Docchat: Système de récupération de Langchain
Cette application rationalisée implémente un système de récupération basé sur Langchain pour le traitement des documents PDF et la réalisation de la récupération conversationnelle à l'aide des capacités de Langchain.
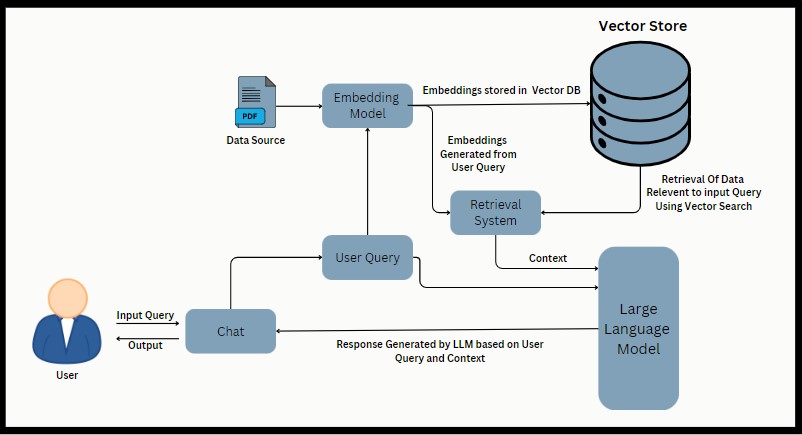
Architecture de chiffon
Ui rationalisée
Aperçu
L'application permet aux utilisateurs de télécharger des fichiers PDF, d'extraire du texte, de le diviser en morceaux, de générer des intégres à l'aide de Google Palm Embeddings et de créer une chaîne de récupération conversationnelle. Les utilisateurs peuvent ensuite poser des questions liées au contenu PDF traité et recevoir des réponses en fonction de la configuration de la chaîne conversationnelle.
Technologies clés utilisées
- Langchain : une bibliothèque pour les tâches de traitement du langage naturel, y compris la division de texte et la récupération conversationnelle.
- Google Palm Embeddings : intégres utilisés pour la similitude sémantique et la représentation du texte.
- FAISS (Facebook AI Search Search) : une bibliothèque efficace pour la recherche de similitude et le regroupement de vecteurs denses.
Configuration du projet
Condition préalable
Environnement Python : assurez-vous que Python 3.x installe.
Variables d'environnement : créez un fichier .env dans le répertoire racine du projet avec le contenu suivant: google_api_key = votre_google_api_key_here remplacez your_google_api_key_here par votre clé API Google réelle.
Installation
- Clone le référentiel : clone ce référentiel à votre machine locale:
git clone https://github.com/Varunv003/langchain-palm2-rag_application
- Configurer un environnement virtuel : il est recommandé d'utiliser un environnement virtuel pour gérer les dépendances:
python -m venv venv
# On Windows: .venvScriptsactivate
# On macOS/Linux: source venv/bin/activate
- Installez les dépendances : installez les packages Python requis à l'aide de PIP:
pip install -r requirements.txt
- Structure du modèle : pour configurer la structure du dossier initial du projet, exécutez:
python template.py
# This command will create necessary directories and files based on your project needs.
- Exécution de l'application pour exécuter l'application Streamlit:
streamlit run app.py
# The application will start, and you can access it in your web browser at http://localhost:8501.
Structure de fichiers
- app.py : le code d'application principal principal pour télécharger les PDF, les traiter et la gestion des interactions utilisateur.
- Helper.py : contient des fonctions d'assistance pour l'extraction de texte PDF, la chasse au texte, la création de magasin vectoriel FAISS et la configuration de la chaîne conversationnelle.
- template.py : script pour initialiser la structure du dossier et créer les répertoires / fichiers nécessaires pour le projet. .env: fichier de variables d'environnement pour le stockage de données sensibles comme les touches API.
