findlargedir
0.9.1

(Ferris el detective de Esther Arzola, diseño original de Karen Rustad Tölva)
FindLargedir es una herramienta específicamente escrita para ayudar a identificar rápidamente los directorios de "agujeros negros" en un sistema de archivos que tenga más de 100k entradas en una sola estructura plana. Cuando un directorio tiene muchas entradas (directorios o archivos), obtener la lista de directorio se vuelve más lento y más lento, lo que afecta el rendimiento de todos los procesos que intentan obtener una lista de directorio (por ejemplo, para eliminar algunos archivos y/o encontrar algunos archivos específicos). Procesos que leen grandes inodos de directorio se congelan mientras lo hacen y terminan en el sueño ininterrumpido (estado "D") durante períodos de tiempo más y más largos. Dependiendo del sistema de archivos, esto podría comenzar a ser visible con entradas de 100k y comienza a ser un impacto de rendimiento muy notable con entradas de 1M+.
Dichos directorios no pueden retroceder en su mayoría, incluso si el contenido se limpia debido al hecho de que la mayoría de los sistemas de archivos Linux y Un*X no admiten la reducción del inodoro del directorio (por ejemplo, muy común Ext3/Ext4). Esto a menudo sucede con el directorio de sesiones web olvidadas (carpeta de sesiones de PHP donde el intervalo GC se configuró a varios días), varias carpetas de caché (plantillas y cachés compilados de CMS), el sistema de archivos POSIX que emulan el almacenamiento de objetos, etc.
