Analytics Edge Ecossystem Workloads Project
Resumo
A computação de borda tornou -se imensamente benéfica para a execução de análises no limite, reduzindo assim a quantidade de dados enviados para servidores e armazenamento no núcleo ou na nuvem, o que, por sua vez, aumenta a latência. O projeto do Analytics Edge EcoSystem Work Carcoads pretende provocar uma estratégia de transformação digital, concentrando-se na contêinerização nativa em nuvem para melhorar a análise de negócios.
Neste projeto, a IA/ML e as cargas de trabalho generativas da IA (GENAI) serão desenvolvidas para enfrentar os desafios enfrentados no setor de saúde/médico. O desenvolvimento deste projeto inclui a implantação de código aberto das cargas de trabalho de IA/ML e Genai, bem como implantações em Kubernetes usando o Rancher by SUSE, com o OpenSuse Leap como o sistema operacional da camada base. Além disso, os K3s serão utilizados como um Kubernetes leves projetados para a borda.
A implementação do projeto envolverá várias pilhas de tecnologia, como o DataOps, para gerenciar pipelines de dados, MLOPs e LLMOPs para gerenciar pipelines ML e LLM, bem como engenharia de plataforma e ITOPs para gerenciar plataformas.
Declaração de problemas
Vertical: Medical/Healthcare
Muitas pessoas enfrentam vários desafios ao lidar com seus medicamentos prescritos. Esses desafios incluem terminologia médica desconhecida, prescrições mal interpretadas, dosagem pouco claras e instruções de uso, datas de validade perdidas, efeitos colaterais inesperados e interações medicamentosas. Essas questões podem levar a overdose, acidentes e até morte.
Solução proposta
Este projeto tem como objetivo aproveitar o aprendizado de máquina e a IA generativa para ajudar a enfrentar alguns dos desafios que pacientes e médicos enfrentam com prescrições médicas. Isso envolverá os quatro recursos descritos abaixo:
- Scanner de medicina: digitaliza medicina para informar sobre o medicamento, dosagem, efeitos colaterais e data de expiração.
- Scanner de relatórios médicos: digitaliza e simplifica os relatórios de teste para ajudar os pacientes a entender seus relatórios médicos.
- Scanner de prescrição: digitaliza e interpreta prescrições manuscritas para ajudar pacientes, farmacêuticos e outros a interpretar adequadamente as instruções de um médico.
- Gerador de prescrição: permite que os médicos gerem mais rápida e facilmente prescrições precisas e compreensíveis.
Explicação detalhada
Extração e transformação de dados
- Fontes de dados: dados médicos de repositórios UCIML, Kaggle e outras fontes confiáveis.
- Processamento de dados: a engenharia de recursos e a limpeza de dados serão realizados após a extração.
- Armazenamento de dados: os dados serão convertidos em incorporação e armazenados em um banco de dados vetorial para geração de recuperação com agente de recuperação (RAG).
Geração de recuperação usededed (RAG)
- Utilização de modelos: Aproveite os modelos de linguagem grande de código aberto (LLMS) ao Power Rag.
- Modelo Tuneamento fino: ajuste o modelo para o caso de uso de medicamentos.
Interface do usuário e LLMOPs
- Interface do usuário: crie uma interface amigável.
- LLMOPS Pipeline: Defina um pipeline de ponta a ponta LLMOPs para permitir treinamento e ajuste fino adicionais.
