Docchat: sistema de recuperación de Langchain
Esta aplicación aerodinámica implementa un sistema de recuperación basado en Langchain para procesar documentos PDF y realizar recuperación de conversación utilizando las capacidades de Langchain.
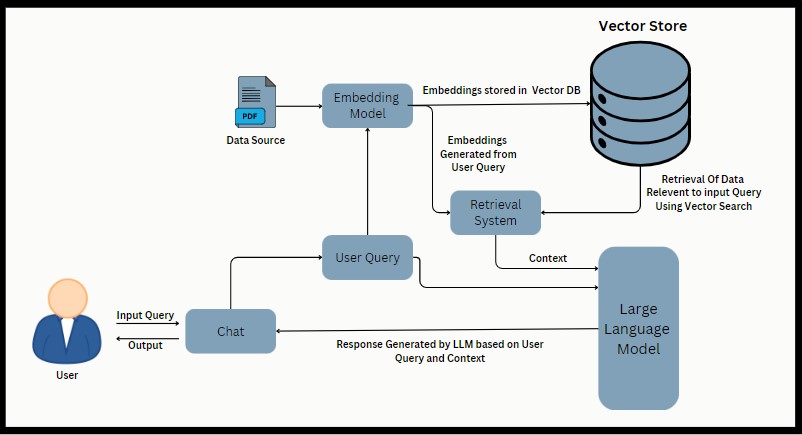
Arquitectura de trapo
UI aerodinámica
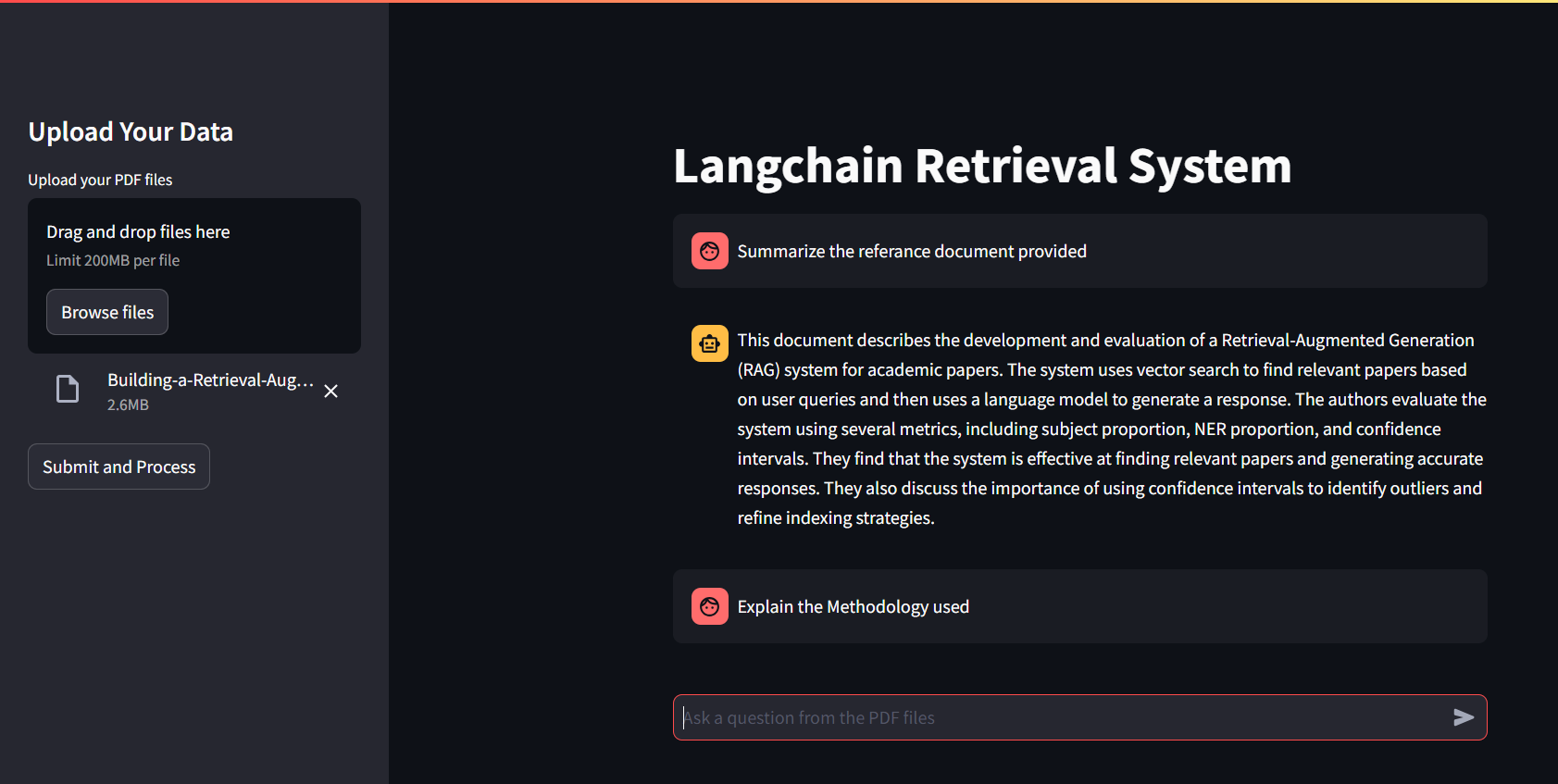
Descripción general
La aplicación permite a los usuarios cargar archivos PDF, extraer texto, dividirlo en trozos, generar embedidas utilizando Google Palm Increddings y crear una cadena de recuperación de conversación. Los usuarios pueden hacer preguntas relacionadas con el contenido de PDF procesado y recibir respuestas basadas en la configuración de la cadena de conversación.
