HarvestText
V0.8
HarvestText: инструментарий для добычи текста и предварительной обработки
документ
Синхронизировать на GitHub и Code Cloud Gitee. Если вы просматриваете/загрузите на GitHub, вы можете перейти в Code Cloud для работы.
HarvestText - это библиотека, которая фокусируется на (слабом) методе надзора, который интегрирует знания об области (таких как типы, псевдоним) для обработки и анализа конкретных доменных текстов просто и эффективно. Он подходит для многих задач предварительной обработки текста и предварительного исследовательского анализа, а также имеет потенциальную ценность приложения в новом анализе, онлайн -тексте, профессиональной литературе и других областях.
Примеры использования:
[Примечание: эта библиотека завершает только сегментацию слова и анализ настроений и использует Matplotlib для визуализации]
Этот Readme содержит типичные примеры различных функций. Подробное использование некоторых функций можно найти в документации:
документ
Конкретные функции следующие:
Оглавление:
Первая установка, используйте PIP
pip install --upgrade harvesttextИли введите каталог, где находится setup.py, а затем командная строка:
python setup.py installЗатем в коде:
from harvesttext import HarvestText
ht = HarvestText ()Вы можете вызвать функциональный интерфейс этой библиотеки.
Примечание. Некоторые функции требуют установки дополнительных библиотек, но установка может сбой, поэтому, пожалуйста, установите вручную, если это необходимо.
# 部分英语功能
pip install pattern
# 命名实体识别、句法分析等功能,需要python <= 3.8
pip install pyhanlpУчитывая определенные сущности и их возможные синонимы, а также сущность соответствующего типа. Зарегистрируйте его в словаре, сначала разделите его при расстановке слов и используйте соответствующий тип как часть речи. Все организации и их местоположения в корпусе также могут быть получены отдельно:
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
entity_mention_dict = { '武磊' :[ '武磊' , '武球王' ], '郜林' :[ '郜林' , '郜飞机' ], '前锋' :[ '前锋' ], '上海上港' :[ '上港' ], '广州恒大' :[ '恒大' ], '单刀球' :[ '单刀' ]}
entity_type_dict = { '武磊' : '球员' , '郜林' : '球员' , '前锋' : '位置' , '上海上港' : '球队' , '广州恒大' : '球队' , '单刀球' : '术语' }
ht . add_entities ( entity_mention_dict , entity_type_dict )
print ( " n Sentence segmentation" )
print ( ht . seg ( para , return_sent = True )) # return_sent=False时,则返回词语列表Кто лучшие форварды в Китае, в том числе Wu Lei из Shanghai Sipg и Gao Lin of Evergrande? Конечно, это У Лей, король Ву Болла. Он первый в списке стрелков. Оказывается, слабый одиночный меч также добился прогресса.
Использование традиционных инструментов сегментации слов может легко разделить "Wuqiong King" на "Wuqiong King"
Часть речевой аннотации, включая указанные специальные типы.
print ( " n POS tagging with entity types" )
for word , flag in ht . posseg ( para ):
print ( "%s:%s" % ( word , flag ), end = " " )SIPG: Команда: UJ Wu Lei: Игроки и: C Evergrande: Команда: UJ Gao Lin: Игроки,: x Кто: R: V: V China: NS BEST: A: UJ Forward: позиция? : x Это: R Конечно: D: D: V Wu Lei: Игрок Ву Цю Кин
for span , entity in ht . entity_linking ( para ):
print ( span , entity )[0, 2] ('Shanghai sipg', '# team#') [3, 5] ('wu lei', '# player#') [6, 8] ('guangzhou evergrande', '# team#') [9, 11] ('Gao Lin', '# player#') [19, 21] ('###'# ') [26, 28] [##'# ') [28] [# 28] [#'## ') [# 28] [# 28] [# 28] [#'# ') [19, 21] (#'# '#') [# 28] [# ') [28, 31] ('wu lei', '# player#') [47, 49] ('один на один мяч', '# term#')
Здесь трансформация «wuqiu king» в стандартный термин «wu lei» может способствовать объединенной статистической работе.
