Analytics Edge -Ökosystem -Workloads -Projekt
Abstrakt
Edge Computing ist immens vorteilhaft geworden, um die Analysen am Rande auszuführen, wodurch die Menge der an Server gesendeten Daten und Speicher im Kern oder der Cloud reduziert wird, was wiederum die Latenz erhöht. Das Workload-Projekt Analytics Edge Ecosystem Workloads zielt darauf ab, eine digitale Transformationsstrategie herbeizuführen, indem Sie sich auf Cloud-native Containerisierung konzentrieren, um die Geschäftsanalyse zu verbessern.
In diesem Projekt werden AI/ML und Generative AI (Genai) -Wergungslast entwickelt, um die Herausforderungen in der Gesundheits-/medizinischen Branche zu bewältigen. Die Entwicklung dieses Projekts umfasst die Open-Source-Bereitstellung von AI/ML- und Genai-Workloads sowie Bereitstellungen auf Kubernetes mit Rancher durch SUSE, wobei OpenSuse-Sprung als Basisschichtbetriebssystem. Darüber hinaus wird K3s als leichter Kubernetes verwendet, das für die Kante ausgelegt ist.
Bei der Projektimplementierung werden mehrere technische Stapel wie DatenOPS zur Verwaltung von Datenpipelines, MLOPS und LLMOPS zur Verwaltung von ML- und LLM -Pipelines sowie Plattformtechnik und ITOPs zur Verwaltung von Plattformen verwaltet.
Problemanweisung
Vertikal: Medizin/Gesundheitswesen
Viele Menschen stehen im Umgang mit ihren verschreibungspflichtigen Medikamenten vor verschiedenen Herausforderungen. Zu diesen Herausforderungen gehören unbekannte medizinische Terminologie, falsch interpretierte Rezepte, unklare Dosierungs- und Nutzungsanweisungen, verpasste Verfallsdaten, unerwartete Nebenwirkungen und Wechselwirkungen mit Arzneimitteln. Diese Probleme können zu Überdosierung, Unfällen und sogar zu Tod führen.
Vorgeschlagene Lösung
Dieses Projekt zielt darauf ab, maschinelles Lernen und generative KI zu nutzen, um einige der Herausforderungen zu bewältigen, mit denen Patienten und Ärzte mit medizinischen Rezepten stehen. Dies umfasst die vier unten beschriebenen Funktionen:
- Medizin -Scanner: Scans Medizin, um über die Medizin, die Dosierung, die Nebenwirkungen und das Datum der Ablauf zu informieren.
- Scanner für medizinische Bericht: Scans und vereinfacht Testberichte, um den Patienten zu helfen, ihre medizinischen Berichte zu verstehen.
- Verschreibungspflichtiger Scanner: Scans und interpretiert handgeschriebene Rezepte, um Patienten, Apothekern und anderen Anweisungen eines Arztes ordnungsgemäß zu interpretieren.
- Rezeptgenerator: Ermöglicht Ärzten, schnellere und verständliche Rezepte schneller und einfacher zu erzeugen.
Detaillierte Erklärung
Datenextraktion und Transformation
- Datenquellen: Medizinische Daten aus UCIML -Repositories, Kaggle und anderen vertrauenswürdigen Quellen.
- Datenverarbeitung: Feature Engineering und Datenreinigung werden nach der Extraktion durchgeführt.
- Datenspeicherung: Die Daten werden in Einbettungen konvertiert und in einer Vektordatenbank für die Abruf-Augmented-Generation (RAG) gespeichert.
REMAINAL-AUGENTED-Generation (LAG)
- Modellnutzung: Nutzen Sie Open-Source-Modelle (LLMS), um Lappen zu betreiben.
- Model Feinabstimmung: Feinstimmen Sie das Modell für den Verwendungsfall für Medikamente.
Benutzeroberfläche und LLMOPs
- Benutzeroberfläche: Erstellen Sie eine benutzerfreundliche Oberfläche.
- LLMOPS-Pipeline: Definieren Sie eine End-to-End-LLMOPS-Pipeline, um zusätzliches Training und Feinabstimmung zu ermöglichen.
