findlargedir
0.9.1

(Ferris, o detetive de Esther Arzola, design original de Karen Rustad Tölva)
O FindLargedir é uma ferramenta escrita especificamente para ajudar a identificar rapidamente os diretórios de "buraco negro" em um sistema de arquivos com mais de 100k entradas em uma única estrutura plana. Quando um diretório possui muitas entradas (diretórios ou arquivos), a obtenção da listagem de diretórios fica mais lenta e lenta, impactando o desempenho de todos os processos que tentam obter uma listagem de diretórios (por exemplo, para excluir alguns arquivos e/ou encontrar alguns arquivos específicos). Processos A leitura de grandes inodos de diretórios ficam congelados ao fazê -lo e acabam no sono ininterrupto ("D" estado) por períodos mais longos e mais longos. Dependendo do sistema de arquivos, isso pode começar a se tornar visível com entradas de 100k e começa a ser um impacto de desempenho muito perceptível com as entradas de 1M+.
Esses diretórios não podem encolher de volta, mesmo que o conteúdo seja limpo devido ao fato de que a maioria dos sistemas de arquivos Linux e Un*X não suporta o encolhimento do inode diretório (por exemplo, ext3/ext4 muito comum). Isso geralmente acontece com o Diretório de Sessões da Web esquecido (pasta PHP Sessions, onde o intervalo GC foi configurado para vários dias), várias pastas de cache (modelos e caches compilados do CMS).