Предложение:
print ( ht . cut_sentences ( para ))[Кто лучший форвард в Китае от Шанхай Сипг и Гао Лин из Evergrande? ', «Конечно, это футбольный король Wu Lei's Wu. Он первый в списке стрелков. Оказывается, слабый одиночный меч также добился прогресса »]
Если на данный момент под рукой нет словарного слова, вы можете также посмотреть, подходит ли домен в встроенных ресурсах этой библиотеки для ваших нужд.
Если есть несколько возможных сущностей для одного и того же имени («Li na играет в мяч и пение Li na - это не один и тот же человек»), вы можете установить keep_all=True , чтобы сохранить несколько кандидатов. Вы можете использовать другие стратегии для устранения дискомогущих позже, см. EL_PEEP_ALL ()
Если связано слишком много сущностей, некоторые из которых явно неразумны, некоторые стратегии могут быть использованы для фильтрации. Вот пример filter_el_with_rule ()
Эта библиотека также может использовать некоторые базовые стратегии для решения сложных задач неоднозначности сущности (например, многочисленные значения слова [«Учитель» относится к «учителю» или «учителю B»?], И слова кандидата перекрываются [мэр XX/Jiang Yy?, Мэр XX/Jiang Yy?]). Для получения подробной информации вы можете увидеть Linking_strategy ()
Вы можете обрабатывать специальные символы в тексте или удалить некоторые специальные форматы, которые вы не хотите появляться в тексте.
В том числе: @, эмодзи на Вейбо; URL; электронная почта; Специальные символы в HTML -коде; Специальные персонажи в %20 в URL; Традиционный китайский для упрощенного китайца
Примеры следующие:
print ( "各种清洗文本" )
ht0 = HarvestText ()
# 默认的设置可用于清洗微博文本
text1 = "回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]"
print ( "清洗微博【@和表情符等】" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 ))各种清洗文本
清洗微博【@和表情符等】
原: 回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]
清洗后: 杨大哥
# URL的清理
text1 = "【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ"
print ( "清洗网址URL" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , remove_url = True ))清洗网址URL
原: 【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ
清洗后: 【#赵薇#:正筹备下一部电影 但不是青春片....
# 清洗邮箱
text1 = "我的邮箱是[email protected],欢迎联系"
print ( "清洗邮箱" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , email = True ))清洗邮箱
原: 我的邮箱是[email protected],欢迎联系
清洗后: 我的邮箱是,欢迎联系
# 处理URL转义字符
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print ( "URL转正常字符" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , norm_url = True , remove_url = False )) URL转正常字符
原: www.%E4%B8%AD%E6%96%87%20and%20space.com
清洗后: www.中文 and space.com
text1 = "www.中文 and space.com"
print ( "正常字符转URL[含有中文和空格的request需要注意]" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , to_url = True , remove_url = False ))正常字符转URL[含有中文和空格的request需要注意]
原: www.中文 and space.com
清洗后: www.%E4%B8%AD%E6%96%87%20and%20space.com
# 处理HTML转义字符
text1 = "<a c> ''"
print ( "HTML转正常字符" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , norm_html = True )) HTML转正常字符
原: <a c> ''
清洗后: <a c> ''
# 繁体字转简体
text1 = "心碎誰買單"
print ( "繁体字转简体" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , t2s = True ))繁体字转简体
原: 心碎誰買單
清洗后: 心碎谁买单
# markdown超链接提取文本
text1 = "欢迎使用[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)这个库"
print ( "markdown超链接提取文本" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , t2s = True )) markdown超链接提取文本
原: 欢迎使用[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)这个库
清洗后: 欢迎使用HarvestText : A Toolkit for Text Mining and Preprocessing这个库
Найдите имя человека, места, организации и т. Д. В предложении. Используется реализация интерфейса PYHANLP.