Interface amigável de uso
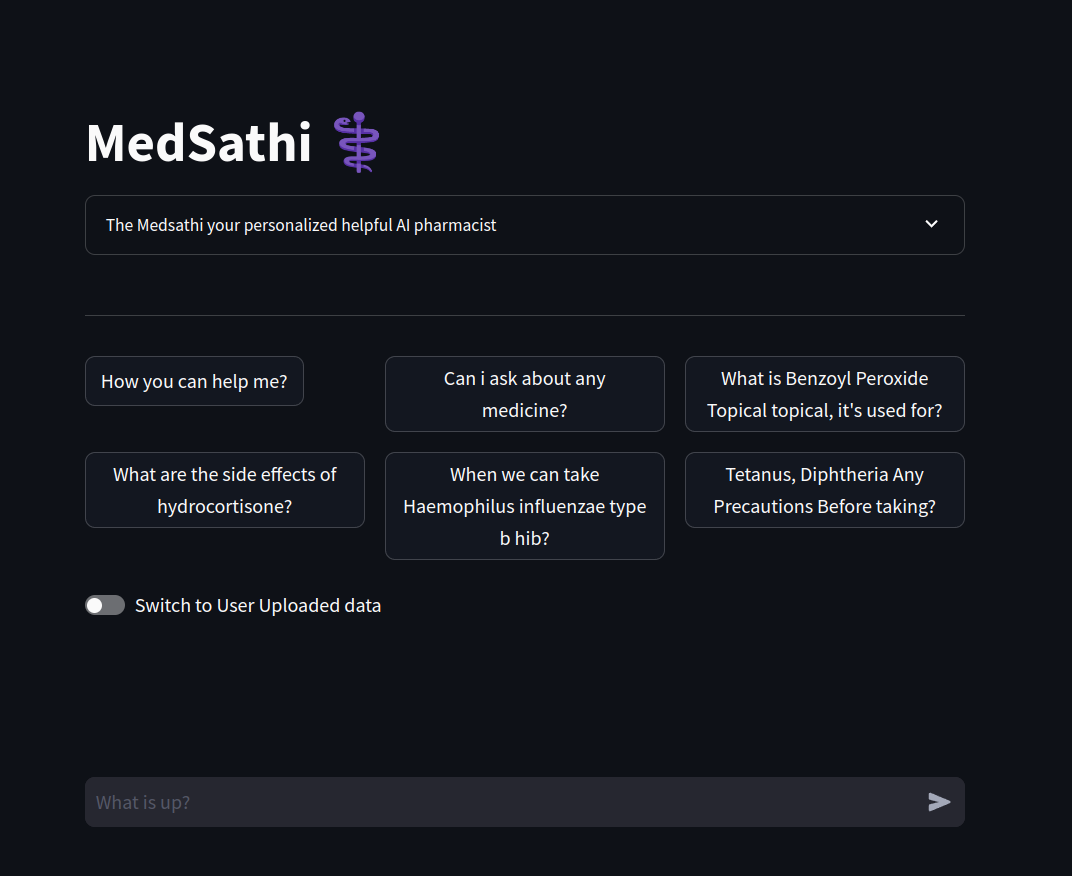
Pergunte sobre seus medicamentos
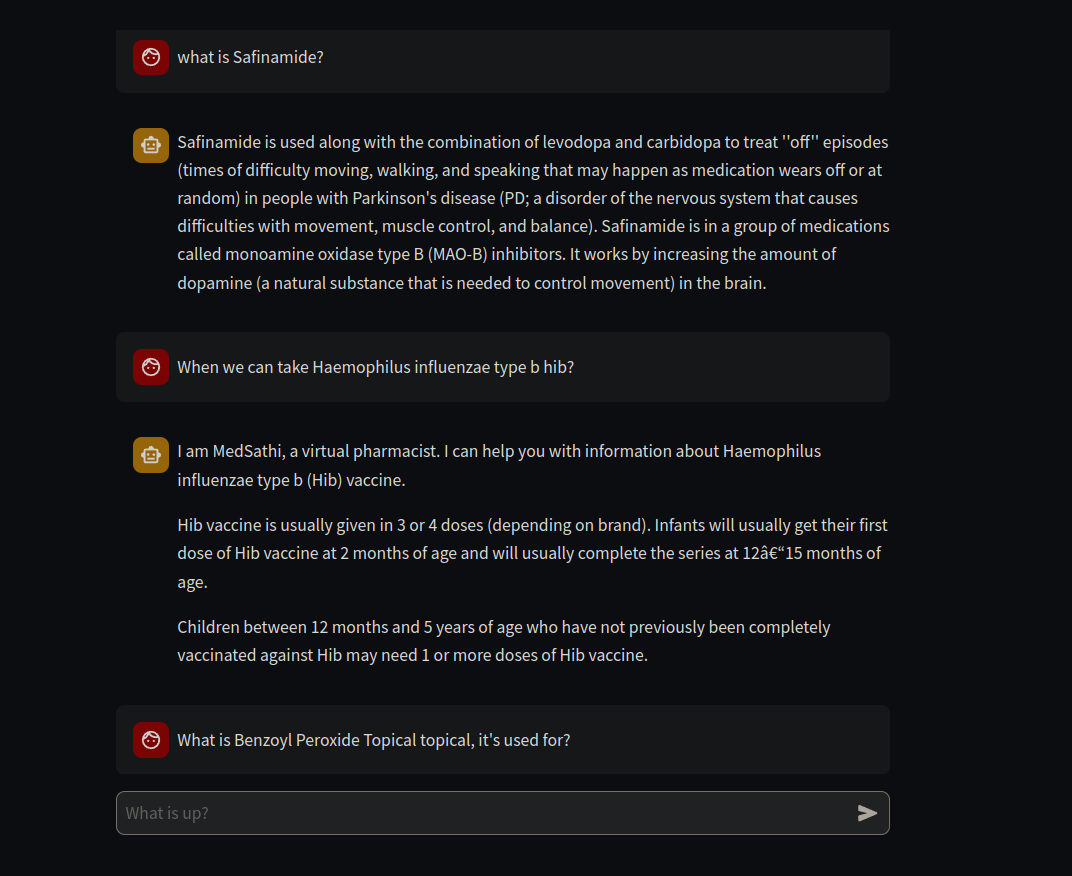
Este projeto abrange pilhas de tecnologia Genai, Mlops e LLMOPs.
Como configurar o projeto
- Clone o repositório:
git clone https://github.com/yourusername/analytics-edge-ecosystem.git
cd analytics-edge-ecosystem
Defina as chaves da API
- Definindo todas as teclas de API necessárias
HUGGINGFACEHUB_API_TOKEN="API key"
PINECONE_API_KEY = "API key"
PINECONE_INDEX = "medcial-rag-chatbot"
GENAI_API_KEY = "Gemini key"
GROQ_API_KEY = "Lama3-7b"
Adicione suas chaves da API
Crie ambiente virtual
- Instale todos os pacotes necessários
pip install -r requirements.txt
Executar comando
- Execute app.py
Agradecimentos
- Graças à comunidade de código aberto por fornecer várias ferramentas e estruturas.
- Agradecimentos especiais ao UCIML, Kaggle e outras fontes confiáveis por fornecer os conjuntos de dados.
- Gratidão ao SUSE, OpenSuse Leap e Rancher por suas poderosas ferramentas que permitem implantações de Kubernetes.
Trabalho futuro
O projeto visa melhorar e expandir continuamente seus recursos. Trabalho futuro inclui:
- Treinamento de modelo aprimorado: melhore continuamente a precisão e a eficiência dos modelos AI/ML.
