string.
prompt . string : str
> >> "..."
# Inpsect the prompt as raw tokens.
prompt . tokens : list [ int ]
> >> [...]
# Inspect the prompt as LLM API message dicts.
prompt . messages : list [ dict ]
> >> [...]
# Inspect the prompt as first class parts.
prompt . parts : list [ PromptPart ]
> >> [...]Jinja2 et Yaml combinent pour offrir un langage de modèles incroyablement extensible et expressif. Jinja2 facilite les liaisons directes des données, les appels de fonction arbitraires et le flux de contrôle de base dans les modèles. YAML fournit une structure à nos modèles (avec une profondeur = 1) nous permettant d'effectuer une troncature sophistiquée lorsque la limite de jeton est atteinte. Cet appariement de Jinja2 et Yaml n'est pas unique - notamment il est utilisé par ANSIBLE.
Une caractéristique remarquable de Jinja2 est la possibilité d'invoquer des fonctions Python arbitraires directement dans les modèles lors de l'exécution. Cette fonctionnalité est cruciale pour la récupération, la manipulation et la validation des données à la volée, rationalisant comment les invites sont construites. Ici extract_user_query_topic peut effectuer un traitement arbitraire de la requête de l'utilisateur utilisé dans le flux de contrôle du modèle - peut-être en effectuant un aller-retour dans un classificateur de sujet.
{ % if extract_user_query_topic ( user_query ) == "homework_help" % }
{ % for homework_example in fetch_few_shot_homework_examples ( username , character_name ) % }
- name : homework_example_ {{ loop . index }}
role : user
content : |
{{ homework_example }}
{ % endfor % }
{ % endif % } Par défaut, le poète invite utilisera le tokenizer TikToken «O200K_BASE» bien que des noms de codage alternatifs puissent être fournis dans le niveau de haut niveau tiktoken_encoding_name . Alternativement, les utilisateurs peuvent fournir leur propre fonction d'encoder avec le niveau supérieur encode_func: Callable[[str], list[int]] .
from tiktoken import get_encoding
encode_func = get_encoding ( "o200k_base" )
prompt = Prompt (
raw_template = raw_template ,
template_data = template_data ,
encode_func = encode_func
)
prompt . tokenize ()
prompt . tokens
> >> [...]Si votre fournisseur LLM prend en charge l'affinité GPU et le cache de préfixe, utilisez l'algorithme de troncature de caractère. Le taux de cache du préfixe est défini comme le nombre de jetons rapides récupérés à partir du cache sur le nombre total de jetons rapides. Trouvez les valeurs optimales pour l'étape de troncature et la limite de jeton pour votre cas d'utilisation. À mesure que l'étape de troncature augmente, le taux de cache du préfixe augmente également, mais plus de jetons sont tronqués à partir de l'invite.
TOKEN_LIMIT = 128000
TRUNCATION_STEP = 4000
# Tokenize and truncate the prompt.
prompt . tokenize ()
prompt . truncate ( token_limit = TOKEN_LIMIT , truncation_step = TRUNCATION_STEP )
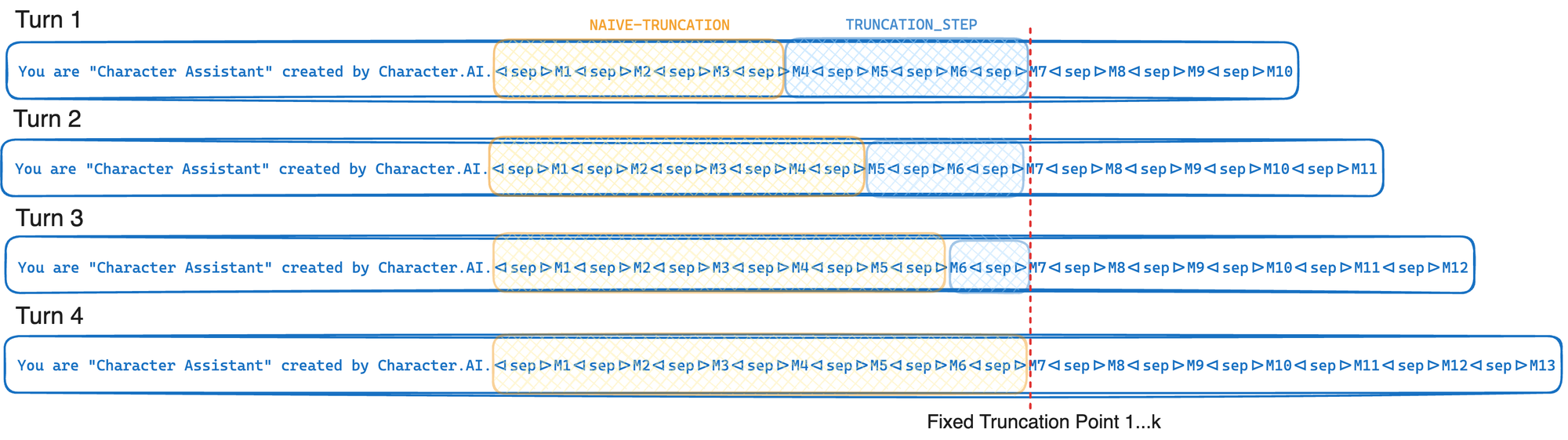
response = model . invoke ( prompt . messages )En bref, la troncature consciente du cache tronque jusqu'à un point de troncature fixe à chaque fois qu'il est invoqué - en déplaçant seulement ce point de troncature en moyenne chaque K tourne. Cela permet à votre fournisseur LLM d'exploiter au maximum le cache de préfixe GPU décrit dans l'optimisation de l'inférence. Si au lieu de cela, nous tronçons simplement jusqu'à atteindre la limite de jeton (L), ce point de troncature se déplacerait à chaque tour qui entraînerait une réduction significative du taux de cache du préfixe. Le compromis dans cette approche est que nous tronçons souvent plus que ce dont nous avons strictement besoin.
Un registre de modèles est simplement le concept de stockage des modèles comme fichiers sur le disque. En utilisant un registre de modèle, vous pouvez isoler des fichiers de modèle à partir de votre code Python et charger ces fichiers directement à partir du disque. Dans les systèmes de production, ces fichiers de modèles peuvent éventuellement être chargés à partir d'un cache en mémoire sur les utilisations successives, économisant sur les E / S de disque. À l'avenir, un registre de modèles pourrait devenir un citoyen de première classe du poète rapide.
Nom de fichier: chat_template.yml.j2
- name : system instructions
role : system
content : |
Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.
- name : user query
role : user
content : |
{{ username}}: {{ user_query }}
- name : response
role : user
content : |
{{ character_name }}: Exécutez ce code Python à partir du même répertoire que vous avez enregistré le fichier chat_template.yml.j2 .
from prompt_poet import Prompt
prompt = Prompt (
template_path = "chat_template.yml.j2" ,
template_data = template_data
)
print ( prompt . string )
> >> 'Your name is Character Assistant and you are meant to be helpful and never harmful to humans.Jeff: Can you help me with my homework?Character Assistant:'