ht0 = HarvestText ()
sent = "上海上港足球队的武磊是中国最好的前锋。"
print ( ht0 . named_entity_recognition ( sent )) {'上海上港足球队': '机构名', '武磊': '人名', '中国': '地名'}
Проанализируйте модификацию объекта объекта и другие грамматические отношения каждого слова в утверждении (включая сущность, связанную с) и извлеките возможные тройки события. Используется реализация интерфейса PYHANLP.
ht0 = HarvestText ()
para = "上港的武磊武球王是中国最好的前锋。"
entity_mention_dict = { '武磊' : [ '武磊' , '武球王' ], "上海上港" :[ "上港" ]}
entity_type_dict = { '武磊' : '球员' , "上海上港" : "球队" }
ht0 . add_entities ( entity_mention_dict , entity_type_dict )
for arc in ht0 . dependency_parse ( para ):
print ( arc )
print ( ht0 . triple_extraction ( para )) [0, '上港', '球队', '定中关系', 3]
[1, '的', 'u', '右附加关系', 0]
[2, '武磊', '球员', '定中关系', 3]
[3, '武球王', '球员', '主谓关系', 4]
[4, '是', 'v', '核心关系', -1]
[5, '中国', 'ns', '定中关系', 8]
[6, '最好', 'd', '定中关系', 8]
[7, '的', 'u', '右附加关系', 6]
[8, '前锋', 'n', '动宾关系', 4]
[9, '。', 'w', '标点符号', 4]
print ( ht0 . triple_extraction ( para )) [['上港武磊武球王', '是', '中国最好前锋']]
Модифицировано в версии v0.7, используйте толерантность, чтобы поддержать ту же проверку пинкина
Свяжите слова в утверждении, который может быть известной сущностью (с одним символом или ошибкой пинкина) с соответствующей сущностью.
def entity_error_check ():
ht0 = HarvestText ()
typed_words = { "人名" :[ "武磊" ]}
ht0 . add_typed_words ( typed_words )
sent0 = "武磊和吴磊拼音相同"
print ( sent0 )
print ( ht0 . entity_linking ( sent0 , pinyin_tolerance = 0 ))
"""
武磊和吴磊拼音相同
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent1 = "武磊和吴力只差一个拼音"
print ( sent1 )
print ( ht0 . entity_linking ( sent1 , pinyin_tolerance = 1 ))
"""
武磊和吴力只差一个拼音
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent2 = "武磊和吴磊只差一个字"
print ( sent2 )
print ( ht0 . entity_linking ( sent2 , char_tolerance = 1 ))
"""
武磊和吴磊只差一个字
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent3 = "吴磊和吴力都可能是武磊的代称"
print ( sent3 )
print ( ht0 . get_linking_mention_candidates ( sent3 , pinyin_tolerance = 1 , char_tolerance = 1 ))
"""
吴磊和吴力都可能是武磊的代称
('吴磊和吴力都可能是武磊的代称', defaultdict(<class 'list'>, {(0, 2): {'武磊'}, (3, 5): {'武磊'}}))
"""Эта библиотека использует метод эмоционального словаря для проведения анализа эмоций и автоматически изучает эмоциональные тенденции других слов из корпуса, предоставляя небольшое количество стандартных положительных и негативных слов («семенные слова») для формирования эмоционального словаря. Суммирование и среднее значение эмоциональных слов в куплете используются для оценки эмоциональной тенденции предложения:
print ( " n sentiment dictionary" )
sents = [ "武磊威武,中超第一射手!" ,
"武磊强,中超最第一本土球员!" ,
"郜林不行,只会抱怨的球员注定上限了" ,
"郜林看来不行,已经到上限了" ]
sent_dict = ht . build_sent_dict ( sents , min_times = 1 , pos_seeds = [ "第一" ], neg_seeds = [ "不行" ])
print ( "%s:%f" % ( "威武" , sent_dict [ "威武" ]))
print ( "%s:%f" % ( "球员" , sent_dict [ "球员" ]))
print ( "%s:%f" % ( "上限" , sent_dict [ "上限" ]))Словарь настроений: 1.000000 Игрок: 0,000000 Cap: -1,0000000
print ( " n sentence sentiment" )
sent = "武球王威武,中超最强球员!"
print ( "%f:%s" % ( ht . analyse_sent ( sent ), sent ))0,600000: Король боевых искусств могущественен и самый сильный игрок в китайской Суперлиге!
