findlargedir
0.9.1

(Ferris the Detective von Esther Arzola, Originaldesign von Karen Rustad Tölva)
Findlargedir ist ein Tool, das speziell geschrieben wurde, um schnell "Schwarze Loch" Verzeichnisse auf einem Dateisystem mit mehr als 100.000 Einträgen in einer einzelnen flachen Struktur zu identifizieren. Wenn ein Verzeichnis über viele Einträge (Verzeichnisse oder Dateien) verfügt, wird das Erhalten der Verzeichnisliste immer langsamer und beeinflusst die Leistung aller Prozesse, die versuchen, eine Verzeichnisliste zu erhalten (zum Beispiel zum Löschen einiger Dateien und/oder um bestimmte Dateien zu finden). Prozesse Das Lesen großer Verzeichnis -Inodes werden dabei gefroren und landen länger und länger in den ununterbrochenen Schlaf ("D". Abhängig vom Dateisystem kann dies mit 100.000 Einträgen sichtbar werden und ist ein sehr merklicher Leistungsauswirkungen bei 1M+ Einträgen.
Solche Verzeichnisse können meist nicht zurückkehren, selbst wenn der Inhalt aufgeräumt wird, da die meisten Linux- und UN*X -Dateisysteme kein Verkleinern des Verzeichnisses unterstützen (zum Beispiel sehr häufig ext3/ext4). Dies geschieht häufig mit vergessenen Websitzungen (PHP Sessions -Ordner, in dem das GC -Intervall auf mehrere Tage konfiguriert wurde), verschiedene Cache -Ordner (CMS -kompilierte Vorlagen und Caches), POSIX -Dateisystem -Emulationsobjektspeicher usw.
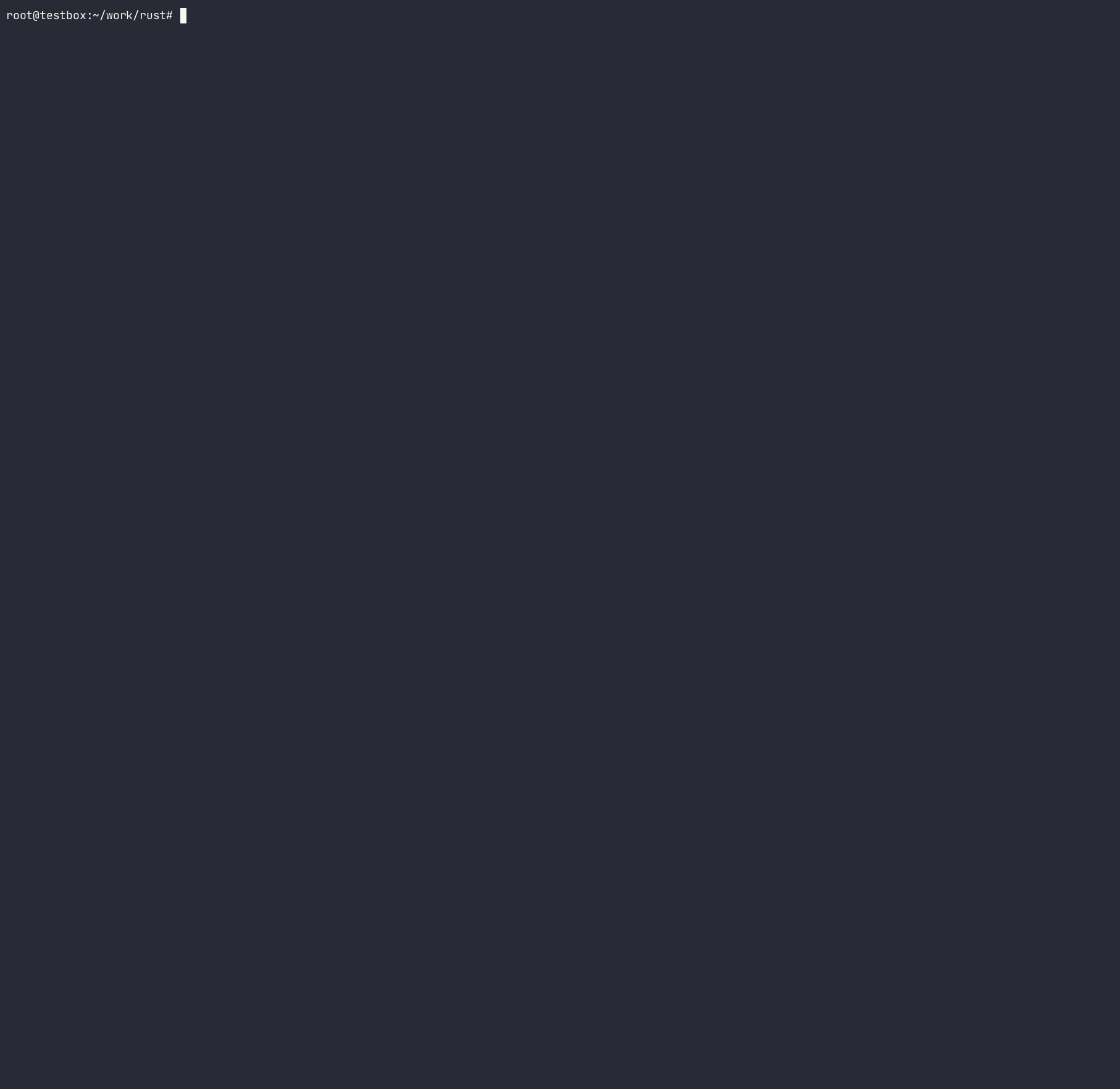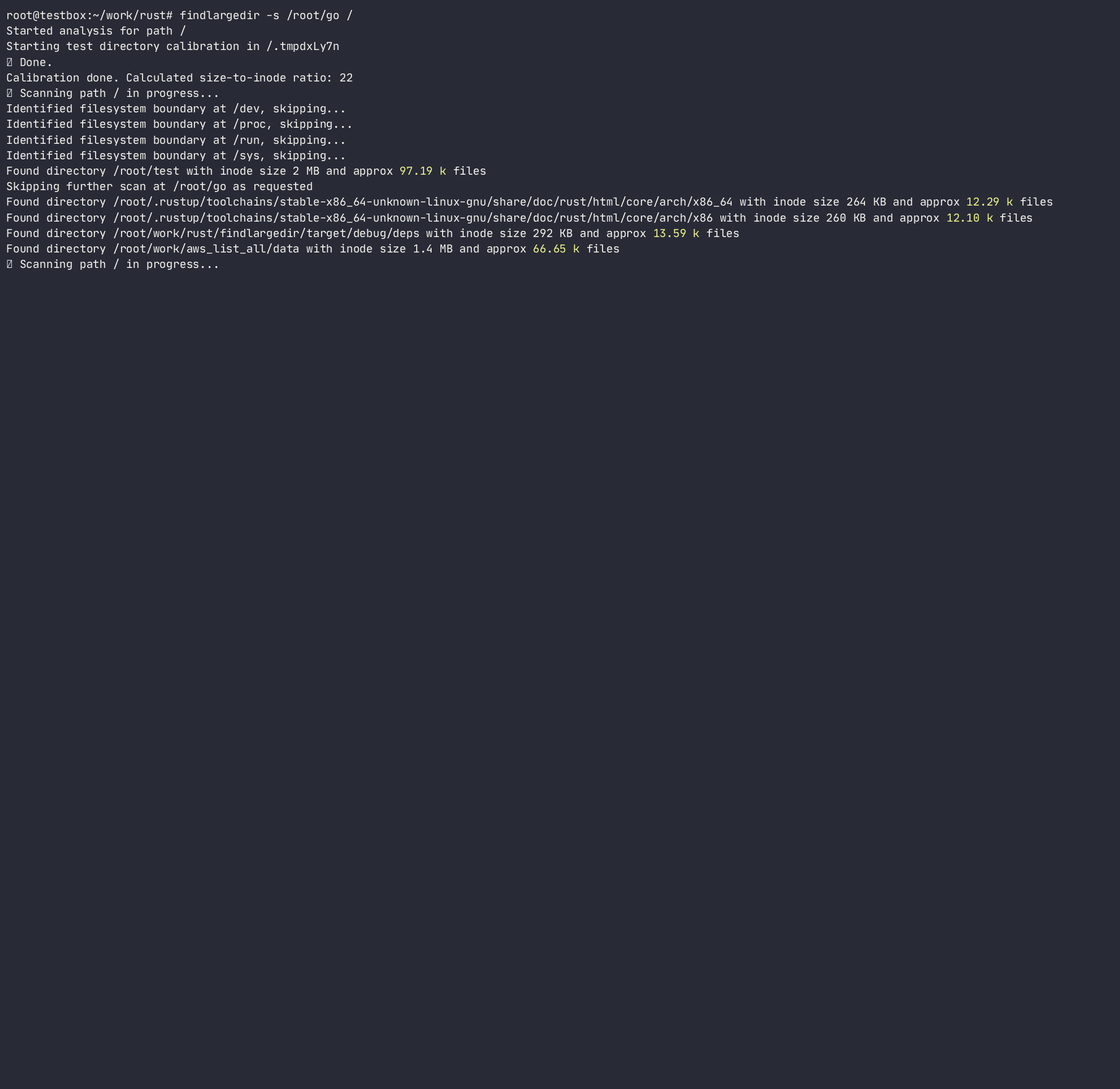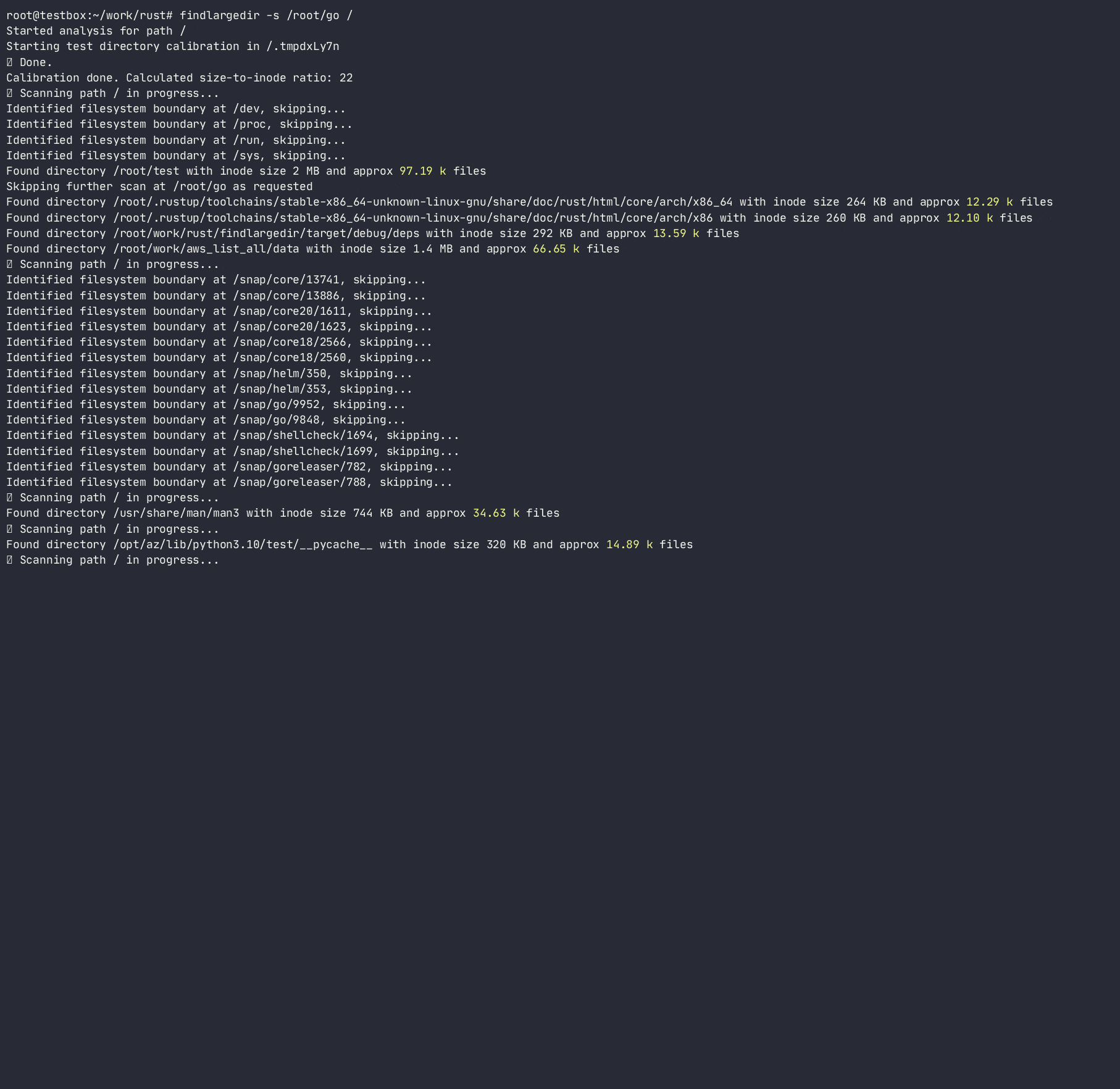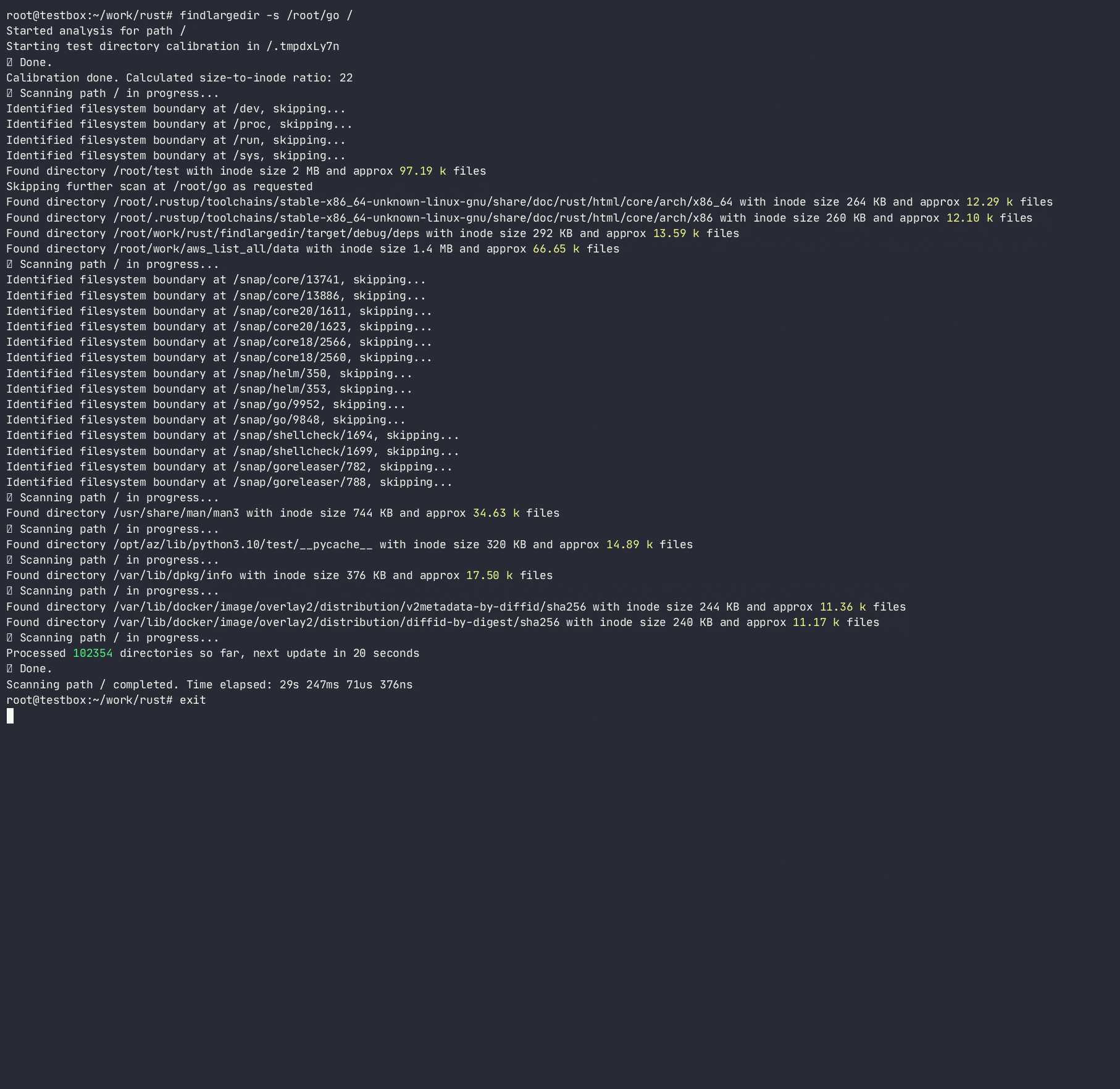
Das Programm wird versuchen, eine beliebige Anzahl solcher Ereignisse zu identifizieren und auf der Grundlage der Kalibrierung zu melden, dh. Wie viele angenommene Verzeichniseinträge sind in jedem Verzeichnis -Inode für jedes Dateisystem verpackt. Dabei bestimmt es das Verhältnis von Verzeichniskolben für die Anzahl der Einträge/Inodes und verwendet dieses Verhältnis, um das Dateisystem schnell zu scannen, wodurch teure/langsame Verzeichnis -Lookups durchgeführt werden. Während es viele Tools gibt, die das Dateisystem scannen ( find , du , ncdu usw.), verwendet keiner von ihnen Heuristiken, um teure Suchen zu vermeiden, da sie so konzipiert sind, dass sie vollständig genau sind, während dieses Tool Heuristiken und Alarms zu Problemen verwenden soll , ohne an problematischen Ordnern festzuhalten .