El programa intentará identificar cualquier número de tales eventos e informar sobre ellos según la calibración , es decir. ¿Cuántas entradas de directorio supuestas se empaquetan en cada inodo de directorio para cada sistema de archivos? Al hacerlo, determinará la relación de crecimiento de inodo de directorio en el número de entradas/inodos y utilizará esa relación para escanear rápidamente el sistema de archivos, evitando hacer búsquedas de directorio costosas/lentas. Si bien hay muchas herramientas que escanean el sistema de archivos ( find , du , ncdu , etc.), ninguna de ellas usa heurísticas para evitar búsquedas costosas, ya que están diseñadas para ser completamente precisas , mientras que esta herramienta está destinada a usar heurística y alerta sobre problemas sin atascarse en carpetas problemáticas.
El programa no seguirá los enlaces simbólicos y requiere permisos de R/W para calibrar el directorio para poder calcular un tamaño de inodo de directorio a número de entradas y estimar una serie de entradas en un directorio sin contarlas realmente. Si bien este método es solo una aproximación del número real de entradas en un directorio, es lo suficientemente bueno para escanear rápidamente los directorios ofensivos.
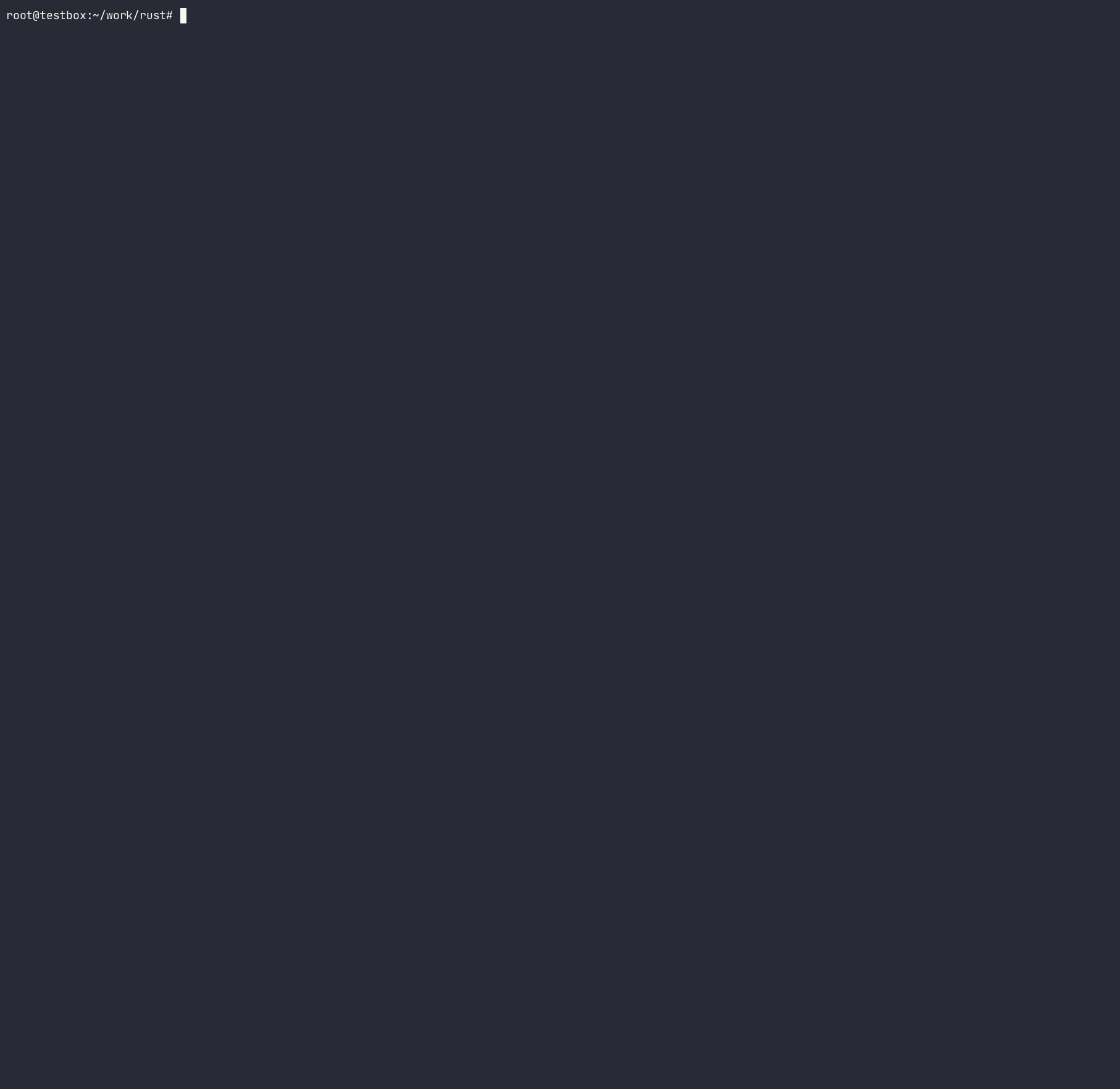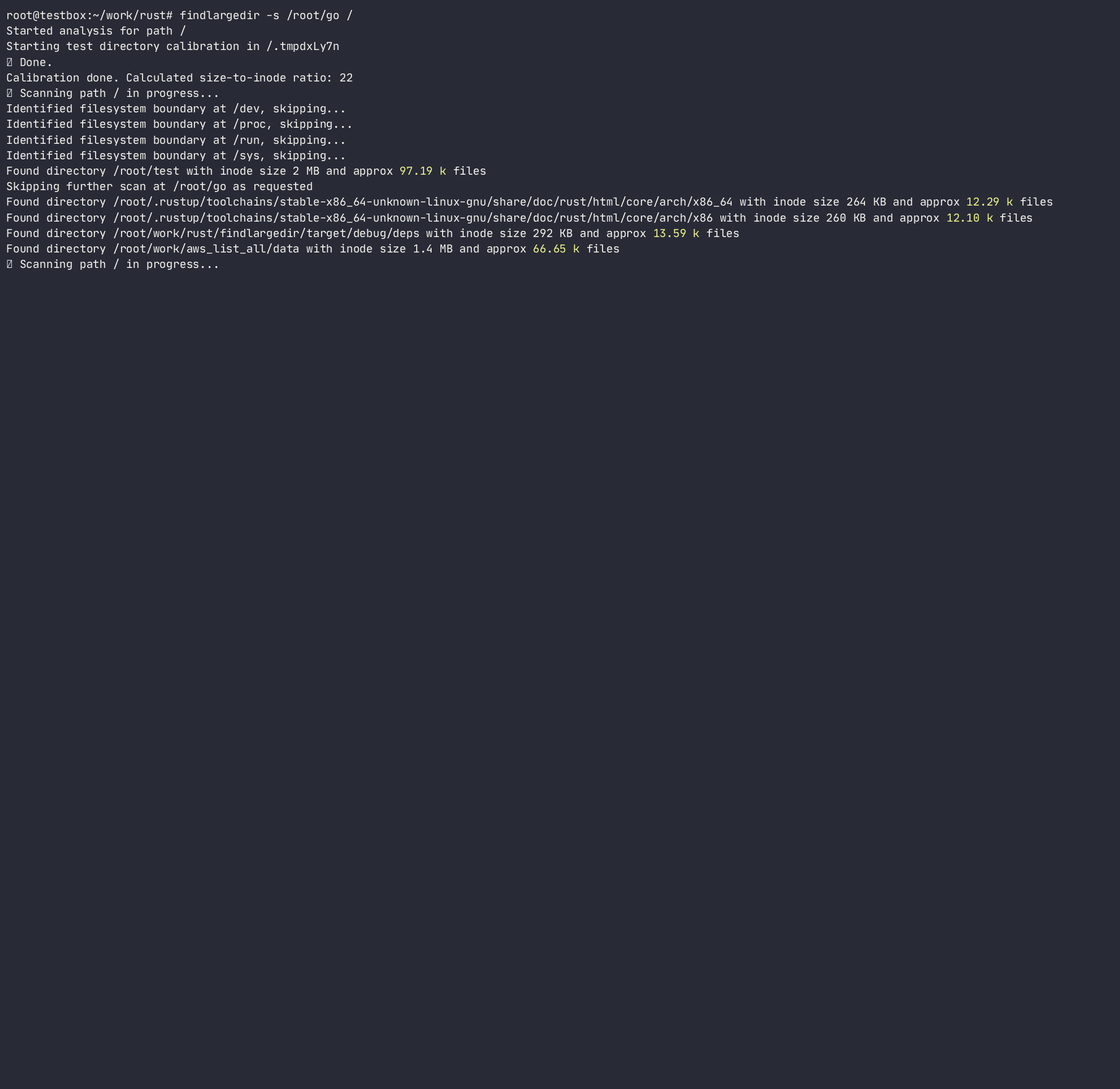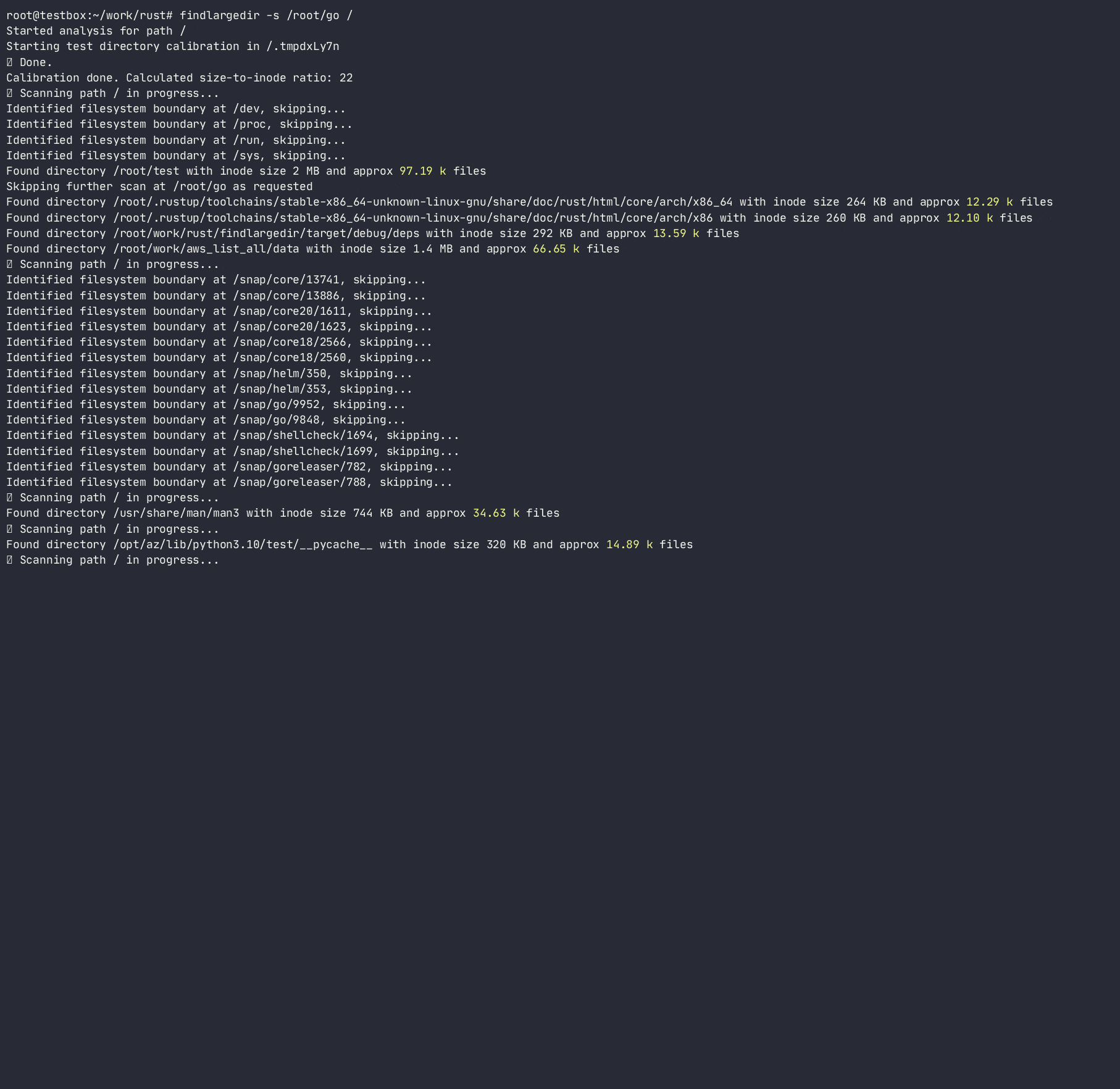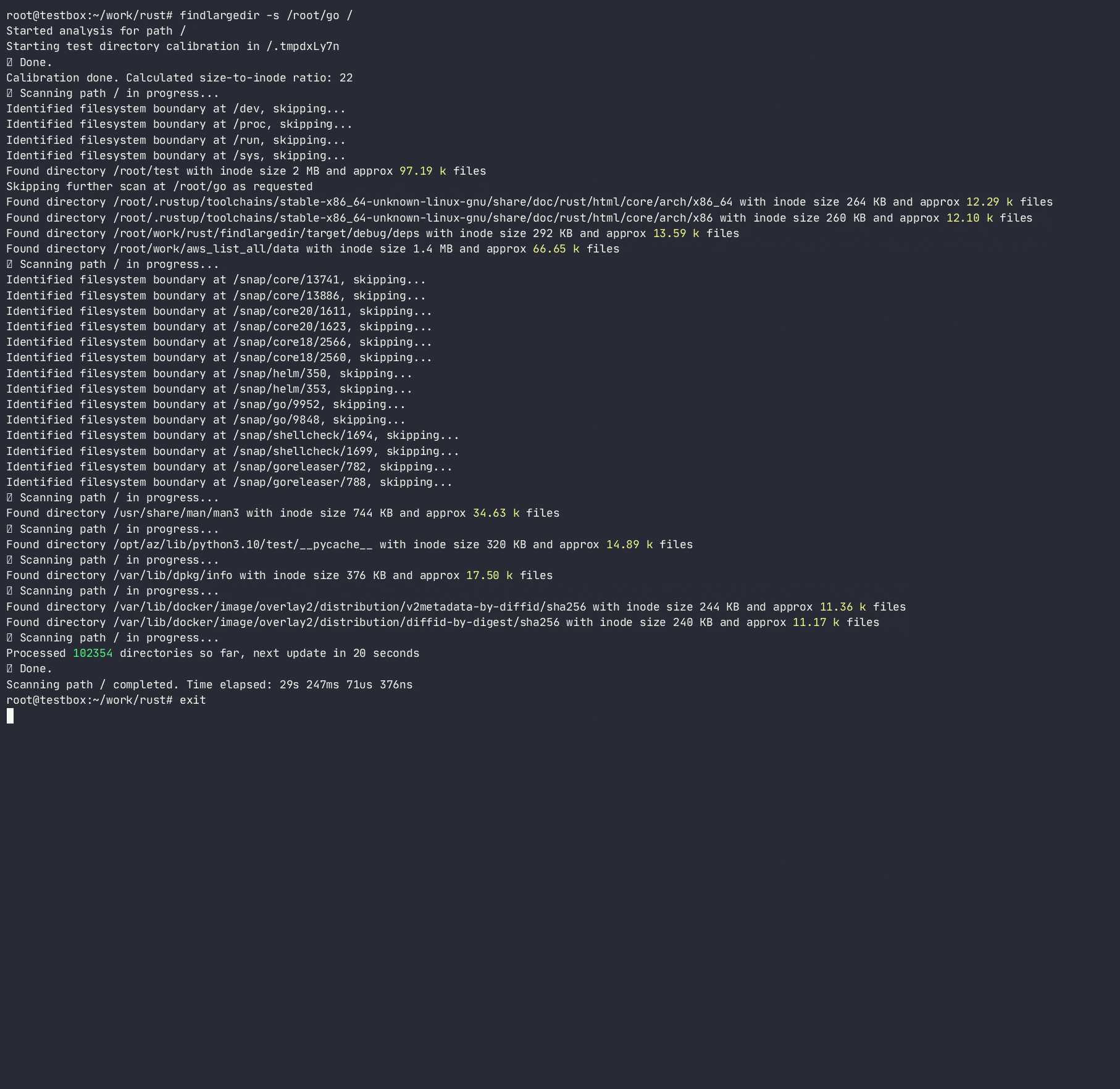
-a ) puede causar una E/S excesiva y un uso excesivo de memoria; Solo use cuando sea apropiado Usage: findlargedir [OPTIONS] < PATH > ...