Если вы не выяснили, какие слова выбрать в качестве «семенных слов», эта библиотека также имеет встроенный ресурс для общего эмоционального словаря, который является выбором по умолчанию, когда не указывает эмоциональные слова, и вы также можете выбрать их по мере необходимости.
Алгоритм SO-PMI, используемый по умолчанию, не имеет верхних и нижних ограничений на эмоциональные значения. Если это должно быть ограничено интервалами, такими как [0,1] или [-1,1], вы можете настроить параметры масштаба. Примеры следующие:
print ( " n sentiment dictionary using default seed words" )
docs = [ "张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资" ,
"打倒万恶的资本家" ,
"该公司原定资本总额为二十五万万元,现已由各界分认达二十万万元,所属各厂、各公司亦募得股金一万万余元" ,
"连日来解放区以外各工商人士,投函向该公司询问经营性质与范围以及股东权限等问题者甚多,络绎抵此的许多资本家,于参观该公司所属各厂经营状况后,对民主政府扶助与奖励私营企业发展的政策,均极表赞同,有些资本家因款项未能即刻汇来,多向筹备处预认投资的额数。由平津来张的林明棋先生,一次即以现款入股六十余万元"
]
# scale: 将所有词语的情感值范围调整到[-1,1]
# 省略pos_seeds, neg_seeds,将采用默认的情感词典 get_qh_sent_dict()
print ( "scale= " 0-1 " , 按照最大为1,最小为0进行线性伸缩,0.5未必是中性" )
sent_dict = ht . build_sent_dict ( docs , min_times = 1 , scale = "0-1" )
print ( "%s:%f" % ( "赞同" , sent_dict [ "赞同" ]))
print ( "%s:%f" % ( "二十万" , sent_dict [ "二十万" ]))
print ( "%s:%f" % ( "万恶" , sent_dict [ "万恶" ]))
print ( "%f:%s" % ( ht . analyse_sent ( docs [ 0 ]), docs [ 0 ]))
print ( "%f:%s" % ( ht . analyse_sent ( docs [ 1 ]), docs [ 1 ])) sentiment dictionary using default seed words
scale="0-1", 按照最大为1,最小为0进行线性伸缩,0.5未必是中性
赞同:1.000000
二十万:0.153846
万恶:0.000000
0.449412:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
0.364910:打倒万恶的资本家
print("scale="+-1", 在正负区间内分别伸缩,保留0作为中性的语义")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="+-1")
print("%s:%f" % ("赞同",sent_dict["赞同"]))
print("%s:%f" % ("二十万",sent_dict["二十万"]))
print("%s:%f" % ("万恶",sent_dict["万恶"]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))
scale="+-1", 在正负区间内分别伸缩,保留0作为中性的语义
赞同:1.000000
二十万:0.000000
万恶:-1.000000
0.349305:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
-0.159652:打倒万恶的资本家
Вы можете найти документы, содержащие соответствующую сущность (и его псевдоним) из списка документов, и подсчитать количество документов, содержащих объект. Используйте структуру данных с инвертированными индексами, чтобы завершить быстрый поиск.
