DOCCHAT: Langchain Systeval System
Это приложение Streamlit реализует систему поиска на основе Langchain для обработки документов PDF и проведения разговорного поиска с использованием возможностей Langchain.
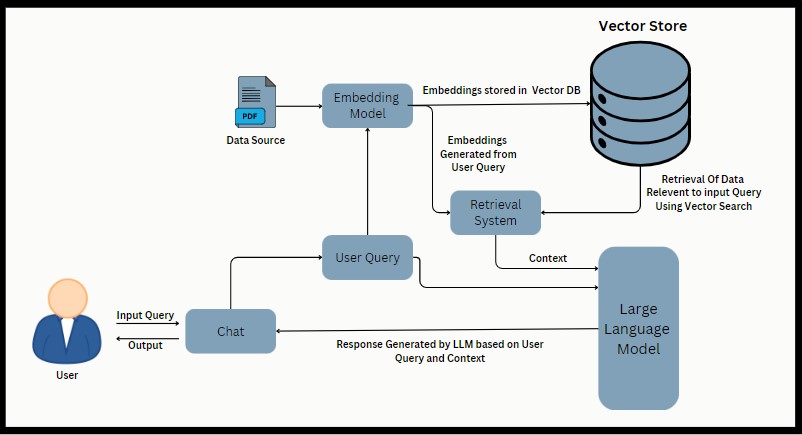
Тряпичная архитектура
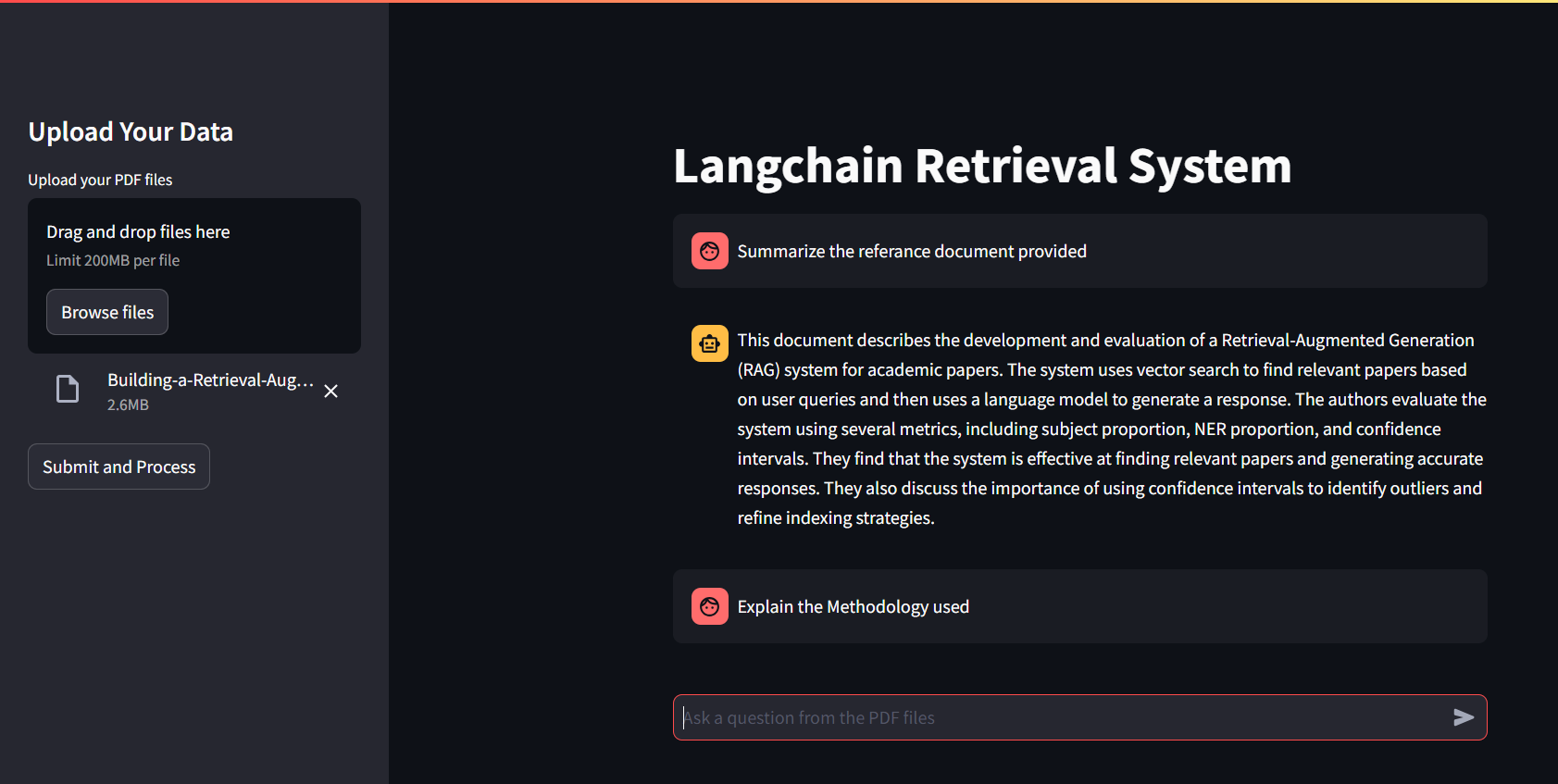
Streamlit ui
Обзор
Приложение позволяет пользователям загружать PDF -файлы, извлекать текст, разделять его на куски, генерировать встраивания с использованием Google Palm Enterdings и создавать разговорную цепочку поиска. Затем пользователи могут задавать вопросы, связанные с обработанным содержанием PDF, и получать ответы на основе настройки разговорной цепочки.
Ключевые технологии используются
- Langchain : библиотека для задач обработки естественного языка, включая расщепление текста и поиск разговоров.
- Google Palm Enterdings : Entgdings, используемые для семантического сходства и текстового представления.
- Faiss (Facebook AI Searnity Search) : эффективная библиотека для поиска сходства и кластеризации плотных векторов.
Настройка проекта
Предварительные условия
Среда Python : убедитесь, что у вас установлен Python 3.x.
Переменные среды : Создайте файл .env в каталоге Project Root со следующим контентом: Google_api_key = your_google_api_key_here Заменить your_google_api_key_here с вашим фактическим ключом Google API.
Установка
- Клонировать репозиторий : клонировать этот репозиторий к местной машине:
git clone https://github.com/Varunv003/langchain-palm2-rag_application
- Настройте виртуальную среду : рекомендуется использовать виртуальную среду для управления зависимостями:
python -m venv venv
# On Windows: .venvScriptsactivate
# On macOS/Linux: source venv/bin/activate
- Установите зависимости : установите необходимые пакеты Python с помощью PIP:
pip install -r requirements.txt
- Структура шаблона : чтобы настроить начальную структуру папок проекта, запустите:
