GSOC project 24 medical
1.0.0
Edge Computing стало чрезвычайно полезным для запуска аналитики на грани, тем самым уменьшая объем данных, отправляемых на серверы и хранилища в ядре или облаке, что, в свою очередь, увеличивает задержку. Проект Analytics Edge Ecosystem Workloads стремится к разработке стратегии цифрового преобразования, сосредоточив внимание на облачной контейнеризации для улучшения бизнес-аналитики.
В этом проекте будут разработаны рабочие нагрузки AI/ML и генеративных AI (Genai) для решения проблем, с которыми сталкиваются в здравоохранении/медицинской промышленности. Разработка этого проекта включает в себя развертывание рабочих нагрузок AI/ML и Genai с открытым исходным кодом, а также развертывания на Kubernetes с использованием ранчо SUSE, с OpenSuse Leap в качестве операционной системы базового уровня. Кроме того, K3S будет использоваться в виде легких Kubernetes, предназначенных для края.
Реализация проекта будет включать несколько технических стеков, таких как DataOps, для управления трубопроводами данных, MLOPS и LLMOP для управления трубопроводами ML и LLM, а также инженерные платформы и ITOPS для управления платформами.
Вертикальная: медицинская/здравоохранение
Многие люди сталкиваются с различными проблемами при работе со своими рецептурными лекарствами. Эти проблемы включают незнакомую медицинскую терминологию, неверно истолкованные рецепты, неясные инструкции по дозировке и использованию, пропущенные сроки срока действия, неожиданные побочные эффекты и лекарственные взаимодействия. Эти проблемы могут привести к передозировке, несчастным случаям и даже смерти.