Следующий код - это отрыв из процесса добавления объектов. Пожалуйста, используйте такие функции, как ADD_ENTITIES, чтобы добавить сущность, на которую вы хотите обратить внимание, а затем индекс и поиск.
docs = [ "武磊威武,中超第一射手!" ,
"郜林看来不行,已经到上限了。" ,
"武球王威武,中超最强前锋!" ,
"武磊和郜林,谁是中国最好的前锋?" ]
inv_index = ht . build_index ( docs )
print ( ht . get_entity_counts ( docs , inv_index )) # 获得文档中所有实体的出现次数
# {'武磊': 3, '郜林': 2, '前锋': 2}
print ( ht . search_entity ( "武磊" , docs , inv_index )) # 单实体查找
# ['武磊威武,中超第一射手!', '武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
print ( ht . search_entity ( "武磊 郜林" , docs , inv_index )) # 多实体共现
# ['武磊和郜林,谁是中国最好的前锋?']
# 谁是最被人们热议的前锋?用这里的接口可以很简便地回答这个问题
subdocs = ht . search_entity ( "#球员# 前锋" , docs , inv_index )
print ( subdocs ) # 实体、实体类型混合查找
# ['武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
inv_index2 = ht . build_index ( subdocs )
print ( ht . get_entity_counts ( subdocs , inv_index2 , used_type = [ "球员" ])) # 可以限定类型
# {'武磊': 2, '郜林': 1}(Реализовано с использованием NetworkX) Используйте отношения ко-поступления Word, чтобы установить сетевые отношения между структурами графиков между телами (вернуться к типу NetworkX.Graph). Его можно использовать для создания социальных сетей между персонажами и т. Д.
# 在现有实体库的基础上随时新增,比如从新词发现中得到的漏网之鱼
ht . add_new_entity ( "颜骏凌" , "颜骏凌" , "球员" )
docs = [ "武磊和颜骏凌是队友" ,
"武磊和郜林都是国内顶尖前锋" ]
G = ht . build_entity_graph ( docs )
print ( dict ( G . edges . items ()))
G = ht . build_entity_graph ( docs , used_types = [ "球员" ])
print ( dict ( G . edges . items ()))Получить сеть слов, ориентированную на слово. Возьмите первую главу «Три королевства» в качестве примера, чтобы исследовать встречу главного героя Лю Бей (например, основной код, см.
entity_mention_dict , entity_type_dict = get_sanguo_entity_dict ()
ht0 . add_entities ( entity_mention_dict , entity_type_dict )
sanguo1 = get_sanguo ()[ 0 ]
stopwords = get_baidu_stopwords ()
docs = ht0 . cut_sentences ( sanguo1 )
G = ht0 . build_word_ego_graph ( docs , "刘备" , min_freq = 3 , other_min_freq = 2 , stopwords = stopwords )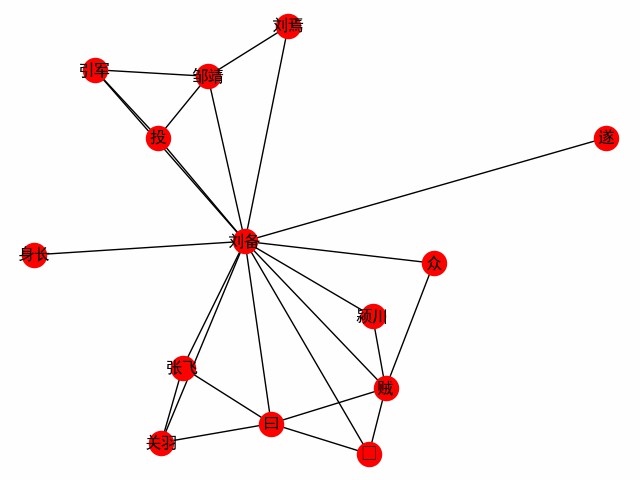
Это дружба между Лю, Гуансом и Чжаном, спонсором, которого дефекция Лю Бей, и опытом Лю Бей в борьбе с ворами.
