Doktor: Langchain -Abrufsystem
Diese Stromanmeldung implementiert ein auf Langchain basierendes Abrufsystem zur Verarbeitung von PDF-Dokumenten und zur Durchführung von Konversationsabläufen mithilfe der Funktionen von Langchain.
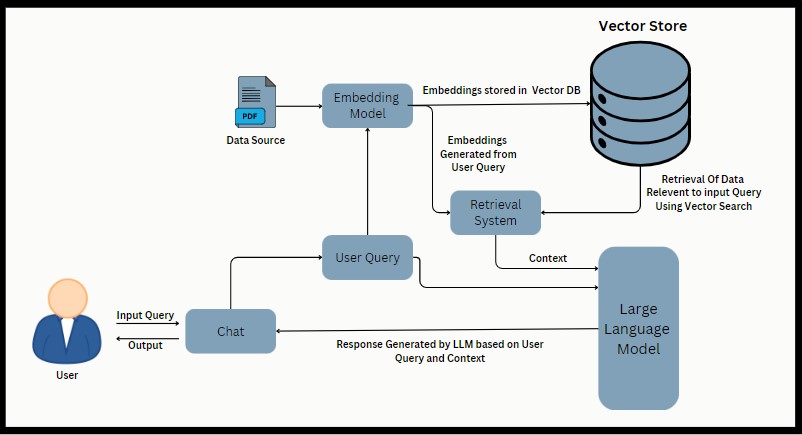
Lappenarchitektur
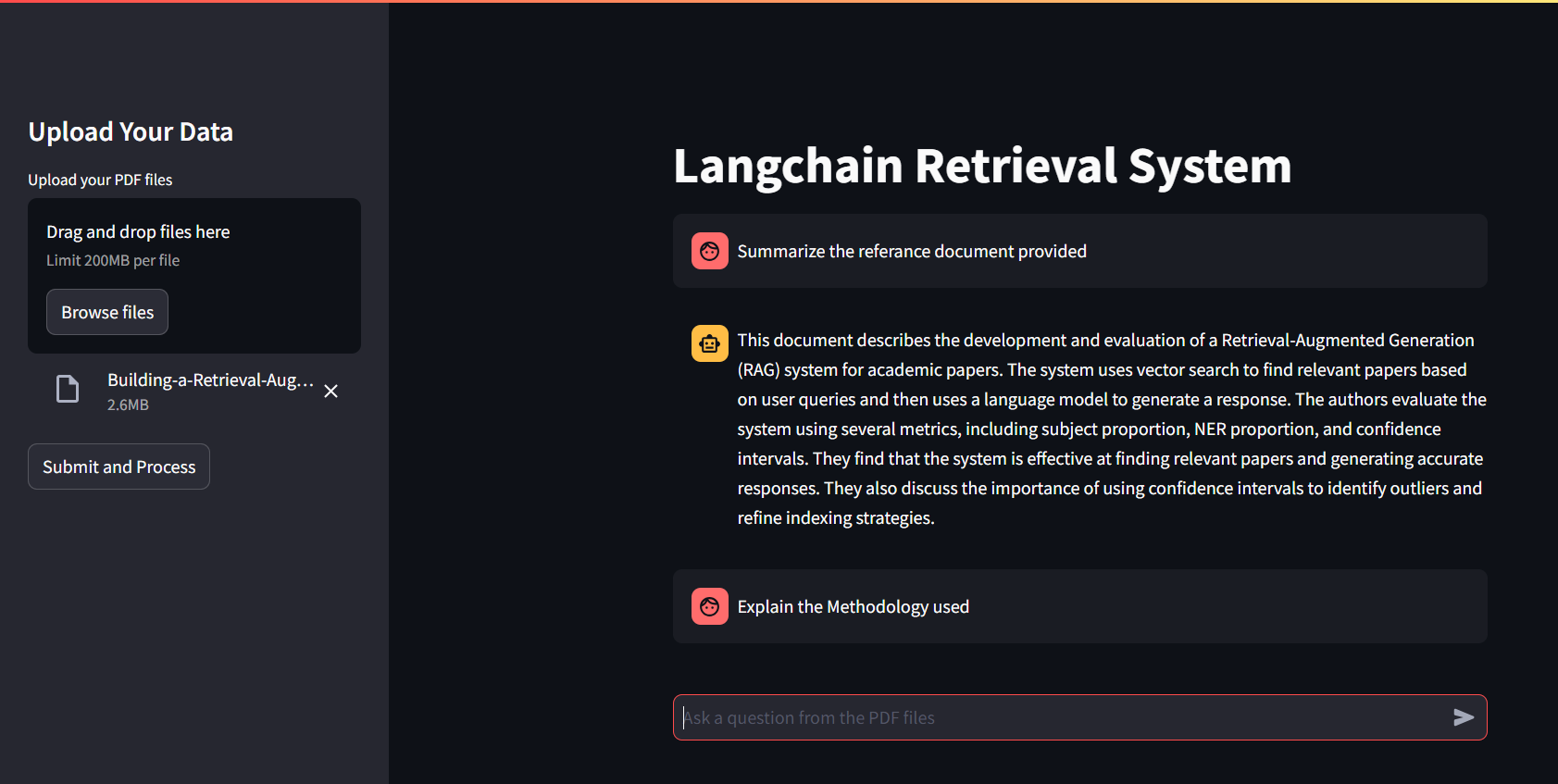
Stromlitische Benutzeroberfläche
Überblick
Mit der Anwendung können Benutzer PDF -Dateien hochladen, Text extrahieren, in Stücke aufteilen, Emetten mithilfe von Google -Palm -Einbettungen generieren und eine Konversations -Abrufkette erstellen. Benutzer können dann Fragen zum verarbeiteten PDF -Inhalt stellen und Antworten auf der Grundlage der Konversationskette erhalten.
