Proyecto de cargas de trabajo del ecosistema de Analytics Edge
Abstracto
La computación de borde se ha vuelto inmensamente beneficiosa para ejecutar análisis en el borde, reduciendo así la cantidad de datos enviados a servidores y almacenamiento en el núcleo o nube, lo que a su vez aumenta la latencia. El proyecto de cargas de trabajo del ecosistema de Analytics Edge tiene como objetivo lograr una estrategia de transformación digital centrándose en la contenedores nativos de la nube para mejorar el análisis comercial.
En este proyecto, se desarrollarán AI/ML y cargas de trabajo generativas de IA (Genai) para abordar los desafíos que enfrentan en la industria médica/salud. El desarrollo de este proyecto incluye la implementación de código abierto de cargas de trabajo AI/ML y Genai, así como implementaciones en Kubernetes utilizando Rancher by SUSE, con OpenSUSE Leap como el sistema operativo de la capa base. Además, los K3 se utilizarán como Kubernetes livianos diseñados para el borde.
La implementación del proyecto involucrará varias pilas tecnológicas, como DataPS para administrar tuberías de datos, MLOPS y LLMOPS para administrar tuberías de ML y LLM, así como la ingeniería de plataformas e ITOP para administrar plataformas.
Declaración del problema
Vertical: médico/atención médica
Muchas personas enfrentan varios desafíos al tratar con sus medicamentos recetados. Estos desafíos incluyen terminología médica desconocida, recetas malinterpretadas, dosis poco claras y instrucciones de uso, fechas de vencimiento perdidas, efectos secundarios inesperados e interacciones de drogas. Estos problemas pueden conducir a una sobredosis, accidentes e incluso a la muerte.
Solución propuesta
Este proyecto tiene como objetivo aprovechar el aprendizaje automático y la IA generativa para ayudar a abordar algunos de los desafíos que enfrentan los pacientes y los médicos con recetas médicas. Esto implicará las cuatro características descritas a continuación:
- Escáner de medicina: escanea la medicina para informar sobre la medicina, la dosis, los efectos secundarios y la fecha de vencimiento.
- Escáner de informes médicos: escanea y simplifica los informes de las pruebas para ayudar a los pacientes a comprender sus informes médicos.
- Escáner de receta: escaneos e interpreta recetas escritas a mano para ayudar a pacientes, farmacéuticos y otros a interpretar adecuadamente las instrucciones de un médico.
- Generador de recetas: permite a los médicos generar recetas precisas y comprensibles de manera más rápida y fácil.
Explicación detallada
Extracción y transformación de datos
- Fuentes de datos: datos médicos de repositorios de UCIML, Kaggle y otras fuentes confiables.
- Procesamiento de datos: la ingeniería de funciones y la limpieza de datos se realizarán después de la extracción.
- Almacenamiento de datos: los datos se convertirán en incrustaciones y se almacenarán en una base de datos vectorial para la generación de recuperación acuática (RAG).
Generación de recuperación de generación (trapo)
- Utilización del modelo: aproveche los modelos de lenguaje grande (LLMS) de código abierto al trapo de alimentación.
- Modelo ajustado: ajuste el modelo para el caso de uso de medicamentos.
Interfaz de usuario y LLMOPS
- Interfaz de usuario: cree una interfaz fácil de usar.
- LLMOPS Pipeline: Defina una tubería LLMOPS de extremo a extremo para permitir capacitación adicional y ajuste fino.