(Реализовано с использованием NetworkX) Используйте алгоритм текстового текста для получения извлеченных репрезентативных предложений из сбора документов в качестве сводной информации. Вы можете установить предложения, которые наказывают дубликаты, или вы можете установить пределы слов (параметр maxlen):
print ( " n Text summarization" )
docs = [ "武磊威武,中超第一射手!" ,
"郜林看来不行,已经到上限了。" ,
"武球王威武,中超最强前锋!" ,
"武磊和郜林,谁是中国最好的前锋?" ]
for doc in ht . get_summary ( docs , topK = 2 ):
print ( doc )
print ( " n Text summarization(避免重复)" )
for doc in ht . get_summary ( docs , topK = 3 , avoid_repeat = True ):
print ( doc ) Text summarization
武球王威武,中超最强前锋!
武磊威武,中超第一射手!
Text summarization(避免重复)
武球王威武,中超最强前锋!
郜林看来不行,已经到上限了。
武磊和郜林,谁是中国最好的前锋?
В настоящее время существует два алгоритма, которые включают в себя textrank и HarvestText, чтобы инкапсулировать jieba и настройку параметров и остановить jieba_tfidf .
Пример (см. Пример для завершения):
# text为林俊杰《关键词》歌词
print ( "《关键词》里的关键词" )
kwds = ht . extract_keywords ( text , 5 , method = "jieba_tfidf" )
print ( "jieba_tfidf" , kwds )
kwds = ht . extract_keywords ( text , 5 , method = "textrank" )
print ( "textrank" , kwds ) 《关键词》里的关键词
jieba_tfidf ['自私', '慷慨', '落叶', '消逝', '故事']
textrank ['自私', '落叶', '慷慨', '故事', '位置']
CSL.IPYNB предоставляет различные алгоритмы, а также сравнение реализации этой библиотеки с TexTrank4ZH в наборе данных CSL. Поскольку существует только один набор данных, и набор данных не является дружелюбным к приведенным выше алгоритмам, производительность предназначена только для справки.
| алгоритм | P@5 | R@5 | F@5 |
|---|---|---|---|
| Textrank4ZH | 0,0836 | 0,1174 | 0,0977 |
| ht_texttransk | 0,0955 | 0,1342 | 0,1116 |
| ht_jieba_tfidf | 0,1035 | 0,1453 | 0,1209 |
Теперь некоторые ресурсы интегрированы в эту библиотеку для облегчения использования и создания демонстраций.
Ресурсы включают:
get_qh_sent_dict : Словарь соответствия и критики Ли Джун из университета Цинхуа скомпилировал его с http://nlp.csai.tsinghua.edu.cn/site2/index.php/13-smsget_baidu_stopwords : Baidu Stop Word Dictionary происходит из Интернета: https://wenku.baidu.com/view/98c46383e53a580216fcfed9.htmlget_qh_typed_words : домен словарь от tsinghua thunlp: http://thuocl.thunlp.org/ Все типы ['IT', '动物', '医药', '历史人名', '地名', '成语', '法律', '财经', '食物']get_english_senti_lexicon : английский эмоциональный словарьget_jieba_dict : (нужно скачать) Словарь частоты jieba wordКроме того, предоставляется специальный ресурс - «Романтика трех королевств», включая:
Вы можете изучить, какие интересные открытия могут быть получены из этого?
def load_resources ():
from harvesttext . resources import get_qh_sent_dict , get_baidu_stopwords , get_sanguo , get_sanguo_entity_dict
sdict = get_qh_sent_dict () # {"pos":[积极词...],"neg":[消极词...]}
print ( "pos_words:" , list ( sdict [ "pos" ])[ 10 : 15 ])
print ( "neg_words:" , list ( sdict [ "neg" ])[ 5 : 10 ])
stopwords = get_baidu_stopwords ()
print ( "stopwords:" , list ( stopwords )[ 5 : 10 ])
docs = get_sanguo () # 文本列表,每个元素为一章的文本
print ( "三国演义最后一章末16字: n " , docs [ - 1 ][ - 16 :])
entity_mention_dict , entity_type_dict = get_sanguo_entity_dict ()
print ( "刘备 指称:" , entity_mention_dict [ "刘备" ])
print ( "刘备 类别:" , entity_type_dict [ "刘备" ])
print ( "蜀 类别:" , entity_type_dict [ "蜀" ])
print ( "益州 类别:" , entity_type_dict [ "益州" ])
load_resources () pos_words: ['宰相肚里好撑船', '查实', '忠实', '名手', '聪明']
neg_words: ['散漫', '谗言', '迂执', '肠肥脑满', '出卖']
stopwords: ['apart', '左右', '结果', 'probably', 'think']
三国演义最后一章末16字:
鼎足三分已成梦,后人凭吊空牢骚。
刘备 指称: ['刘备', '刘玄德', '玄德']
刘备 类别: 人名
蜀 类别: 势力
益州 类别: 州名
Загрузите словарь поля TSINGHUA и используйте Stop Words.