Benutzerfreundliche Oberfläche
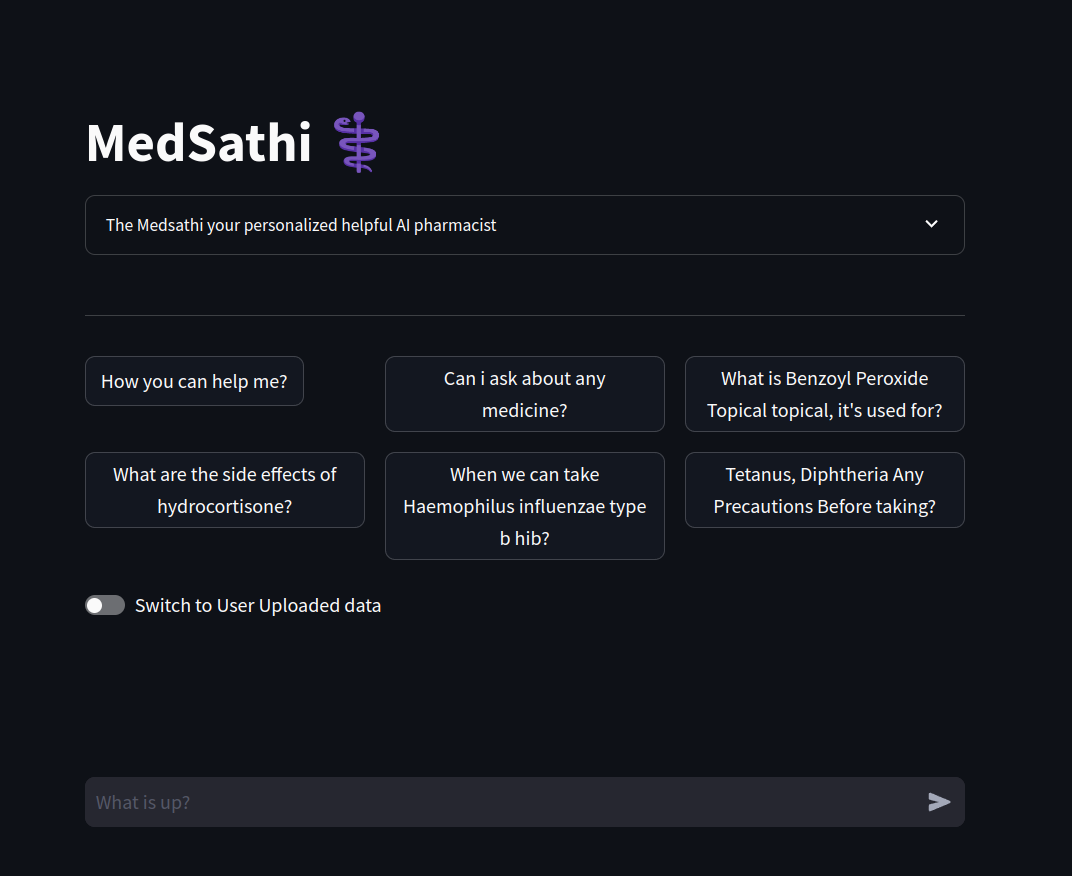
Fragen Sie nach Ihren Medikamenten
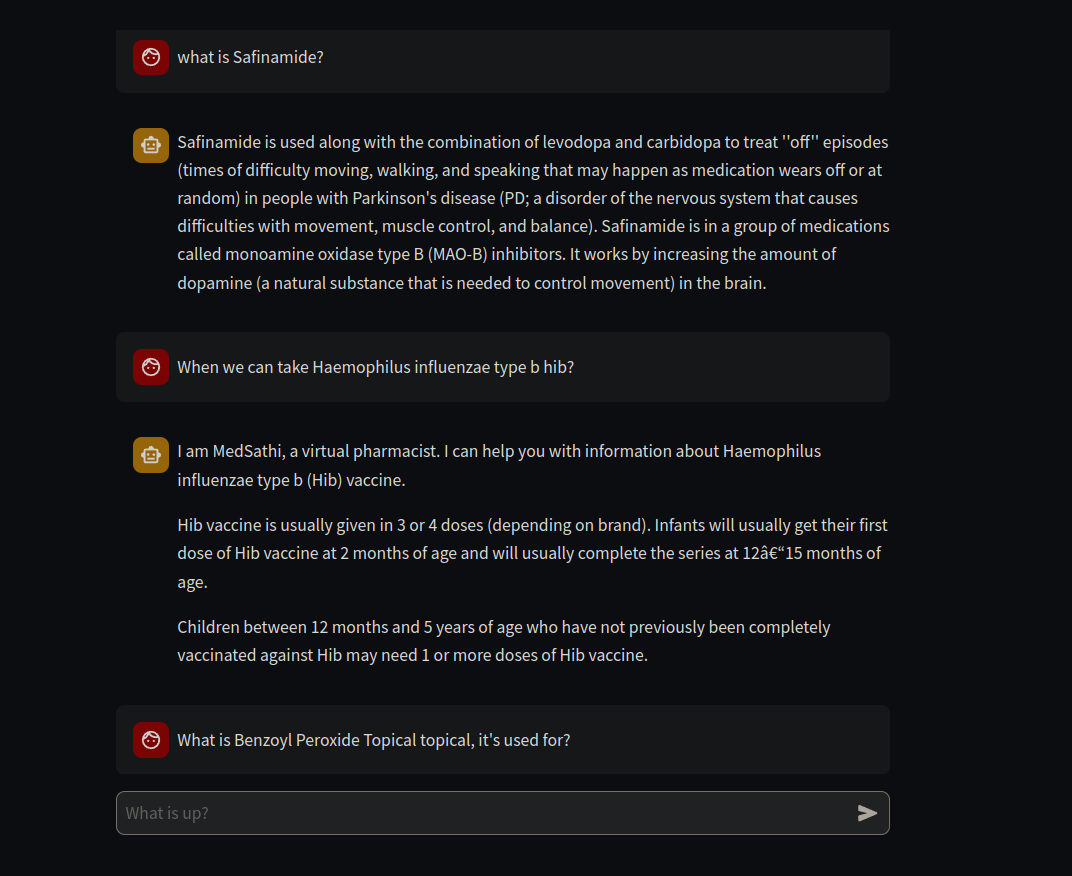
Dieses Projekt umfasst Genai, Mlops und LLMOPS Tech Stacks.