Tecnologías clave utilizadas
- Langchain : una biblioteca para tareas de procesamiento del lenguaje natural, incluida la división de texto y la recuperación de la conversación.
- INCURSOS DE LA PALM DE LA PALM : Incrustos utilizados para la similitud semántica y la representación del texto.
- FAISS (Facebook AI Simility Search) : una biblioteca eficiente para la búsqueda de similitud y la agrupación de vectores densos.
Configuración del proyecto
Requisitos previos
Entorno de Python : asegúrese de tener instalado Python 3.x.
Variables de entorno : cree un archivo .env en el directorio raíz del proyecto con el siguiente contenido: Google_api_key = Your_Google_api_Key_here Reemplace your_google_api_key_here con su tecla API de Google real.
Instalación
- Clone El repositorio : Clone este repositorio a su máquina local:
git clone https://github.com/Varunv003/langchain-palm2-rag_application
- Configurar el entorno virtual : se recomienda utilizar un entorno virtual para administrar las dependencias:
python -m venv venv
# On Windows: .venvScriptsactivate
# On macOS/Linux: source venv/bin/activate
- Instalación de dependencias : Instale los paquetes de Python requeridos con PIP:
pip install -r requirements.txt
- Estructura de plantilla : para configurar la estructura de carpeta inicial del proyecto, ejecute:
python template.py
# This command will create necessary directories and files based on your project needs.
- Ejecutando la aplicación para ejecutar la aplicación Streamlit:
streamlit run app.py
# The application will start, and you can access it in your web browser at http://localhost:8501.
Estructura de archivo
- App.py : Código de aplicación de optimización principal para cargar PDFS, procesarlos y administrar las interacciones del usuario.
- Helper.py : contiene funciones auxiliar para extracción de texto PDF, fragmentación de texto, creación de tiendas vectoriales Faiss y configuración de la cadena de conversación.
- Template.py : script para inicializar la estructura de la carpeta y crear directorios/archivos necesarios para el proyecto. .env: archivo variable de entorno para almacenar datos confidenciales como claves API.
Uso
- Cargue archivos PDF: use la barra lateral "Cargar sus datos" para cargar uno o más archivos PDF.
- Procesar PDFS: haga clic en "Enviar y procesar" para extraer texto, generar integridades y configurar una cadena de recuperación de conversación.
- Haga preguntas: Ingrese preguntas relacionadas con el contenido de PDF cargado en el campo de entrada de texto.
- Ver respuestas: las respuestas generadas por el modelo de conversación Langchain se mostrarán en la interfaz principal.
- Registro: el registro se implementa para capturar pasos y horarios clave durante la extracción de texto en PDF, fragmentación de texto, creación de tiendas vectoriales y configuración de la cadena de conversación. Los registros se muestran en la consola o terminal donde se ejecuta la aplicación.
Mejoras futuras
- Mejorar el manejo de errores y la retroalimentación del usuario durante la carga y el procesamiento del archivo.
- Mejorar la escalabilidad y las optimizaciones de rendimiento para manejar documentos PDF más grandes.
- Integre modelos de IA adicionales o refine los modelos existentes para obtener mejores respuestas de conversación.