Arguments:
< PATH > ... Paths to check for large directories
Options:
-a, --accurate < ACCURATE >
Perform accurate directory entry counting [default: false] [possible values: true, false]
-o, --one-filesystem < ONE_FILESYSTEM >
Do not cross mount points [default: true] [possible values: true, false]
-c, --calibration-count < CALIBRATION_COUNT >
Calibration directory file count [default: 100000]
-A, --alert-threshold < ALERT_THRESHOLD >
Alert threshold count (print the estimate) [default: 10000]
-B, --blacklist-threshold < BLACKLIST_THRESHOLD >
Blacklist threshold count (print the estimate and stop deeper scan) [default: 100000]
-x, --threads < THREADS >
Number of threads to use when calibrating and scanning [default: 24]
-p, --updates < UPDATES >
Seconds between status updates, set to 0 to disable [default: 20]
-i, --size-inode-ratio < SIZE_INODE_RATIO >
Skip calibration and provide directory entry to inode size ratio (typically ~ 21-32) [default: 0]
-t, --calibration-path < CALIBRATION_PATH >
Custom calibration directory path
-s, --skip-path < SKIP_PATH >
Directories to exclude from scanning
-h, --help
Print help information
-V, --version
Print version information Cuando use el modo preciso ( -a parámetro), tenga cuidado de que las grandes búsquedas de directorio detendrán el proceso por completo por períodos prolongados de tiempo. Lo que hace este modo es básicamente un pase secundario totalmente preciso en un directorio posiblemente ofensivo que calcula el número exacto de entradas.
Para evitar descender a los sistemas de archivos montados (como en la opción Find -xDev), el modo de sistema de parámetros (parámetro -o ) se alternan de forma predeterminada, pero se puede deshabilitar si es necesario.
Es posible omitir completamente la fase de calibración proporcionando manualmente el tamaño de inodo de directorio a la relación número de entradas con el parámetro -i . Tiene sentido solo cuando ya conoces la relación, por ejemplo de las ejecuciones anteriores.
Configuración -p Paramter en 0 evitará que el programa proporcione actualizaciones ocasionales de estado.
Hardware: Xeon E5-1630 de 8 núcleos con SATA RAID-10 de 4 drenaciones
Configuración de referencia:
$ cat bench1.sh
#! /bin/dash
exec /usr/bin/find / -xdev -type d -size +200000c
$ cat bench2.sh
#! /bin/dash
exec /usr/local/sbin/findlargedir /Resultados reales medidos con hiperfina:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 357.040 s ± 7.176 s [User: 2.324 s, System: 13.881 s]
Range (min … max): 349.639 s … 367.636 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 199.751 s ± 4.431 s [User: 75.163 s, System: 141.271 s]
Range (min … max): 190.136 s … 203.432 s 10 runs
Summary
' ./bench2.sh ' ran
1.79 ± 0.05 times faster than ' ./bench1.sh ' Hardware: Xeon Silver 4214 de 48 núcleos, matriz SM883 SATA HW RAID-5, contenido de 2 TB (docena de contenedores con archivos pequeños)
Misma configuración de referencia. Resultados:
$ hyperfine --prepare ' echo 3 | tee /proc/sys/vm/drop_caches '
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 392.433 s ± 1.952 s [User: 16.056 s, System: 81.994 s]
Range (min … max): 390.284 s … 395.732 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 34.650 s ± 0.469 s [User: 79.441 s, System: 528.939 s]
Range (min … max): 34.049 s … 35.388 s 10 runs
Summary
' ./bench2.sh ' ran
11.33 ± 0.16 times faster than ' ./bench1.sh ' 