O programa tentará identificar qualquer número desses eventos e relatar sobre eles com base na calibração , ou seja. Quantas entradas de diretório assumidas são embaladas em cada diretório inode para cada sistema de arquivos. Ao fazer isso, determinará a taxa de crescimento do diretório para o número de entradas/inodos e usará essa proporção para digitalizar rapidamente o sistema de arquivos, evitando pesquisas de diretório caras/lentas. Embora existam muitas ferramentas que digitalizam o sistema de arquivos ( find , du , ncdu etc.), nenhuma delas usa heurísticas para evitar pesquisas caras, pois elas são projetadas para serem totalmente precisas , enquanto essa ferramenta deve usar heurísticas e alertar sobre problemas sem ficar preso sobre pastas problemáticas.
O programa não seguirá os links simbólicos e requer permissões de R/W para calibrar o diretório para poder calcular um tamanho de inode diretório para o número de entradas e estimar várias entradas em um diretório sem realmente contá -las. Embora esse método seja apenas uma aproximação do número real de entradas em um diretório, é bom o suficiente para digitalizar rapidamente os diretórios ofensivos.
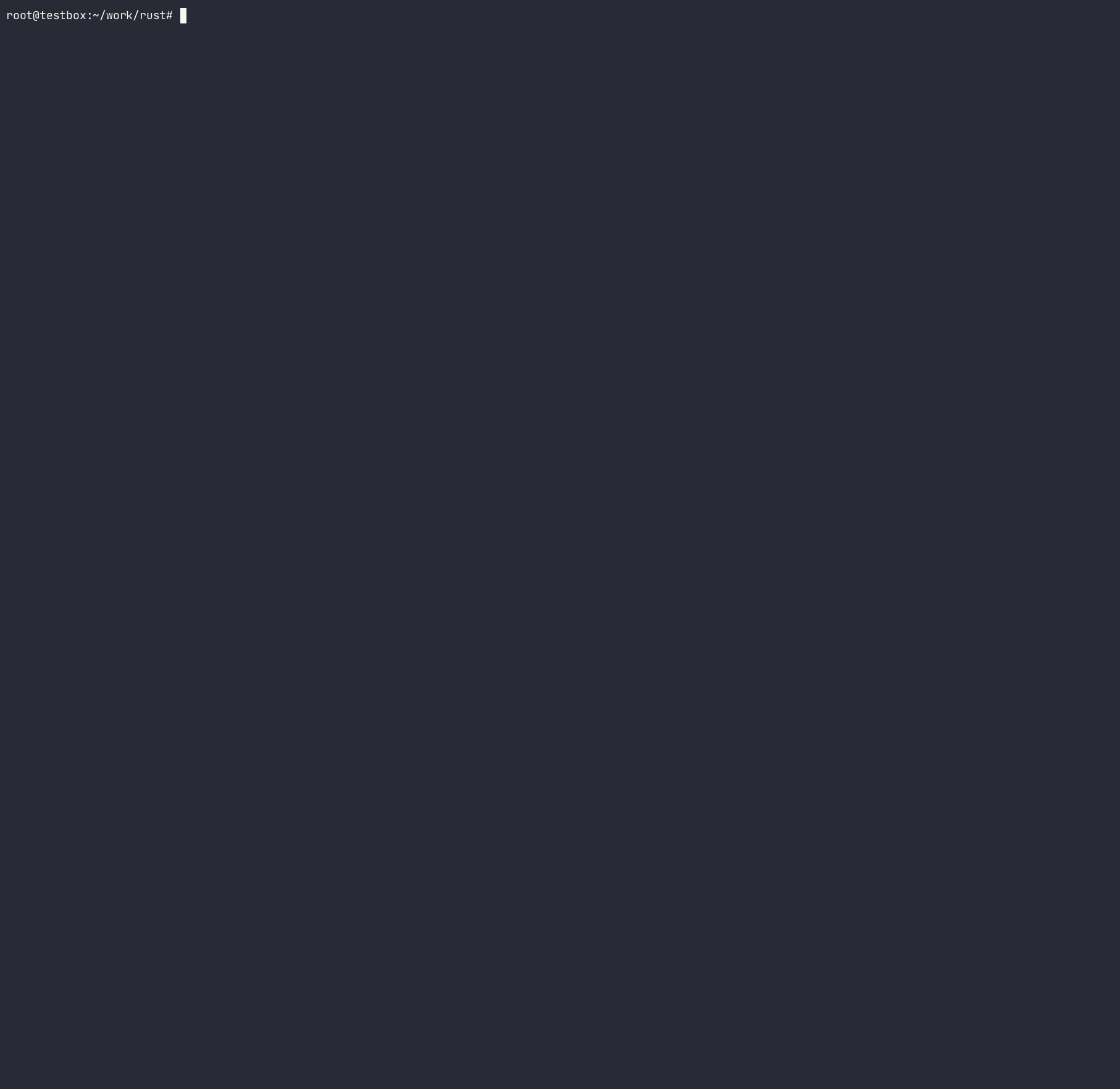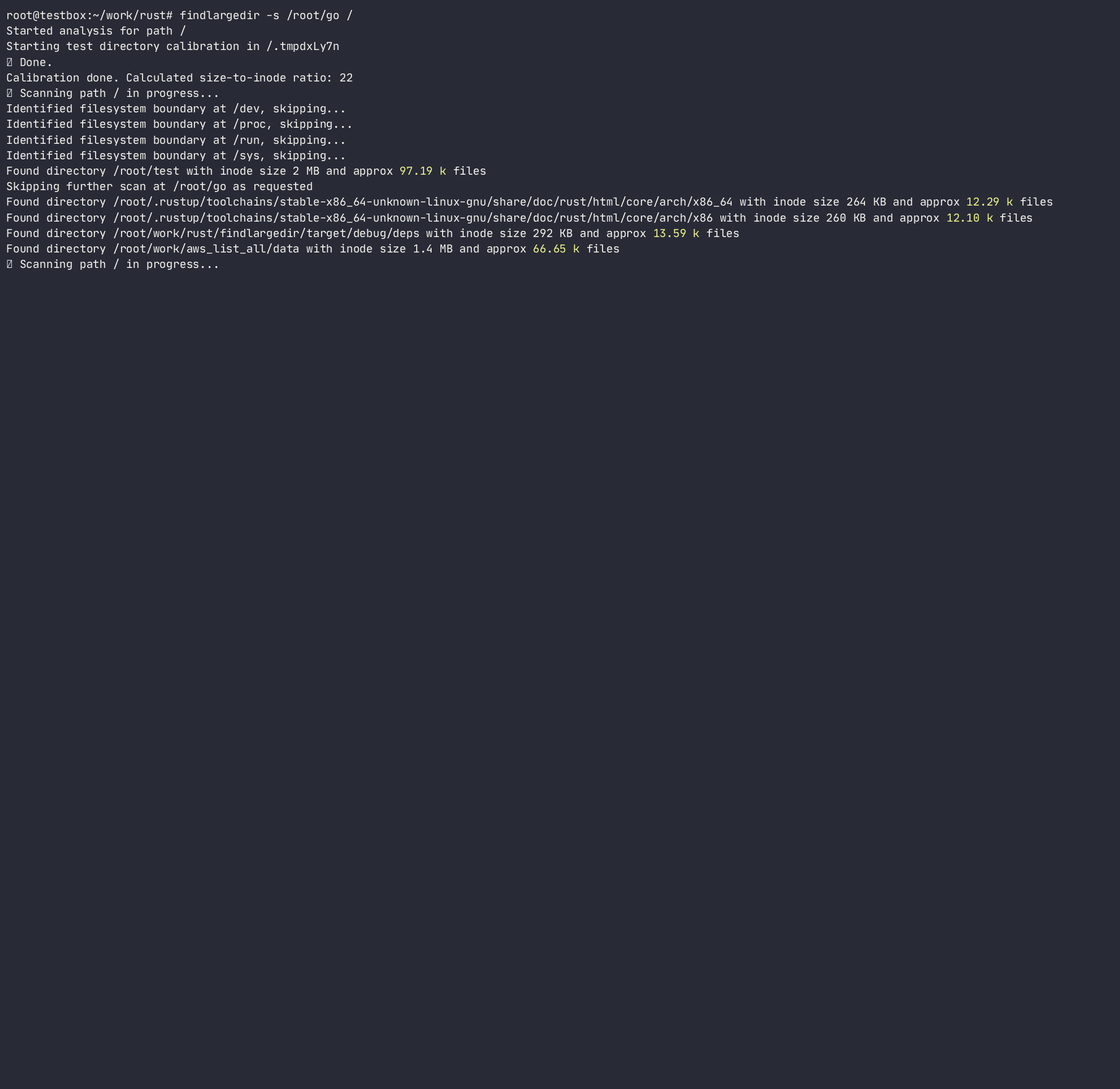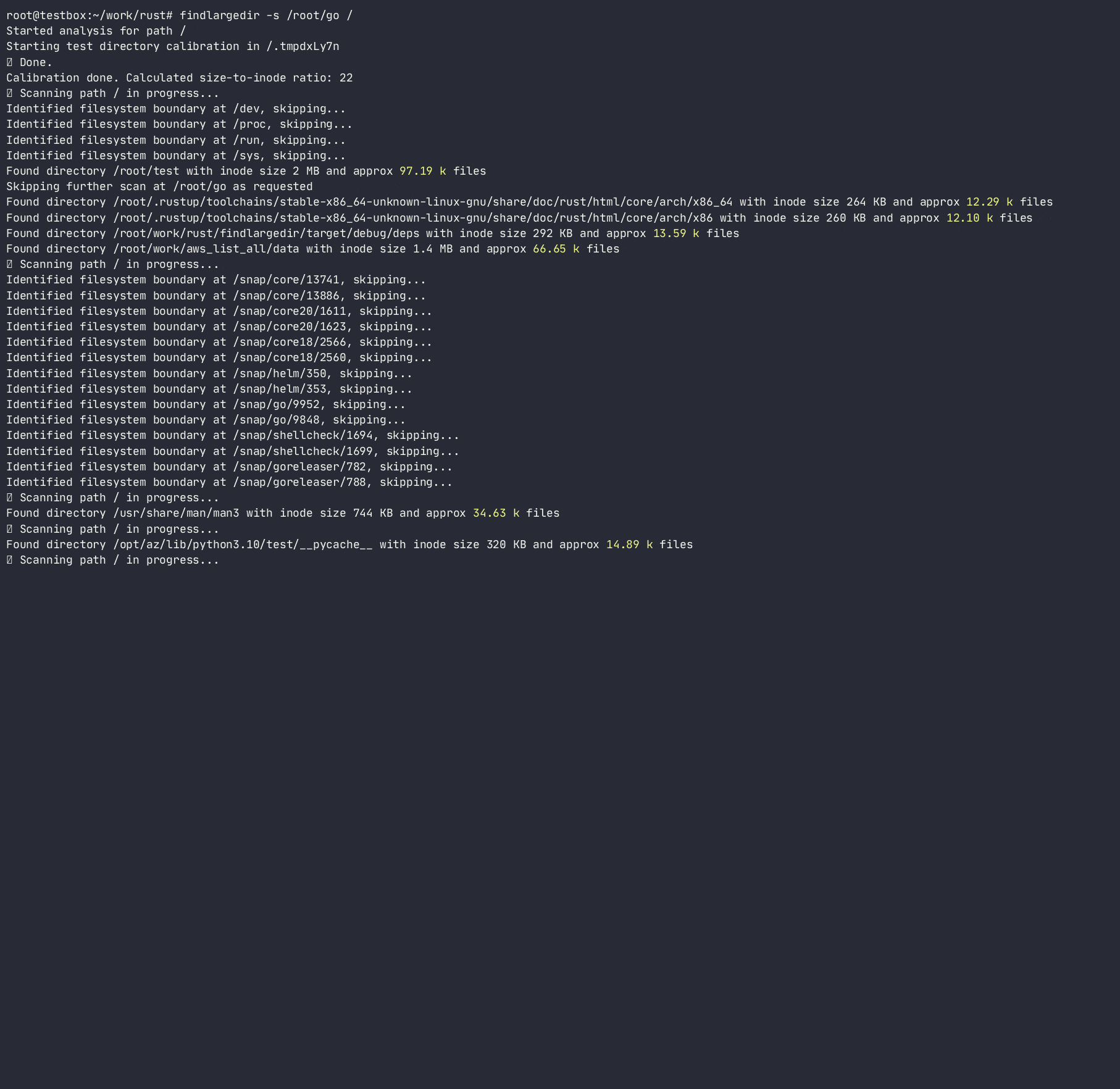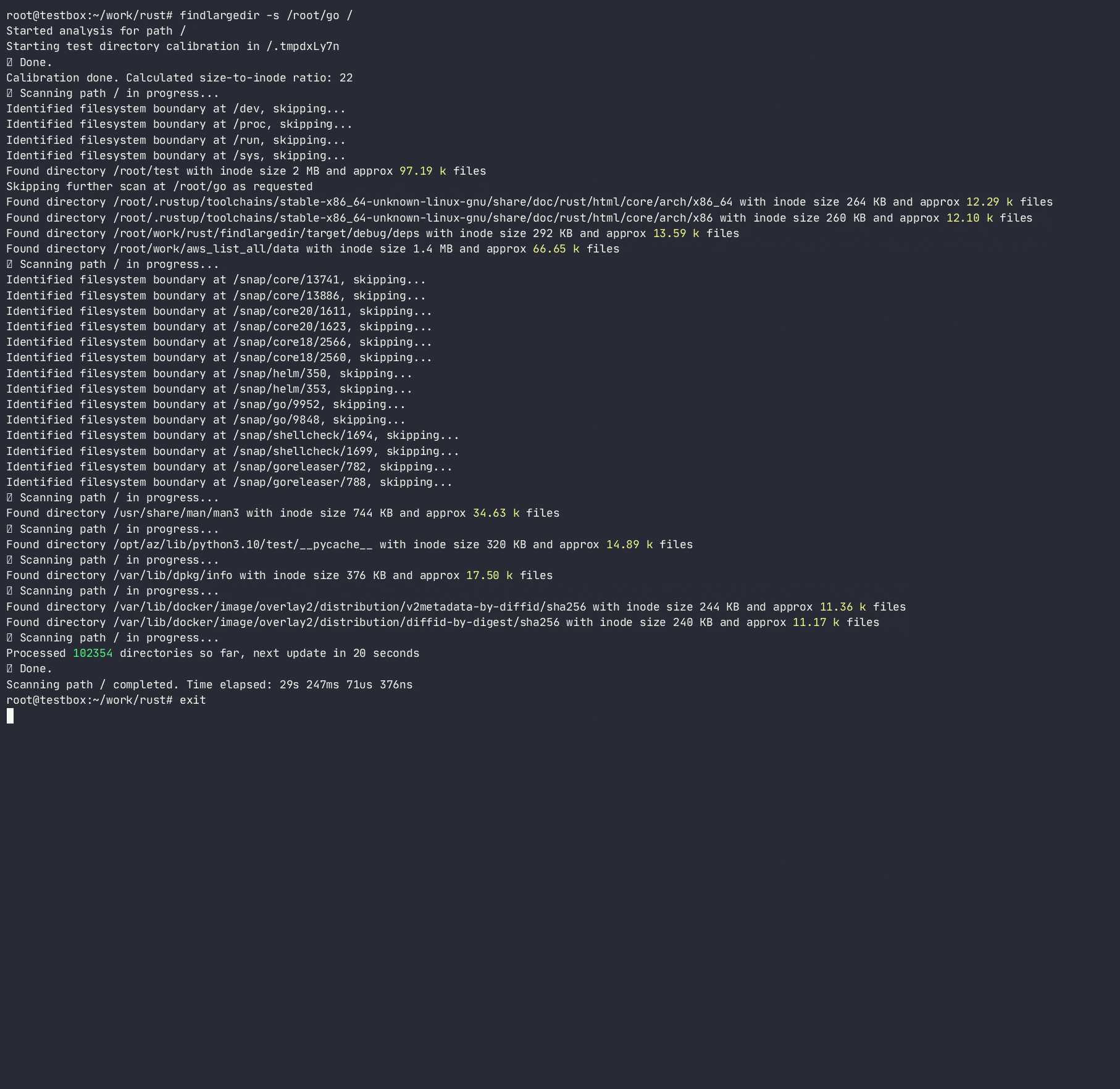
-a ) pode causar uma E/S excessiva e um uso excessivo de memória; Use apenas quando apropriado Usage: findlargedir [OPTIONS] < PATH > ...