So richten Sie das Projekt ein
- Klonen Sie das Repository:
git clone https://github.com/yourusername/analytics-edge-ecosystem.git
cd analytics-edge-ecosystem
Stellen Sie API -Schlüssel ein
- Setzen Sie alle erforderlichen API -Schlüssel ein
- Erstellen Sie eine .env -Datei
HUGGINGFACEHUB_API_TOKEN="API key"
PINECONE_API_KEY = "API key"
PINECONE_INDEX = "medcial-rag-chatbot"
GENAI_API_KEY = "Gemini key"
GROQ_API_KEY = "Lama3-7b"
Fügen Sie Ihre API -Schlüssel hinzu
Virtuelle Umgebung erstellen
- Installieren Sie alle erforderlichen Pakete
pip install -r requirements.txt
Befehl ausführen
- App.py ausführen
Anerkennung
- Vielen Dank an die Open-Source-Community für die Bereitstellung verschiedener Tools und Frameworks.
- Besonderer Dank geht an UCIML, Kaggle und andere vertrauenswürdige Quellen für die Bereitstellung der Datensätze.
- Dankbarkeit von SUSE, OpenSuse Leap und Rancher für ihre leistungsstarken Tools, die Kubernetes -Bereitstellungen ermöglichen.
Zukünftige Arbeit
Das Projekt zielt darauf ab, seine Funktionen kontinuierlich zu verbessern und zu erweitern. Zukünftige Arbeiten umfassen:
- Verbessertes Modelltraining: Verbesserung der Genauigkeit und Effizienz von KI/ML -Modellen kontinuierlich.
- Integration mit mehr Datenquellen: Erweitern Sie die Datenquellen um umfassendere und vielfältigere medizinische Daten.
- Benutzer -Feedback -Mechanismus: Implementieren Sie ein Feedback -System für Benutzer, um Probleme zu melden und Verbesserungen vorzuschlagen.
- Mobile Anwendung: Entwickeln Sie eine mobile Anwendung, um die Lösung für Patienten und Gesundheitsdienstleister zugänglicher zu machen.
Datenquellen
- Staatliche medizinische Datenquelle
- Medizinische Daten Gov Quelle -> Lizenziert erforderlich
- Medizinische Enzyklopädie
- Journallisten
[Schritte]
- Erstes Projektaufbau
- Implementierung des Medizin -Scanners, des medizinischen Berichts Scanner, des verschreibungspflichtigen Scanners und des verschreibungspflichtigen Generators
- Bereitstellung auf Kubernetes mit Rancher und K3s
- Entwicklung von LLMOPS -Pipelines
[1.0.0]-JJJJ-MM-DD
Autoren
- Aman Kumar - Erste Arbeit
Unterstützung
Wenn Sie Unterstützung benötigen, öffnen Sie bitte ein Problem im Github -Repository.
Diese Readme -Datei bietet einen umfassenden Überblick über das Projekt, einschließlich Einrichtungsanweisungen, Beitragsrichtlinien, Lizenzinformationen, Bestätigungen, zukünftigen Arbeiten, Referenzen, FAQs, Verhaltenskodex, Changelog und Support -Details. Stellen Sie sicher, dass Sie die Platzhalter mit tatsächlichen Informationen und Links für Ihr Projekt aktualisieren.


