findlargedir
0.9.1

(Ferris le détective d'Esther Arzola, conception originale de Karen Rustad Tölva)
FindLargedir est un outil spécifiquement écrit pour aider à identifier rapidement les répertoires "Black Hole" sur un système de fichiers ayant plus de 100 000 entrées dans une seule structure plate. Lorsqu'un répertoire dispose de nombreuses entrées (répertoires ou fichiers), l'obtention de la liste des répertoires devient de plus en plus lente, un impact sur les performances de tous les processus qui tentent d'obtenir une liste de répertoires (par exemple pour supprimer certains fichiers et / ou pour trouver des fichiers spécifiques). Les processus de lecture de grands inodes de répertoire sont congelés en le faisant et se retrouvent dans le sommeil sans interruption (état "D") pendant de plus en plus de périodes. Selon le système de fichiers, cela pourrait commencer à devenir visible avec des entrées de 100k et commence à être un impact de performance très notable avec des entrées de 1M +.
Ces répertoires ne peuvent principalement pas rétrécir même si le contenu est nettoyé en raison du fait que la plupart des systèmes de fichiers Linux et UN * ne prennent pas en charge le répertoire inode en rétrécissement (par exemple, très commun EXT3 / EXT4). Cela se produit souvent avec le répertoire des sessions Web oublié (dossier PHP Sessions où l'intervalle GC a été configuré à plusieurs jours), divers dossiers de cache (modèles et caches compilés CMS), stockage d'objets émulant le système de fichiers POSIX, etc.
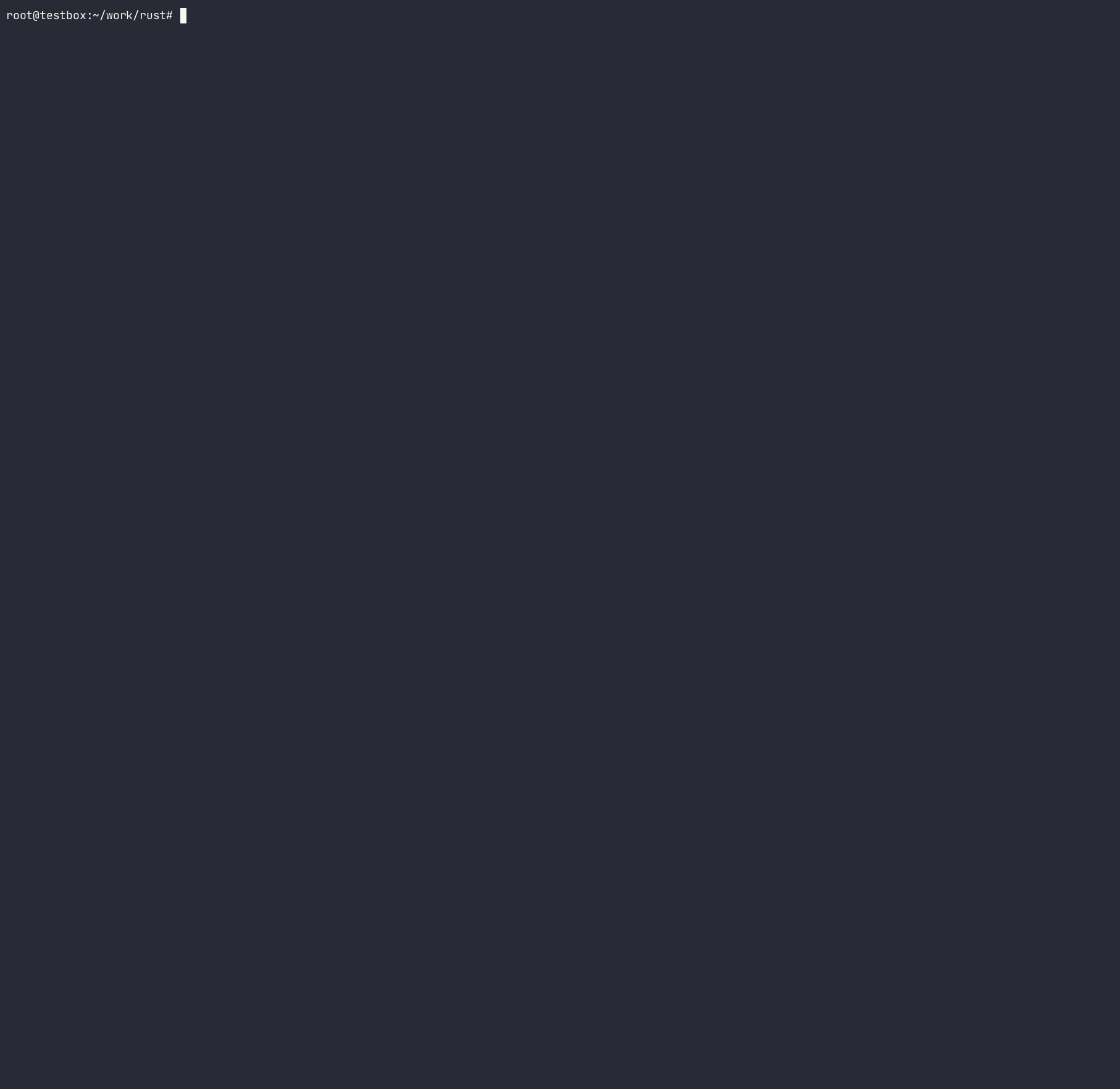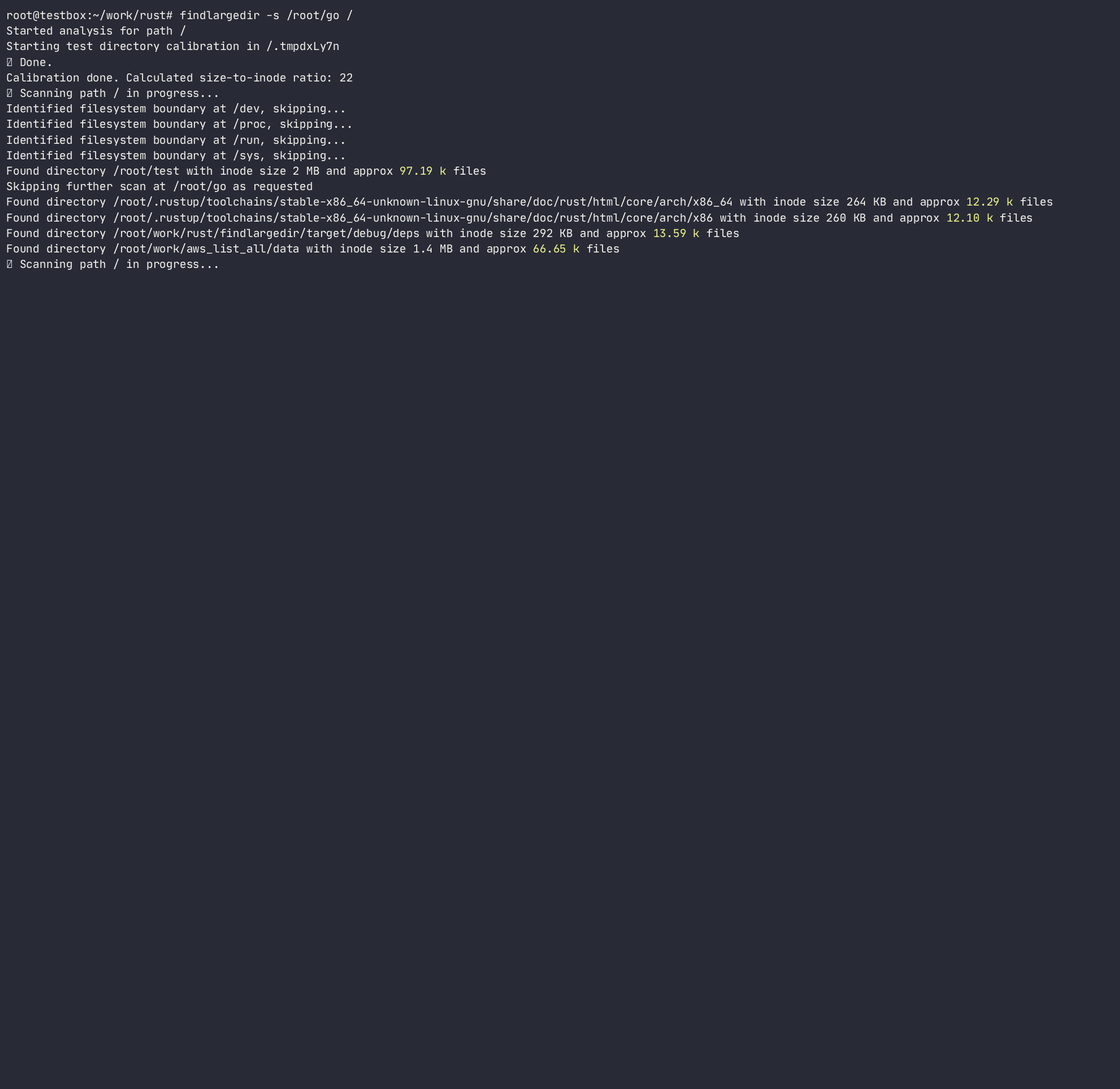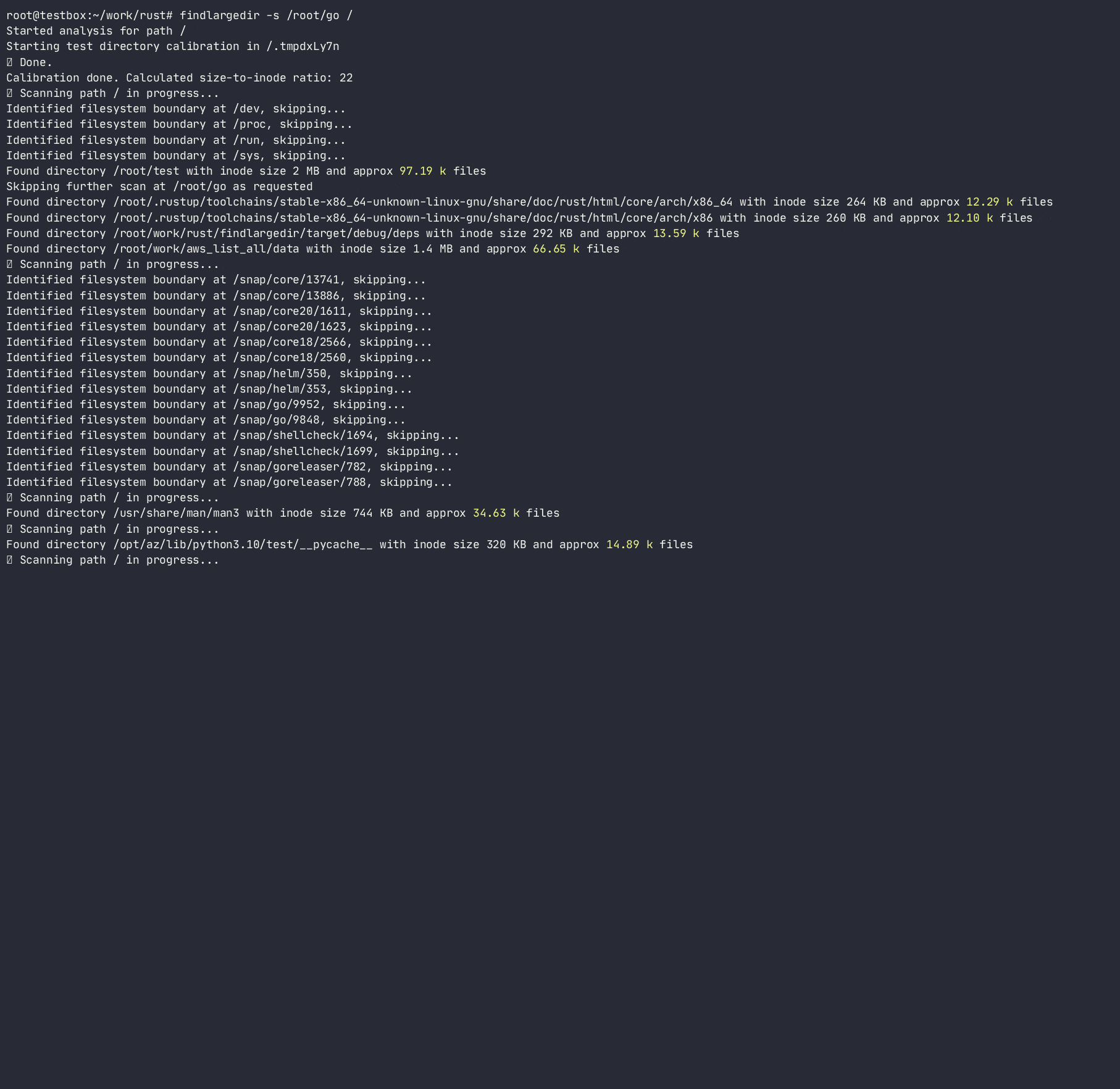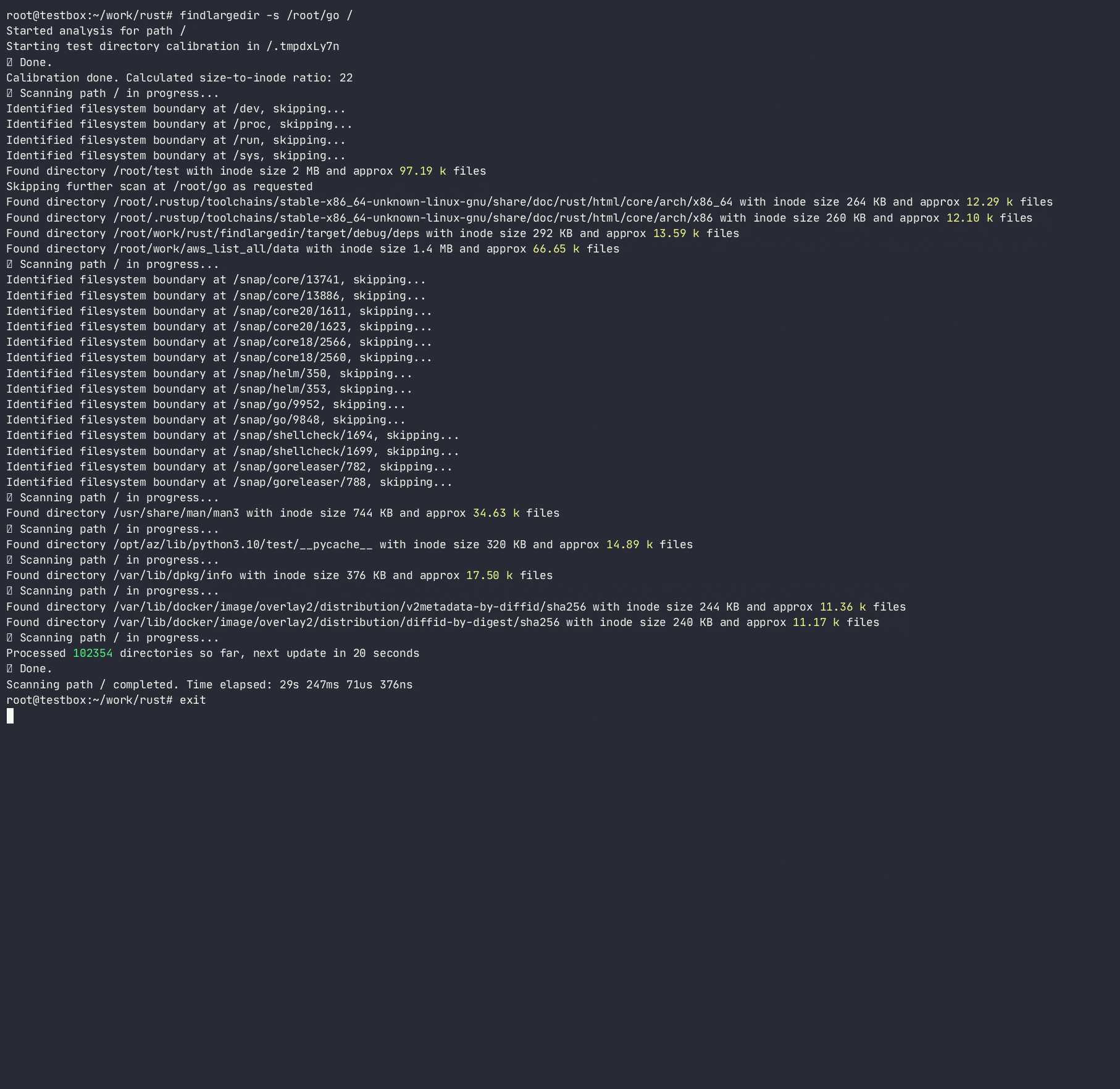
Le programme tentera d'identifier un certain nombre de ces événements et de les rapporter sur leur base d' étalonnage , c'est-à-dire. Combien d'entrées de répertoire supposées sont emballées dans chaque répertoire inode pour chaque système de fichiers. Ce faisant, il déterminera le répertoire du rapport de croissance inode au nombre d'entrées / inodes et utilisera ce ratio pour analyser rapidement le système de fichiers, en évitant de faire des recherches coûteuses / lentes. Bien qu'il existe de nombreux outils qui scannent le système de fichiers ( find , du , ncdu , etc.), aucun d'entre eux n'utilise des heuristiques pour éviter les recherches coûteuses, car elles sont conçues pour être pleinement précises , tandis que cet outil est destiné à utiliser l'heuristique et à alerter sur les problèmes sans rester coincé sur des dossiers problématiques.