def using_typed_words ():
from harvesttext . resources import get_qh_typed_words , get_baidu_stopwords
ht0 = HarvestText ()
typed_words , stopwords = get_qh_typed_words (), get_baidu_stopwords ()
ht0 . add_typed_words ( typed_words )
sentence = "THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。"
print ( sentence )
print ( ht0 . posseg ( sentence , stopwords = stopwords ))
using_typed_words () THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。
[('THUOCL', 'eng'), ('自然语言处理', 'IT'), ('一套', 'm'), ('中文', 'nz'), ('词库', 'n'), ('词表', 'n'), ('来自', 'v'), ('主流', 'b'), ('网站', 'n'), ('社会', 'n'), ('标签', '财经'), ('搜索', 'v'), ('热词', 'n'), ('输入法', 'IT'), ('词库', 'n')]
Некоторые слова дают особые типы, в то время как такие слова, как «да», экранируются.
Используйте некоторые статистические показатели, чтобы обнаружить новые слова из относительно большого количества текстов. (Необязательно) Слова, которые определяют степень качества, можно найти, предоставив несколько слов семян. (То есть, по крайней мере, все слов семян будут найдены, в предпосылке, что определенные основные требования выполнены.)
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
#返回关于新词质量的一系列信息,允许手工改进筛选(pd.DataFrame型)
new_words_info = ht . word_discover ( para )
#new_words_info = ht.word_discover(para, threshold_seeds=["武磊"])
new_words = new_words_info . index . tolist ()
print ( new_words )["Wu lei"]
Алгоритм использует эмпирические параметры по умолчанию. Если вы не удовлетворены количеством результатов, вы можете установить auto_param=False чтобы самостоятельно настроить параметры и настроить количество конечных результатов. Соответствующие параметры следующие:
:param max_word_len: 允许被发现的最长的新词长度
:param min_freq: 被发现的新词,在给定文本中需要达到的最低频率
:param min_entropy: 被发现的新词,在给定文本中需要达到的最低左右交叉熵
:param min_aggregation: 被发现的新词,在给定文本中需要达到的最低凝聚度
Например, если вы хотите получить больше результатов, чем по умолчанию (например, некоторые новые слова не обнаружены), вы можете подавить их на основе параметров по умолчанию, и следующие параметры по умолчанию:
min_entropy = np.log(length) / 10
min_freq = min(0.00005, 20.0 / length)
min_aggregation = np.sqrt(length) / 15
Подробная информация о конкретном алгоритме и значения параметров, см.
Согласно обновлению обратной связи, он первоначально принял отдельную строку по умолчанию. Теперь он также может принять ввод строковых списков, и он будет автоматически сплайсирован
Согласно обновлению обратной связи, порядок по умолчанию частоты слов теперь можно отсортировать по умолчанию. Вы также можете передать параметр sort_by='score' , чтобы сортировать по исчерпывающему баллу качества.
