DOCCHAT: Sistema de recuperação de Langchain
Esse aplicativo Streamlit implementa um sistema de recuperação baseado em Langchain para processar documentos em PDF e realizar a recuperação de conversação usando as capacidades de Langchain.
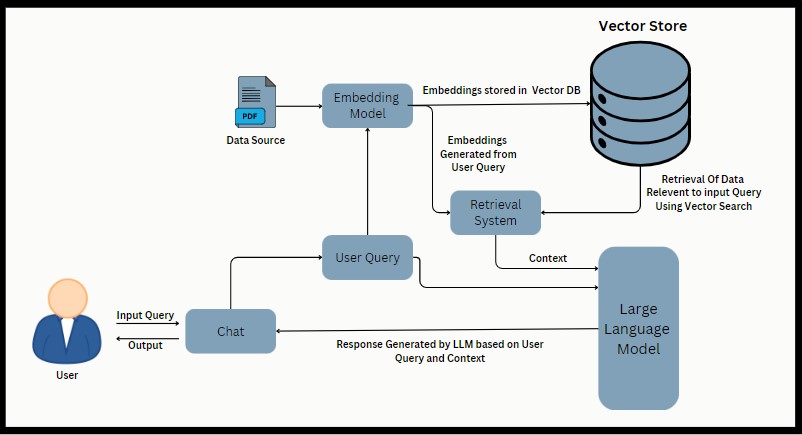
Arquitetura de Rag
Siacho de interface do usuário
Visão geral
O aplicativo permite que os usuários enviem arquivos PDF, extraem texto, dividam -o em pedaços, geram incorporações usando incorporações do Google Palm e criem uma cadeia de recuperação de conversação. Os usuários podem fazer perguntas relacionadas ao conteúdo do PDF processado e receber respostas com base na configuração da cadeia de conversação.
Tecnologias -chave usadas
- Langchain : uma biblioteca para tarefas de processamento de linguagem natural, incluindo divisão de texto e recuperação de conversação.
- Google Palm Incorporamentos : incorporações usadas para similaridade semântica e representação de texto.
- FAISS (Facebook AI similaridade Pesquisa) : uma biblioteca eficiente para pesquisa e agrupamento de vetores densos.
Configuração do projeto
Pré -requisitos
Ambiente Python : verifique se você tem o Python 3.x instalado.
Variáveis de ambiente : Crie um arquivo .env no diretório raiz do projeto com o seguinte conteúdo: google_api_key = your_google_api_key_here substitua your_google_api_key_here pela sua chave de API do Google real.
Instalação
- Clone o repositório : clone este repositório para sua máquina local:
git clone https://github.com/Varunv003/langchain-palm2-rag_application
- Configurar o ambiente virtual : é recomendável usar um ambiente virtual para gerenciar dependências:
python -m venv venv
# On Windows: .venvScriptsactivate
# On macOS/Linux: source venv/bin/activate
- Instale dependências : Instale os pacotes Python necessários usando o PIP:
pip install -r requirements.txt
- Estrutura do modelo : Para configurar a estrutura inicial da pasta do projeto, execute:
python template.py
# This command will create necessary directories and files based on your project needs.
- Executando o aplicativo para executar o aplicativo Streamlit:
streamlit run app.py
# The application will start, and you can access it in your web browser at http://localhost:8501.
Estrutura de arquivo
- App.py : Código do aplicativo principal do STRILHT para fazer upload de PDFs, processando -os e gerenciamento de interações do usuário.
- Helper.py : contém funções auxiliares para extração de texto em PDF, chunking de texto, criação de lojas de vetores FAISS e configuração da cadeia de conversação.
- model.py : script para inicializar a estrutura da pasta e criar diretórios/arquivos necessários para o projeto. .env: arquivo variável de ambiente para armazenar dados confidenciais, como as chaves da API.
