findlargedir
0.9.1

(Феррис детектив Эстер Арзола, оригинальный дизайн Карен Рустад Тёльва)
Findlargedir - это инструмент, специально написанный для быстрого идентификации каталогов «черная дыра» на любой файловой системе, имеющей более 100 тыс. Записи в одной плоской структуре. Когда каталог имеет много записей (каталогов или файлов), получение списка каталогов становится медленнее и медленнее, влияя на производительность всех процессов, пытающихся получить список каталогов (например, для удаления некоторых файлов и/или на поиск некоторых конкретных файлов). Процессы чтения больших каталогов заморожены при этом и в конечном итоге оказываются в непрерывном сне («D») в течение более длинных и более длительных периодов времени. В зависимости от файловой системы, это может начать стать видимым с помощью 100K записей и начинает оказывать очень заметное воздействие на производительность с записями 1M+.
Такие каталоги в основном не могут ухудшаться, даже если контент очищается из -за того, что большинство файловых систем Linux и UN*X не поддерживают сокращение каталога каталога (например, очень распространенный ext3/ext4). Это часто случается с забытым каталогом веб -сессий (папка SESSERS PHP, где интервал GC был настроен на несколько дней), различными папками кэша (CMS скомпилированными шаблонами и кэшами), эмуляцией файловых систем POSIX и т. Д.