Interfaz fácil de usar
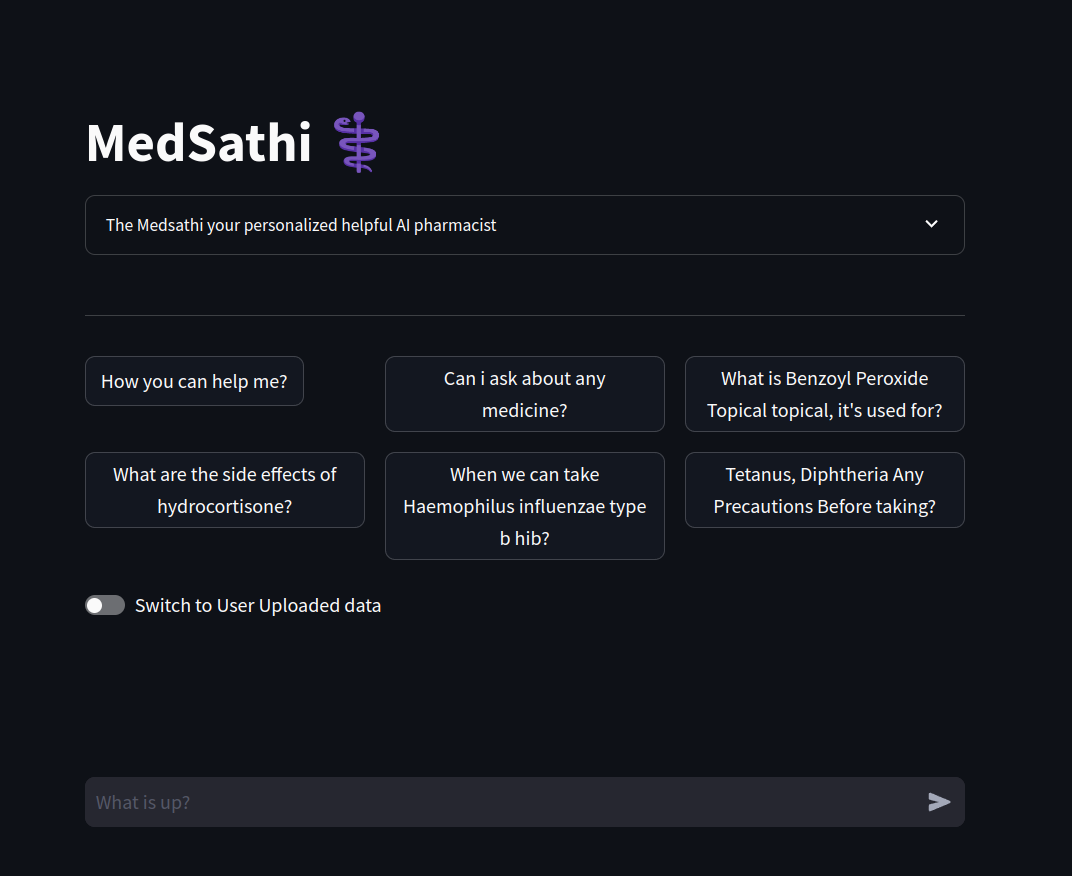
Pregunte por sus medicamentos
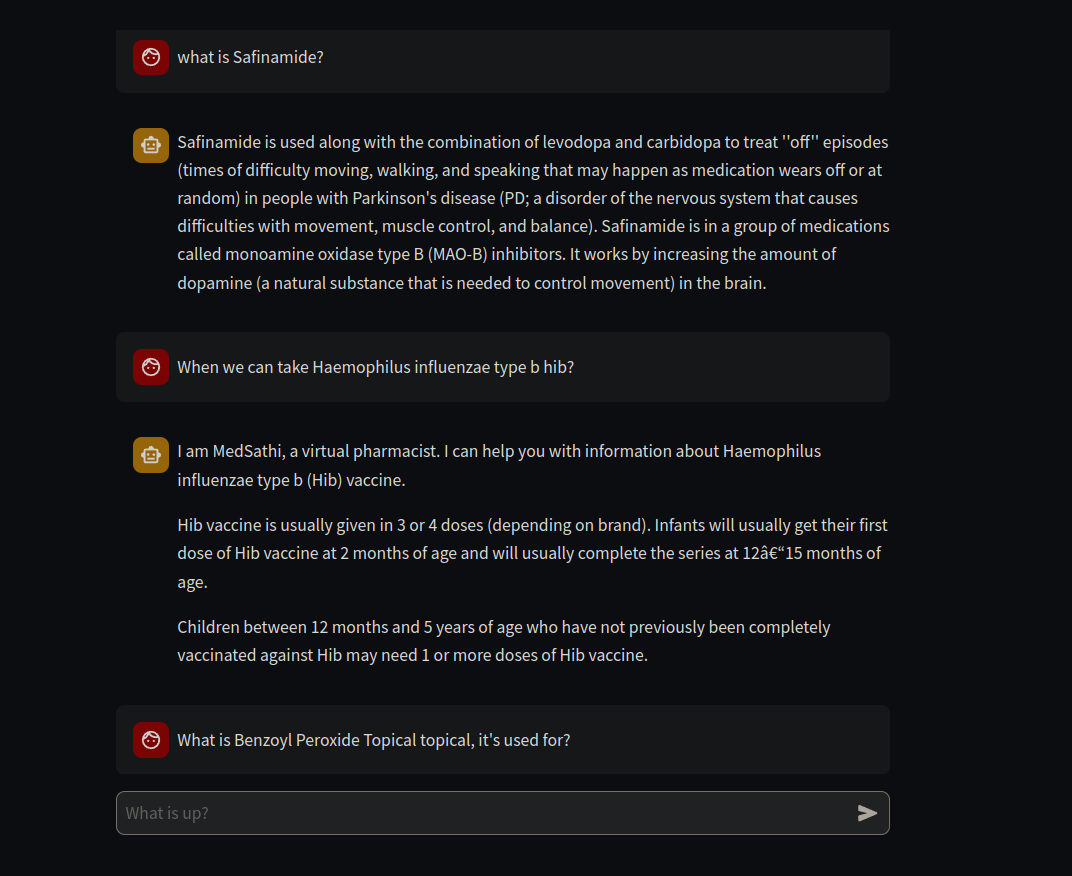
Este proyecto abarca las pilas Tech Genai, MLOPS y LLMOPS.
Cómo configurar el proyecto
- Clon el repositorio:
git clone https://github.com/yourusername/analytics-edge-ecosystem.git
cd analytics-edge-ecosystem
Establecer teclas API
- Configurar todas las teclas API requeridas
HUGGINGFACEHUB_API_TOKEN="API key"
PINECONE_API_KEY = "API key"
PINECONE_INDEX = "medcial-rag-chatbot"
GENAI_API_KEY = "Gemini key"
GROQ_API_KEY = "Lama3-7b"
Agrega tus teclas API
Crear entorno virtual
- Instale todos los paquetes requeridos
pip install -r requirements.txt
Ejecutar comando
- Ejecutar App.py
Expresiones de gratitud
- Gracias a la comunidad de código abierto por proporcionar diversas herramientas y marcos.
- Un agradecimiento especial a UCIML, Kaggle y otras fuentes de confianza por proporcionar los conjuntos de datos.
- Gratitud a Suse, OpenSuse Leap y Rancher por sus poderosas herramientas que permiten implementaciones de Kubernetes.
Trabajo futuro
El proyecto tiene como objetivo mejorar y expandir continuamente sus características. El trabajo futuro incluye:
- Entrenamiento de modelos mejorados: mejorar continuamente la precisión y la eficiencia de los modelos AI/ML.