python template.py
# This command will create necessary directories and files based on your project needs.
- Запуск приложения для запуска приложения Streamlit:
streamlit run app.py
# The application will start, and you can access it in your web browser at http://localhost:8501.
Структура файла
- app.py : основной код приложения для загрузки PDF -файлов, их обработка и управление взаимодействиями пользователей.
- helper.py : содержит вспомогательные функции для извлечения текста PDF, текстового кунгинга, создания векторного хранилища Faiss и настройки разговорной цепи.
- Template.py : скрипт для инициализации структуры папок и создания необходимых каталогов/файлов для проекта. .env: Файл переменной среды для хранения конфиденциальных данных, таких как клавиши API.
Использование
- Загрузите PDF -файлы: используйте боковую панель «Загрузить свои данные» для загрузки одного или нескольких файлов PDF.
- Process PDFS: нажмите «Отправить и обрабатывать», чтобы извлечь текст, генерировать вставки и настроить разговорную цепочку поиска.
- Задайте вопросы: введите вопросы, связанные с загруженным содержанием PDF в поле Text Input.
- Ответы на просмотр: ответы, сгенерированные разговорной моделью Langchain, будут отображаться в основном интерфейсе.
- Регистрация: регистрация реализована для захвата ключевых шагов и времен во время извлечения текста PDF, текстового кунгинга, создания векторного хранилища и настройки разговорной цепи. Журналы отображаются в консоли или терминале, где запускается приложение.
Будущие улучшения
- Увеличить обработку ошибок и отзывы пользователей во время загрузки и обработки файлов.
- Улучшение масштабируемости и оптимизации производительности для обработки больших документов PDF.
- Интегрируйте дополнительные модели ИИ или уточните существующие модели для лучших разговорных ответов.