Schlüsseltechnologien verwendet
- Langchain : Eine Bibliothek für Aufgaben zur Verarbeitung natürlicher Sprache, einschließlich Textaufteilung und Konversationsabnahme.
- Google Palm -Einbettungen : Einbettungen, die für semantische Ähnlichkeit und Textdarstellung verwendet werden.
- FAISS (Facebook -AI -Ähnlichkeitssuche) : Eine effiziente Bibliothek zur Ähnlichkeitssuche und das Clustering dichter Vektoren.
Projekt -Setup
Voraussetzungen
Python -Umgebung : Stellen Sie sicher, dass Python 3.x installiert ist.
Umgebungsvariablen : Erstellen Sie eine .env -Datei im Projekt Root -Verzeichnis mit dem folgenden Inhalt: Google_API_KEY = YOUR_GOOGLE_API_KEY_HERE Ersetzen Sie your_google_api_key_here durch Ihre tatsächliche Google -API -Taste.
Installation
- Klonen Sie das Repository : Klonen Sie dieses Repository in Ihre lokale Maschine:
git clone https://github.com/Varunv003/langchain-palm2-rag_application
- Einrichten der virtuellen Umgebung : Es wird empfohlen, eine virtuelle Umgebung zu verwenden, um Abhängigkeiten zu verwalten:
python -m venv venv
# On Windows: .venvScriptsactivate
# On macOS/Linux: source venv/bin/activate
- Installieren Sie Abhängigkeiten : Installieren Sie die erforderlichen Python -Pakete mit PIP:
pip install -r requirements.txt
- Vorlagenstruktur : Um die anfängliche Ordnerstruktur des Projekts einzurichten, leiten Sie:
python template.py
# This command will create necessary directories and files based on your project needs.
- Ausführen der Anwendung zum Ausführen der Streamlit -Anwendung:
streamlit run app.py
# The application will start, and you can access it in your web browser at http://localhost:8501.
Dateistruktur
- app.py : Haupt -Streamlit -Anwendungscode zum Hochladen von PDFs, zur Verarbeitung und Verwaltung von Benutzerinteraktionen.
- Helper.py : Enthält Helferfunktionen für die PDF -Textextraktion, das Textchunking, die Erstellung von Faiss Vector Store und die Konversationsketten -Setup.
- template.py : Skript zum Initialisieren der Ordnerstruktur und zum Erstellen der erforderlichen Verzeichnisse/Dateien für das Projekt. .Env: Umgebungsvariable Datei zum Speichern sensibler Daten wie API -Schlüssel.
Verwendung
- PDF -Dateien hochladen: Verwenden Sie die Seitenleiste "Laden Sie Ihre Daten hoch", um eine oder mehrere PDF -Dateien hochzuladen.
- Verarbeiten Sie PDFs: Klicken Sie auf "Senden und Prozess", um Text zu extrahieren, Einbettungen zu generieren und eine Konversationsabrufkette einzurichten.
- Fragen stellen: Geben Sie Fragen zum hochgeladenen PDF -Inhalt im Texteingangsfeld ein.
- Antworten anzeigen: Antworten, die vom Langchain -Konversationsmodell erzeugt werden, werden in der Hauptschnittstelle angezeigt.
- Protokollierung: Die Protokollierung wird implementiert, um die wichtigsten Schritte und Timings während der PDF -Textextraktion, des Textknackens, der Erstellung der Vektorspeicher und der Konversationsketten -Setup zu erfassen. Protokolle werden in der Konsole oder dem Terminal angezeigt, an dem die Anwendung ausgeführt wird.
Zukünftige Verbesserungen
- Verbesserung der Fehlerbehandlung und des Benutzerfeedbacks beim Upload und der Verarbeitung von Dateien.
- Verbesserung der Skalierbarkeit und Leistungsoptimierungen für die Behandlung größerer PDF -Dokumente.
- Integrieren Sie zusätzliche KI -Modelle oder verfeinern Sie vorhandene Modelle für bessere Konversationsreaktionen.