Usage
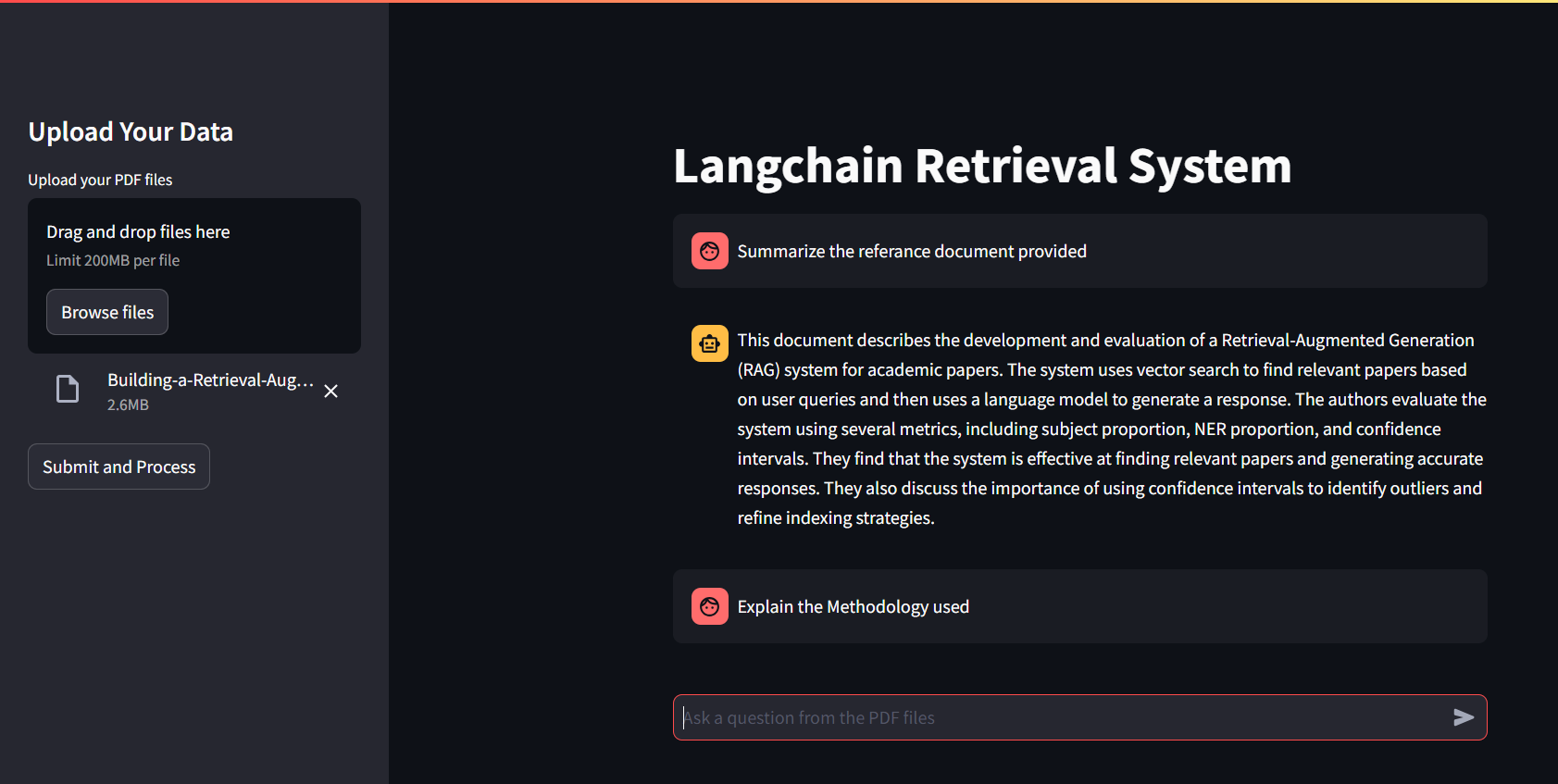
- Télécharger les fichiers PDF: utilisez la barre latérale "Télécharger vos données" pour télécharger un ou plusieurs fichiers PDF.
- Processus PDFS: cliquez sur "Soumettre et traiter" pour extraire du texte, générer des intégres et configurer une chaîne de récupération conversationnelle.
- Posez des questions: entrez des questions liées au contenu PDF téléchargé dans le champ de saisie du texte.
- Afficher les réponses: les réponses générées par le modèle conversationnel de Langchain seront affichées dans l'interface principale.
- Enregistrement: La journalisation est implémentée pour capturer les étapes et les horaires clés lors de l'extraction de texte PDF, de la section texte, de la création de magasins vectoriels et de la configuration de la chaîne conversationnelle. Les journaux sont affichés dans la console ou le terminal où l'application est exécutée.
Améliorations futures
- Améliorer la gestion des erreurs et les commentaires des utilisateurs lors du téléchargement et du traitement des fichiers.
- Améliorez l'évolutivité et les optimisations des performances pour gérer des documents PDF plus grands.
- Intégrer des modèles d'IA supplémentaires ou affiner les modèles existants pour de meilleures réponses conversationnelles.