- Integração com mais fontes de dados: expanda as fontes de dados para incluir dados médicos mais abrangentes e diversos.
- Mecanismo de feedback do usuário: implemente um sistema de feedback para os usuários relatarem problemas e sugerir melhorias.
- Aplicativo móvel: desenvolva um aplicativo móvel para tornar a solução mais acessível a pacientes e prestadores de serviços de saúde.
Fontes de dados
- Fonte de dados médicos do governo
- Avanço de dados médicos do Gov Fonte -> Licenciado necessário
- Enciclopédia médica
- Listas de periódicos
[Passos]
- Configuração inicial do projeto
- Implementação de scanner de medicina, scanner de relatório médico, scanner de prescrição e gerador de prescrição
- Implantação em Kubernetes usando Rancher e K3s
- Desenvolvimento de Pipelines LLMops
[1.0.0]-AAAA-MM-DD
Autores
- Aman Kumar - trabalho inicial
Apoiar
Se você precisar de suporte, abra um problema no repositório do GitHub.
Este arquivo ReadMe fornece uma visão geral abrangente do projeto, incluindo instruções de configuração, diretrizes de contribuição, informações de licença, reconhecimentos, trabalho futuro, referências, perguntas frequentes, Código de Conduta, Changelog e detalhes de suporte. Certifique -se de atualizar os espaços reservados com informações e links reais específicos para o seu projeto.