Программа попытается определить любое количество таких событий и сообщать о них на основе калибровки , т.е. Сколько предполагаемых записей каталога упакованы в каждом каталоге INODE для каждой файловой системы. При этом он определит коэффициент роста INODE каталогов к количеству записей/iNodes и будет использовать это соотношение для быстрого сканирования файловой системы, избегая выполнения дорогостоящих/медленных поисков каталогов. Несмотря на то, что существует много инструментов, которые сканируют файловую систему ( find , du , ncdu и т. Д.), Ни один из них не использует эвристику, чтобы избежать дорогостоящих поисков, поскольку они предназначены для того, чтобы быть полностью точными , в то время как этот инструмент предназначен для использования эвристики и оповещения о проблемах , не застряв в проблемных папках.
Программа не будет следовать Symlinks и потребует разрешений R/W для калибровки каталога, чтобы иметь возможность рассчитывать размер INODE каталога к количеству записей и оценить ряд записей в каталоге, фактически не считая их. Хотя этот метод представляет собой просто приближение фактического количества записей в каталоге, он достаточно хорош, чтобы быстро сканировать для оскорбительных каталогов.
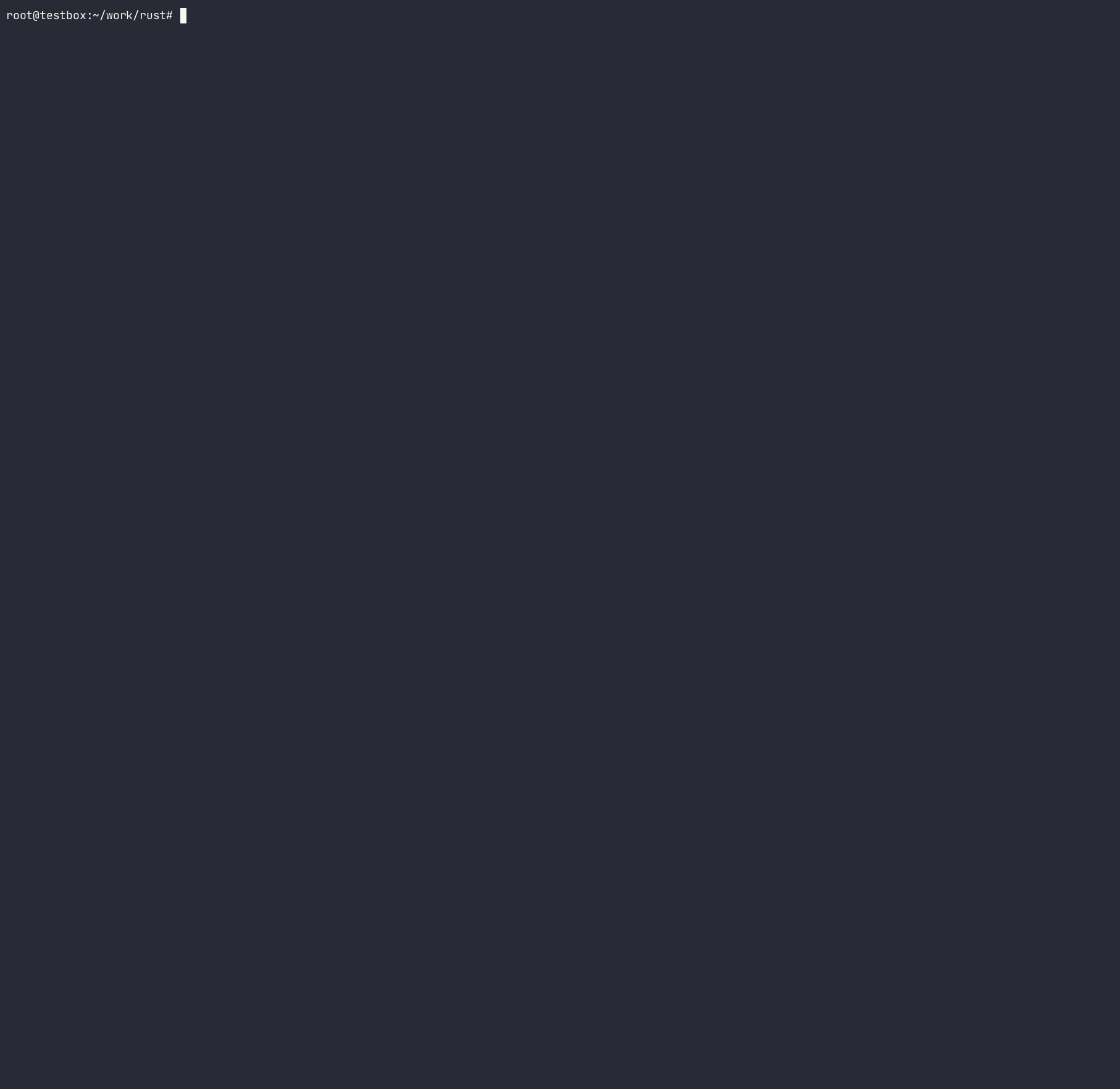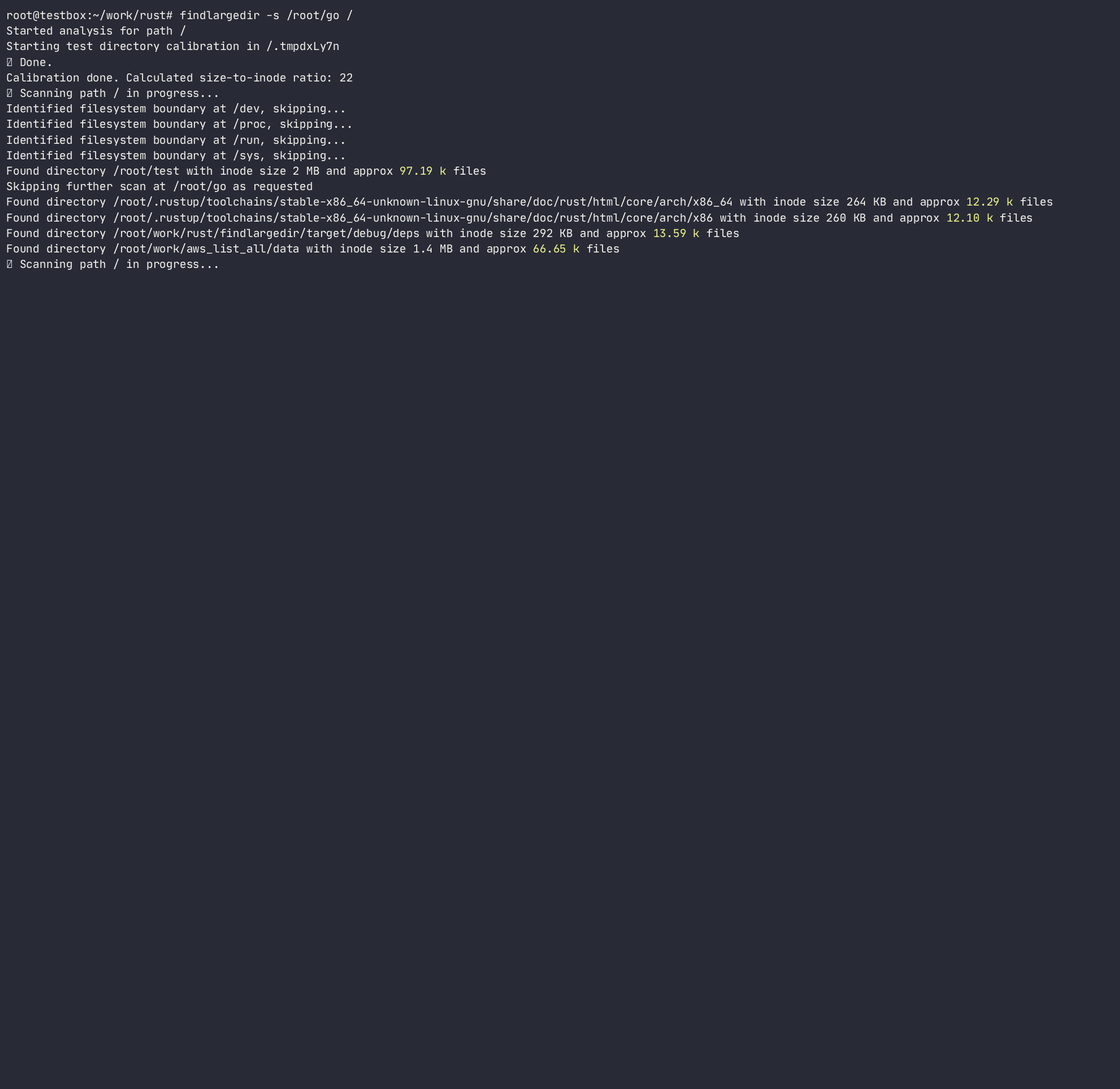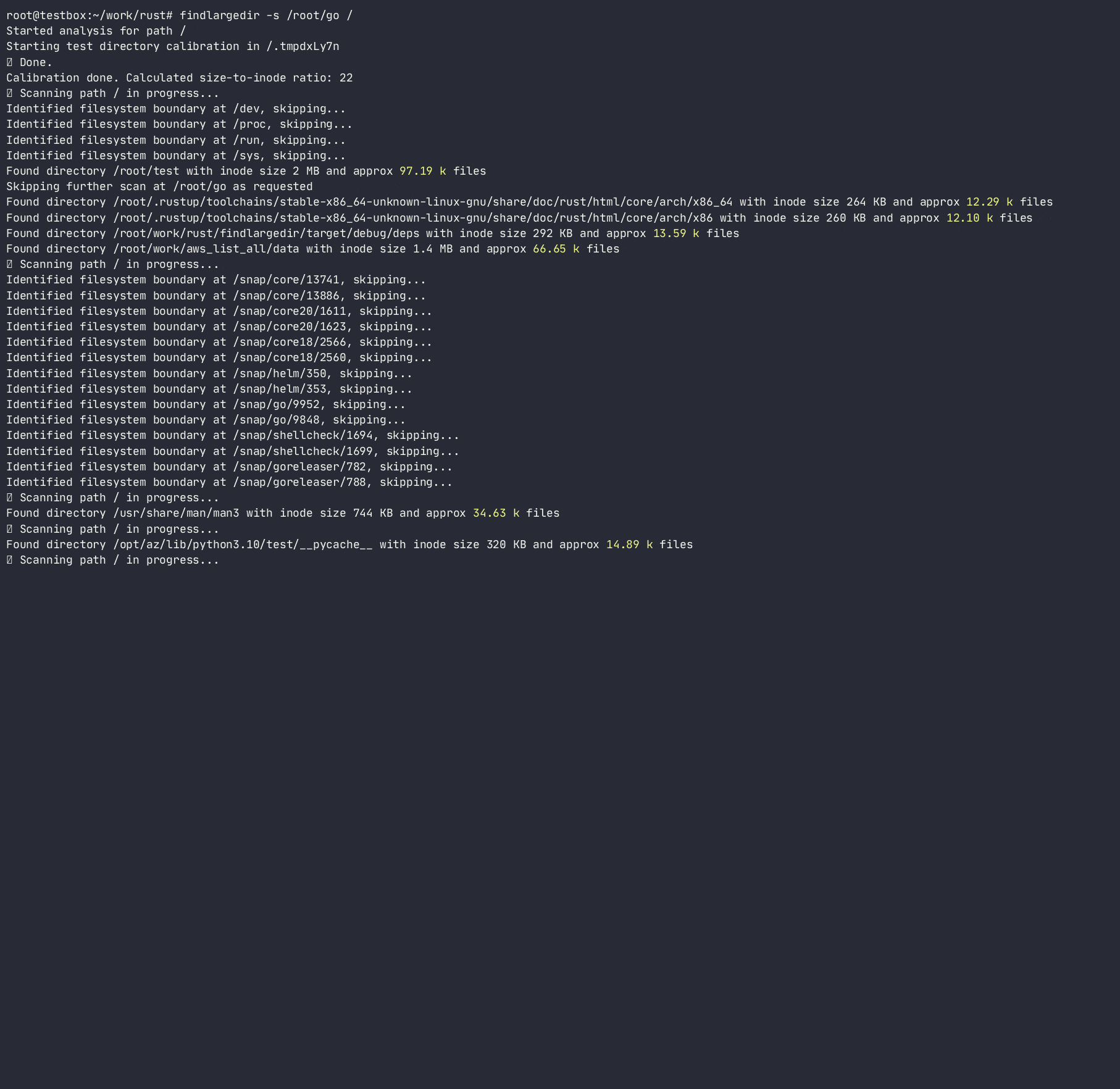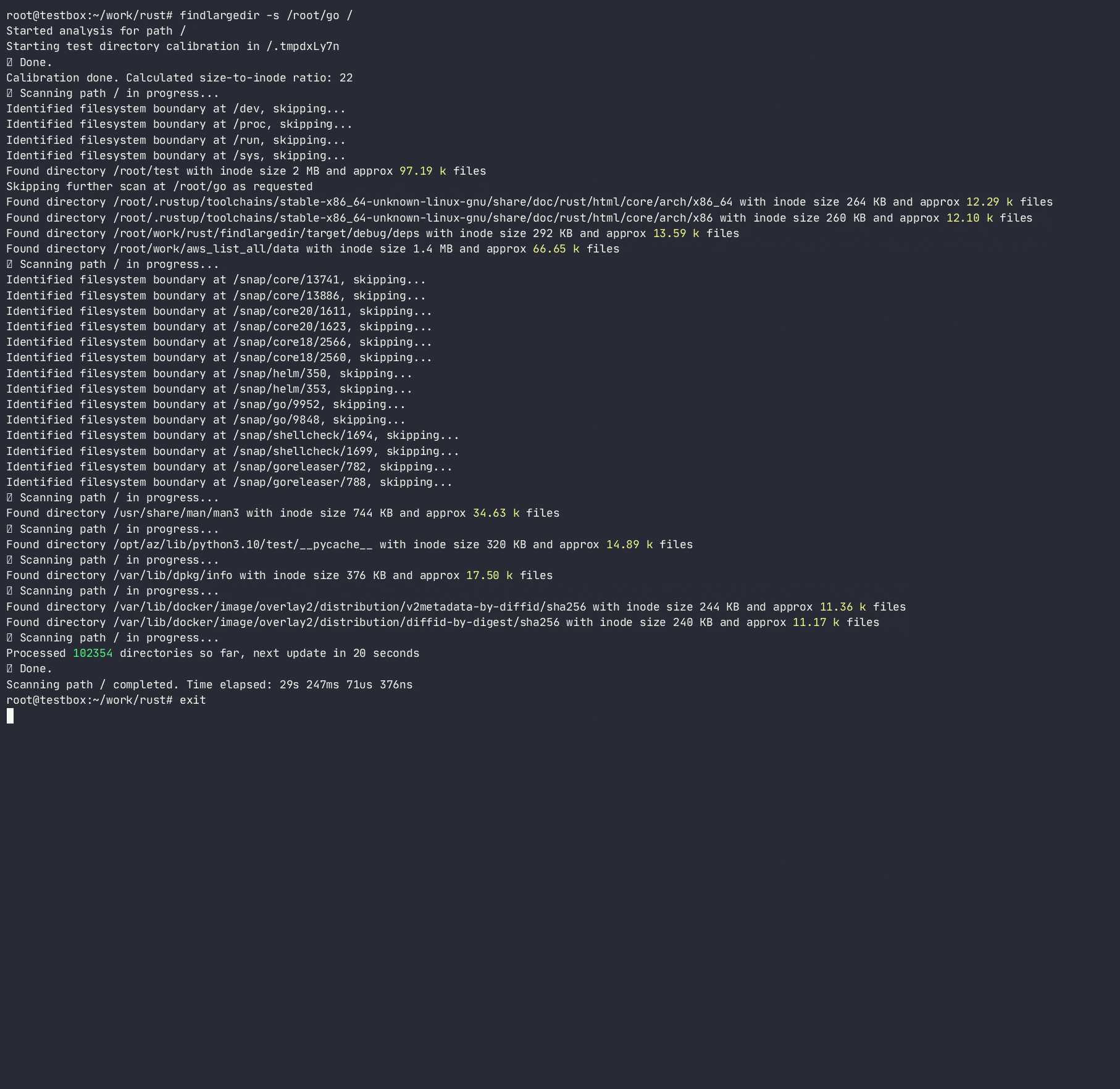
-a ) может вызвать чрезмерный ввод -вывод и чрезмерное использование памяти; Используйте только при необходимости Usage: findlargedir [OPTIONS] < PATH > ...