Le programme ne suivra pas les liens symboliques et nécessite des autorisations R / W pour calibrer le répertoire pour pouvoir calculer un répertoire de la taille du nombre de personnes et du nombre de entrées et d'estimer un certain nombre d'entrées dans un répertoire sans les compter réellement. Bien que cette méthode ne soit qu'une approximation du nombre réel d'entrées dans un répertoire, il est assez bon pour rechercher rapidement les répertoires offensés.
-a ) peut provoquer une E / S excessive et une utilisation excessive de la mémoire; Utiliser uniquement le cas échéant Usage: findlargedir [OPTIONS] < PATH > ...
Arguments:
< PATH > ... Paths to check for large directories
Options:
-a, --accurate < ACCURATE >
Perform accurate directory entry counting [default: false] [possible values: true, false]
-o, --one-filesystem < ONE_FILESYSTEM >
Do not cross mount points [default: true] [possible values: true, false]
-c, --calibration-count < CALIBRATION_COUNT >
Calibration directory file count [default: 100000]
-A, --alert-threshold < ALERT_THRESHOLD >
Alert threshold count (print the estimate) [default: 10000]
-B, --blacklist-threshold < BLACKLIST_THRESHOLD >
Blacklist threshold count (print the estimate and stop deeper scan) [default: 100000]
-x, --threads < THREADS >
Number of threads to use when calibrating and scanning [default: 24]
-p, --updates < UPDATES >
Seconds between status updates, set to 0 to disable [default: 20]
-i, --size-inode-ratio < SIZE_INODE_RATIO >
Skip calibration and provide directory entry to inode size ratio (typically ~ 21-32) [default: 0]
-t, --calibration-path < CALIBRATION_PATH >
Custom calibration directory path
-s, --skip-path < SKIP_PATH >
Directories to exclude from scanning
-h, --help
Print help information
-V, --version
Print version information Lorsque vous utilisez un mode précis ( -a paramètre), méfiez-vous que les grandes recherches de répertoires calent complètement le processus pendant de longues périodes. Ce que fait ce mode, c'est essentiellement une réussite secondaire entièrement précise sur un répertoire éventuellement incriminé calculant le nombre exact d'entrées.
Pour éviter la descente dans les systèmes de fichiers montés (comme dans l'option de find -xdev), le mode paramètre One-FileSystem (paramètre -o ) est basculé par défaut, mais il peut être désactivé si nécessaire.
Il est possible de sauter complètement la phase d'étalonnage en fournissant manuellement le répertoire de la taille du répertoire et du rapport des entrées avec le paramètre -i . Cela n'a de sens que lorsque vous connaissez déjà le rapport, par exemple des analyses précédentes.
Le réglage -p Paramter à 0 empêchera le programme de donner des mises à jour de statut occasionnelles.
Matériel: 8 cœurs Xeon E5-1630 avec SATA RAID-10 à 4 lits
Configuration de référence:
$ cat bench1.sh
#! /bin/dash
exec /usr/bin/find / -xdev -type d -size +200000c
$ cat bench2.sh
#! /bin/dash
exec /usr/local/sbin/findlargedir /Résultats réels mesurés avec l'hyperfine:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 357.040 s ± 7.176 s [User: 2.324 s, System: 13.881 s]
Range (min … max): 349.639 s … 367.636 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 199.751 s ± 4.431 s [User: 75.163 s, System: 141.271 s]
Range (min … max): 190.136 s … 203.432 s 10 runs
Summary
' ./bench2.sh ' ran
1.79 ± 0.05 times faster than ' ./bench1.sh ' Matériel: 48 cœurs Xeon Silver 4214, 7-Drive SM883 SATA HW RAID-5 TABLEAU, CONTENU 2TB (DOZENE DE CONTATEURS AVEC PETITS FIDES)
Même configuration de référence. Résultats:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 392.433 s ± 1.952 s [User: 16.056 s, System: 81.994 s]
Range (min … max): 390.284 s … 395.732 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 34.650 s ± 0.469 s [User: 79.441 s, System: 528.939 s]
Range (min … max): 34.049 s … 35.388 s 10 runs
Summary
' ./bench2.sh ' ran
11.33 ± 0.16 times faster than ' ./bench1.sh ' 