- Integración con más fuentes de datos: Expanda las fuentes de datos para incluir datos médicos más completos y diversos.
- Mecanismo de retroalimentación del usuario: Implemente un sistema de comentarios para que los usuarios informen problemas y sugieran mejoras.
- Aplicación móvil: desarrolle una aplicación móvil para que la solución sea más accesible para pacientes y proveedores de atención médica.
Fuentes de datos
- Fuente de datos médicos del gobierno
- Fuente del gobierno de datos médicos avanzados -> Licenciado requerido
- Enciclopedia médica
- Listas de revistas
[Pasos]
- Configuración inicial del proyecto
- Implementación del escáner de medicina, escáner de informes médicos, escáner de recetas y generador de prescripción
- Despliegue en Kubernetes usando Rancher y K3s
- Desarrollo de tuberías de LLMOPS
[1.0.0]-aaa yyy-mm-dd
Autores
- Aman Kumar - Trabajo inicial
Apoyo
Si necesita soporte, abra un problema en el repositorio de GitHub.
Este archivo README proporciona una descripción completa del proyecto, incluidas las instrucciones de configuración, las pautas de contribución, la información de la licencia, los reconocimientos, el trabajo futuro, las referencias, las preguntas frecuentes, el código de conducta, el cambio de cambios y los detalles de soporte. Asegúrese de actualizar a los marcadores de posición con información y enlaces reales específicos de su proyecto.