Arguments:
< PATH > ... Paths to check for large directories
Options:
-a, --accurate < ACCURATE >
Perform accurate directory entry counting [default: false] [possible values: true, false]
-o, --one-filesystem < ONE_FILESYSTEM >
Do not cross mount points [default: true] [possible values: true, false]
-c, --calibration-count < CALIBRATION_COUNT >
Calibration directory file count [default: 100000]
-A, --alert-threshold < ALERT_THRESHOLD >
Alert threshold count (print the estimate) [default: 10000]
-B, --blacklist-threshold < BLACKLIST_THRESHOLD >
Blacklist threshold count (print the estimate and stop deeper scan) [default: 100000]
-x, --threads < THREADS >
Number of threads to use when calibrating and scanning [default: 24]
-p, --updates < UPDATES >
Seconds between status updates, set to 0 to disable [default: 20]
-i, --size-inode-ratio < SIZE_INODE_RATIO >
Skip calibration and provide directory entry to inode size ratio (typically ~ 21-32) [default: 0]
-t, --calibration-path < CALIBRATION_PATH >
Custom calibration directory path
-s, --skip-path < SKIP_PATH >
Directories to exclude from scanning
-h, --help
Print help information
-V, --version
Print version information При использовании точного режима ( -a параметра) Остерегайтесь, что крупные поиски каталогов будут полностью задержать процесс в течение длительных периодов времени. Этот режим, в основном, является вторичным полностью точным передачей, возможно, нарушением каталога, рассчитывающего точное количество записей.
Чтобы избежать спуска в монтируемые файловые системы (как в опции find -xdev), параметр «Параметр» с одним из них (параметр -o ) переключается по умолчанию, но его можно отключить, если это необходимо.
Можно полностью пропустить фазу калибровки, вручную предоставляя размер INODE каталога к количеству записей с параметром -i . Это имеет смысл только тогда, когда вы уже знаете соотношение, например, из предыдущих прогонов.
Настройка -p Параметры на 0 остановит программу от случайных обновлений статуса.
Аппаратное обеспечение: 8-ядерный Xeon E5-1630 с 4-приводом SATA RAID-10
Настройка эталона:
$ cat bench1.sh
#! /bin/dash
exec /usr/bin/find / -xdev -type d -size +200000c
$ cat bench2.sh
#! /bin/dash
exec /usr/local/sbin/findlargedir /Фактические результаты, измеренные с помощью гиперфоины:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 357.040 s ± 7.176 s [User: 2.324 s, System: 13.881 s]
Range (min … max): 349.639 s … 367.636 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 199.751 s ± 4.431 s [User: 75.163 s, System: 141.271 s]
Range (min … max): 190.136 s … 203.432 s 10 runs
Summary
' ./bench2.sh ' ran
1.79 ± 0.05 times faster than ' ./bench1.sh ' Аппаратное обеспечение: 48-ядерный Xeon Silver 4214, 7-привод SM883 SATA HW RAID-5, содержимое 2 ТБ (дюжина контейнеров с небольшими файлами)
Такая же эталонная установка. Результаты:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 392.433 s ± 1.952 s [User: 16.056 s, System: 81.994 s]
Range (min … max): 390.284 s … 395.732 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 34.650 s ± 0.469 s [User: 79.441 s, System: 528.939 s]
Range (min … max): 34.049 s … 35.388 s 10 runs
Summary
' ./bench2.sh ' ran
11.33 ± 0.16 times faster than ' ./bench1.sh ' 