Этот проект направлен на использование машинного обучения и генеративного ИИ, чтобы помочь решить некоторые проблемы, с которыми сталкиваются пациенты и врачи с медицинскими рецептами. Это будет включать четыре функции, изложенные ниже:
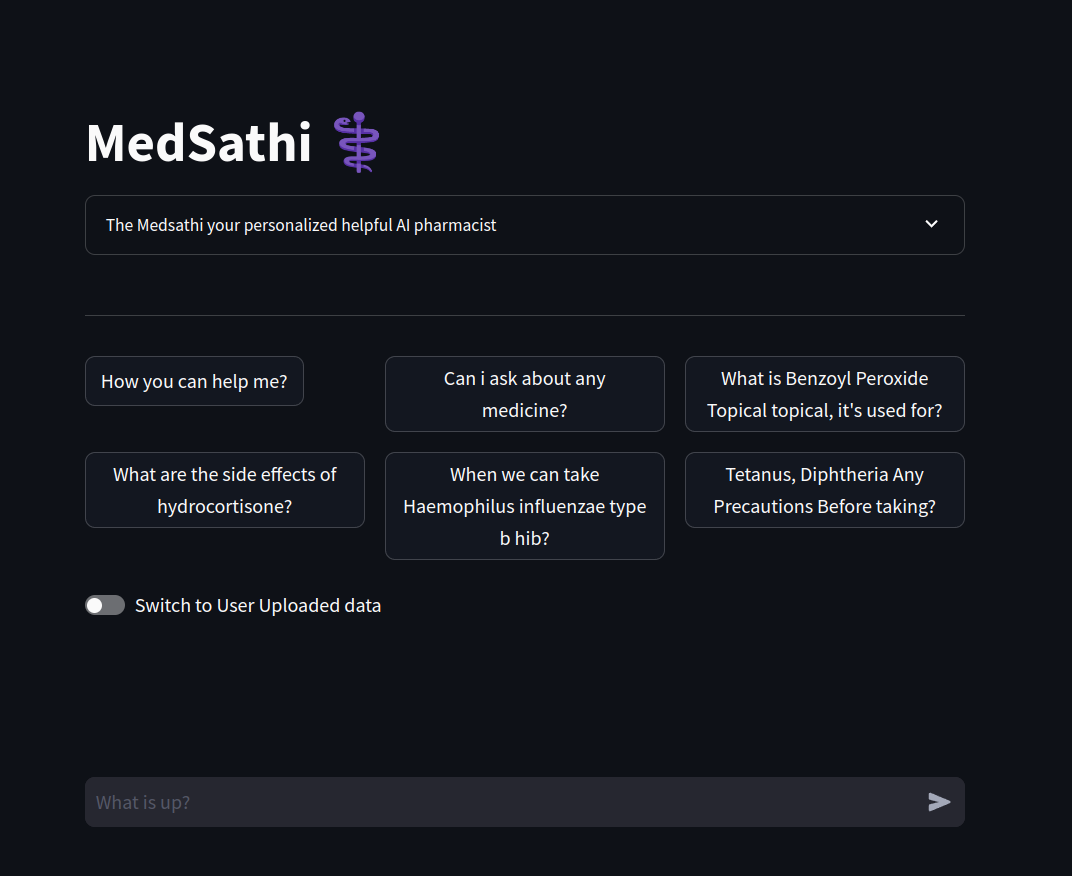
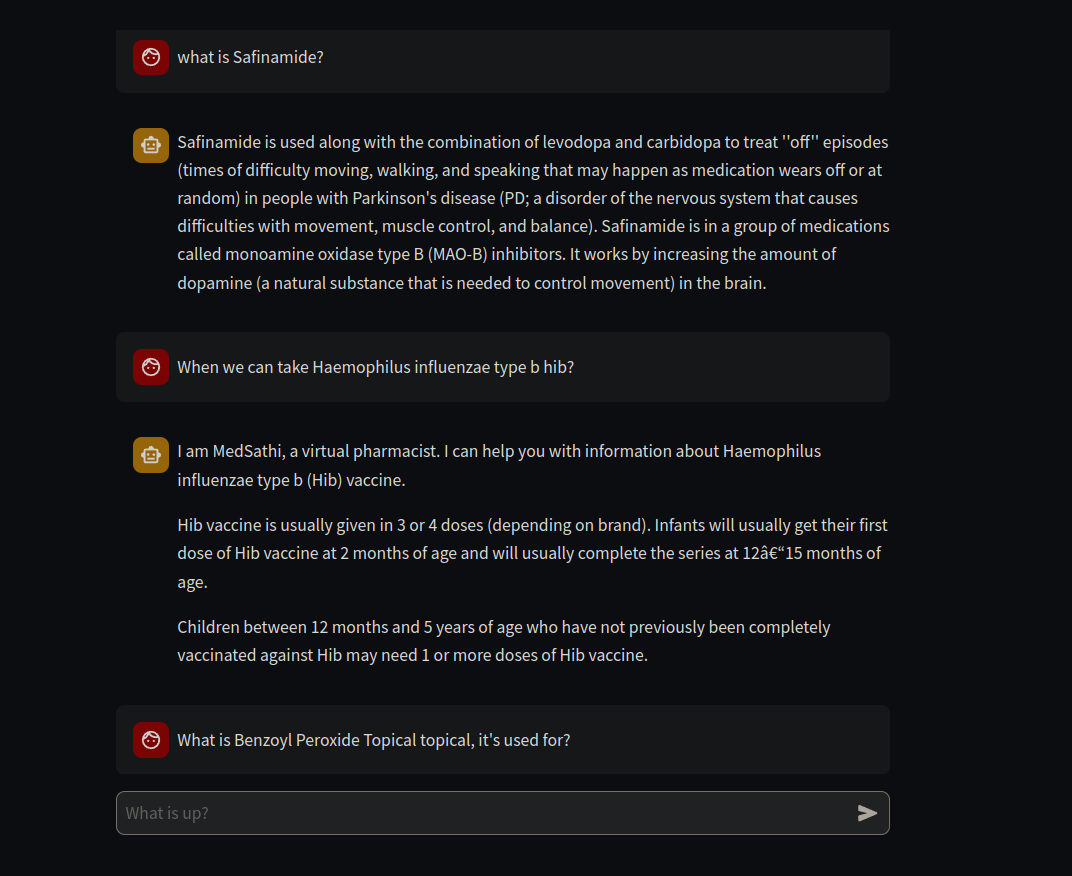
Этот проект охватывает технические стеки Genai, Mlops и Llmops.
git clone https://github.com/yourusername/analytics-edge-ecosystem.git
cd analytics-edge-ecosystem
HUGGINGFACEHUB_API_TOKEN="API key"
PINECONE_API_KEY = "API key"
PINECONE_INDEX = "medcial-rag-chatbot"
GENAI_API_KEY = "Gemini key"
GROQ_API_KEY = "Lama3-7b"
pip install -r requirements.txt
steamlit run app.py
Проект направлен на постоянное улучшение и расширение своих функций. Будущая работа включает в себя:
Если вам нужна поддержка, пожалуйста, откройте проблему в репозитории GitHub.
В этом файле Readme представлен комплексный обзор проекта, включая инструкции по настройке, руководящие принципы взносов, информацию о лицензии, подтверждения, будущие работы, ссылки, часто задаваемые вопросы, кодекс поведения, ChangeLog и данные поддержки. Обязательно обновите заполнителей фактической информацией и ссылками, специфичными для вашего проекта.