Arguments:
< PATH > ... Paths to check for large directories
Options:
-a, --accurate < ACCURATE >
Perform accurate directory entry counting [default: false] [possible values: true, false]
-o, --one-filesystem < ONE_FILESYSTEM >
Do not cross mount points [default: true] [possible values: true, false]
-c, --calibration-count < CALIBRATION_COUNT >
Calibration directory file count [default: 100000]
-A, --alert-threshold < ALERT_THRESHOLD >
Alert threshold count (print the estimate) [default: 10000]
-B, --blacklist-threshold < BLACKLIST_THRESHOLD >
Blacklist threshold count (print the estimate and stop deeper scan) [default: 100000]
-x, --threads < THREADS >
Number of threads to use when calibrating and scanning [default: 24]
-p, --updates < UPDATES >
Seconds between status updates, set to 0 to disable [default: 20]
-i, --size-inode-ratio < SIZE_INODE_RATIO >
Skip calibration and provide directory entry to inode size ratio (typically ~ 21-32) [default: 0]
-t, --calibration-path < CALIBRATION_PATH >
Custom calibration directory path
-s, --skip-path < SKIP_PATH >
Directories to exclude from scanning
-h, --help
Print help information
-V, --version
Print version information Ao usar o modo preciso ( -a parâmetro), tenha cuidado que as grandes pesquisas de diretório paralisam completamente o processo por longos períodos de tempo. O que esse modo faz é basicamente um passe secundário totalmente preciso em um diretório possivelmente ofensivo, calculando o número exato de entradas.
Para evitar descer nos sistemas de arquivos montados (como na opção Find -xDev), o Modo de sistema de um arquivo ( -o ) é alterado por padrão, mas pode ser desativado, se necessário.
É possível pular completamente a fase de calibração, fornecendo manualmente o tamanho do inode do diretório para o número de entradas com parâmetro -i . Só faz sentido quando você já conhece a proporção, por exemplo, de execuções anteriores.
A configuração -p Paramter para 0 impedirá que o programa forneça atualizações de status ocasionais.
Hardware: 8 núcleos Xeon E5-1630 com SATA RAID-10 de 4 acionamentos
Configuração de benchmark:
$ cat bench1.sh
#! /bin/dash
exec /usr/bin/find / -xdev -type d -size +200000c
$ cat bench2.sh
#! /bin/dash
exec /usr/local/sbin/findlargedir /Resultados reais medidos com hiperfina:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 357.040 s ± 7.176 s [User: 2.324 s, System: 13.881 s]
Range (min … max): 349.639 s … 367.636 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 199.751 s ± 4.431 s [User: 75.163 s, System: 141.271 s]
Range (min … max): 190.136 s … 203.432 s 10 runs
Summary
' ./bench2.sh ' ran
1.79 ± 0.05 times faster than ' ./bench1.sh ' Hardware: 48 núcleo Xeon Silver 4214, SM883 SATA HW RAID-5 Matriz de 7 drives, conteúdo de 2 TB (dúzia de contêineres com arquivos pequenos)
Mesma configuração de referência. Resultados:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 392.433 s ± 1.952 s [User: 16.056 s, System: 81.994 s]
Range (min … max): 390.284 s … 395.732 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 34.650 s ± 0.469 s [User: 79.441 s, System: 528.939 s]
Range (min … max): 34.049 s … 35.388 s 10 runs
Summary
' ./bench2.sh ' ran
11.33 ± 0.16 times faster than ' ./bench1.sh ' 