Das Programm folgt nicht den Symlinks und erfordert R/W -Berechtigungen, um das Verzeichnis zu kalibrieren, um eine Inode -Größe des Verzeichnisses auf die Anzahl der Einträge zu berechnen und eine Reihe von Einträgen in einem Verzeichnis zu schätzen, ohne sie tatsächlich zu zählen. Während diese Methode nur eine Annäherung an die tatsächliche Anzahl von Einträgen in einem Verzeichnis ist, ist es gut genug, um schnell nach Beleidigung Verzeichnissen zu scannen.
-a ) kann einen übermäßigen E/A und einen übermäßigen Speichergebrauch verursachen. Verwenden Sie nur dann gegebenenfalls Usage: findlargedir [OPTIONS] < PATH > ...
Arguments:
< PATH > ... Paths to check for large directories
Options:
-a, --accurate < ACCURATE >
Perform accurate directory entry counting [default: false] [possible values: true, false]
-o, --one-filesystem < ONE_FILESYSTEM >
Do not cross mount points [default: true] [possible values: true, false]
-c, --calibration-count < CALIBRATION_COUNT >
Calibration directory file count [default: 100000]
-A, --alert-threshold < ALERT_THRESHOLD >
Alert threshold count (print the estimate) [default: 10000]
-B, --blacklist-threshold < BLACKLIST_THRESHOLD >
Blacklist threshold count (print the estimate and stop deeper scan) [default: 100000]
-x, --threads < THREADS >
Number of threads to use when calibrating and scanning [default: 24]
-p, --updates < UPDATES >
Seconds between status updates, set to 0 to disable [default: 20]
-i, --size-inode-ratio < SIZE_INODE_RATIO >
Skip calibration and provide directory entry to inode size ratio (typically ~ 21-32) [default: 0]
-t, --calibration-path < CALIBRATION_PATH >
Custom calibration directory path
-s, --skip-path < SKIP_PATH >
Directories to exclude from scanning
-h, --help
Print help information
-V, --version
Print version information Bei Verwendung des genauen Modus ( -a -Parameters) achten Sie darauf, dass große Verzeichnis -Lookups den Prozess für längere Zeiträume vollständig halten. Was dieser Modus tut, ist im Grunde genommen ein sekundärer vollständig genauer Durchgang auf einem möglicherweise beleidigenden Verzeichnis, das die genaue Anzahl von Einträgen berechnet.
Um zu vermeiden, dass Sie in montierte Dateisysteme einherziehen (wie in der Option Find -xdev), wird der Parameter One -Filesystem -Modus ( -o -Parameter) standardmäßig umgeschaltet, kann jedoch bei Bedarf deaktiviert werden.
Es ist möglich, die Kalibrierungsphase vollständig zu überspringen, indem Verzeichnis -Inode -Größe zu Anzahl der Einträge mit -i -Parameter manuell bereitgestellt wird. Es ist nur sinnvoll, wenn Sie das Verhältnis bereits kennen, zum Beispiel aus früheren Läufen.
Das Einstellen -p -Parameter auf 0 verhindert das Programm daran, gelegentliche Statusaktualisierungen anzugeben.
Hardware: 8-Core Xeon E5-1630 mit 4-Drive SATA RAID-10
Benchmark -Setup:
$ cat bench1.sh
#! /bin/dash
exec /usr/bin/find / -xdev -type d -size +200000c
$ cat bench2.sh
#! /bin/dash
exec /usr/local/sbin/findlargedir /Tatsächliche Ergebnisse mit Hyperfein gemessen:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 357.040 s ± 7.176 s [User: 2.324 s, System: 13.881 s]
Range (min … max): 349.639 s … 367.636 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 199.751 s ± 4.431 s [User: 75.163 s, System: 141.271 s]
Range (min … max): 190.136 s … 203.432 s 10 runs
Summary
' ./bench2.sh ' ran
1.79 ± 0.05 times faster than ' ./bench1.sh ' Hardware: 48-Core Xeon Silver 4214, 7-Drive SM883 SATA HW RAID-5-Array, 2 TB-Inhalt (Dutzend Container mit kleinen Dateien)
Gleiches Benchmark -Setup. Ergebnisse:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 392.433 s ± 1.952 s [User: 16.056 s, System: 81.994 s]
Range (min … max): 390.284 s … 395.732 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 34.650 s ± 0.469 s [User: 79.441 s, System: 528.939 s]
Range (min … max): 34.049 s … 35.388 s 10 runs
Summary
' ./bench2.sh ' ran
11.33 ± 0.16 times faster than ' ./bench1.sh ' 