Uso
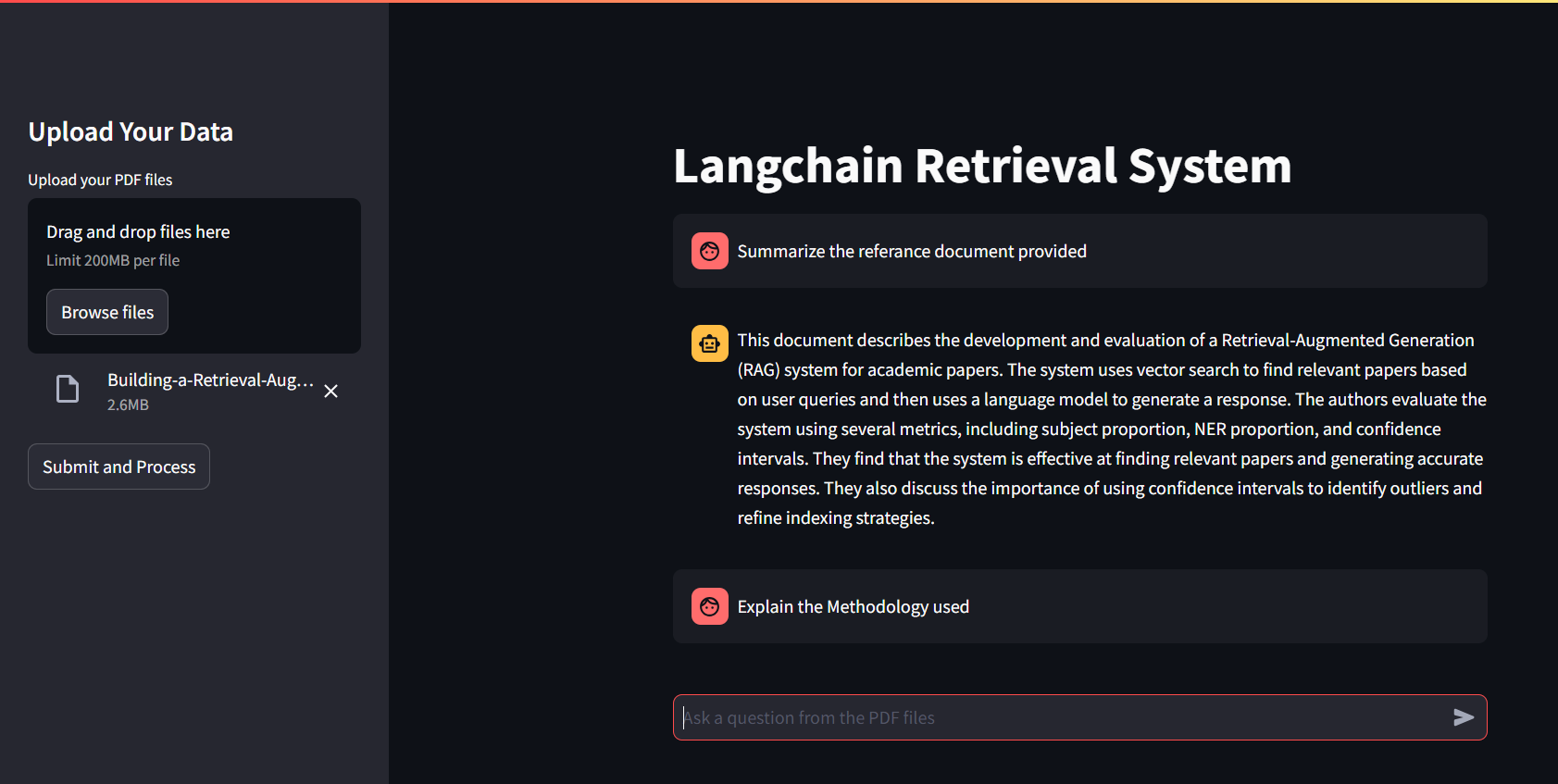
- Carregue arquivos PDF: use a barra lateral "Carregar seus dados" para fazer upload de um ou mais arquivos PDF.
- Processar PDFs: clique em "Enviar e processar" para extrair texto, gerar incorporação e configurar uma cadeia de recuperação de conversação.
- Faça perguntas: Digite perguntas relacionadas ao conteúdo do PDF enviado no campo de entrada de texto.
- Exibir respostas: as respostas geradas pelo modelo de conversação de Langchain serão exibidas na interface principal.
- Registro: o registro é implementado para capturar as principais etapas e horários durante a extração de texto em PDF, o chunking de texto, a criação de lojas de vetores e a configuração da cadeia de conversação. Os logs são exibidos no console ou terminal onde o aplicativo é executado.
Melhorias futuras
- Aprimore o manuseio de erros e o feedback do usuário durante o upload e processamento do arquivo.
- Melhore a escalabilidade e otimizações de desempenho para lidar com documentos maiores em PDF.
- Integrar modelos adicionais de IA ou refinar os modelos existentes para melhores respostas de conversação.