Многие из обнаруженных новых слов могут быть специальными ключевыми словами в тексте, поэтому новые слова могут быть введены в систему, чтобы последующие причастия давали приоритет этим словам.
def new_word_register ():
new_words = [ "落叶球" , "666" ]
ht . add_new_words ( new_words ) # 作为广义上的"新词"登录
ht . add_new_entity ( "落叶球" , mention0 = "落叶球" , type0 = "术语" ) # 作为特定类型登录
print ( ht . seg ( "这个落叶球踢得真是666" , return_sent = True ))
for word , flag in ht . posseg ( "这个落叶球踢得真是666" ):
print ( "%s:%s" % ( word , flag ), end = " " )Этот падший листовой мяч действительно 666
Это: r Leaf Ball: Term Kick: v get: ud действительно: D 666: новое слово
Вы также можете использовать некоторые специальные правила , чтобы найти требуемые ключевые слова и напрямую присваивать их типу, например, на английском, или иметь конкретные презентации и суффиксы и т. Д.
# find_with_rules()
from harvesttext . match_patterns import UpperFirst , AllEnglish , Contains , StartsWith , EndsWith
text0 = "我喜欢Python,因为requests库很适合爬虫"
ht0 = HarvestText ()
found_entities = ht0 . find_entity_with_rule ( text0 , rulesets = [ AllEnglish ()], type0 = "英文名" )
print ( found_entities )
print ( ht0 . posseg ( text0 )) {'Python', 'requests'}
[('我', 'r'), ('喜欢', 'v'), ('Python', '英文名'), (',', 'x'), ('因为', 'c'), ('requests', '英文名'), ('库', 'n'), ('很', 'd'), ('适合', 'v'), ('爬虫', 'n')]
Используйте алгоритм Texttiling для автоматического сегмента текста без сегментов или дальнейшей организации/повторного использования на основе существующих параграфов.
ht0 = HarvestText ()
text = """备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”"""
print ( "原始文本[5段]" )
print ( text + " n " )
print ( "预测文本[手动设置分3段]" )
predicted_paras = ht0 . cut_paragraphs ( text , num_paras = 3 )
print ( " n " . join ( predicted_paras ) + " n " )原始文本[5段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
预测文本[手动设置分3段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
В отличие от исходной статьи, результат предложения используется в качестве основного блока, а использование символов не является фиксированным числом, которое более семантически более четкое и сохраняет проблемы с установкой параметров. Следовательно, алгоритм под настройкой по умолчанию не поддерживает текст без пунктуации. Тем не менее, вы можете использовать настройки исходной бумаги, установив seq_chars на положительное целое число для сегмента без пунктуации. Если нет пункта, пожалуйста, установите align_boundary=False . Например, см. cut_paragraph() в examples/basic.py :
print ( "去除标点以后的分段" )
text2 = extract_only_chinese ( text )
predicted_paras2 = ht0 . cut_paragraphs ( text2 , num_paras = 5 , seq_chars = 10 , align_boundary = False )
print ( " n " . join ( predicted_paras2 ) + " n " )去除标点以后的分段
备受社会关注的湖南常德滴滴司机遇害案将于月日时许在汉寿县人民法院开庭审理此前犯罪嫌疑人岁大学生杨某淇被鉴定为作案时患有抑郁症为有
限定刑事责任能力新京报此前报道年
月日凌晨滴滴司机陈师
傅搭载岁大学生杨某淇到常南汽车总站附近坐在后排的杨某淇趁陈某不备朝陈某连捅数刀致其死亡事发监控显示杨某淇杀人后下车离开随后杨某淇
到公安机关自首并供述称因悲观厌世精神崩溃无故将司机杀害据杨某淇就读学校的工作人员称他家有四口人姐姐是聋哑人今日上午田女士告诉新京
报记者明日开庭时间不变此前已提出刑事附带民事赔偿但通过与法院的沟通后获知对方父母已经没有赔偿的意愿当时按照人身死亡赔偿金计算共计
多万元那时也想考虑对方家庭的经济状况田女士说她相信法律对最后的结果也做好心理准备对方一家从未道歉此前庭前会议中对方提
出了嫌疑人杨某淇作案时患有抑郁症的辩护意见另具警方出具的鉴定书显示嫌疑人作案时有限定刑事责任能力新京
报记者从陈师傅的家属处获知陈师傅有两个儿子大儿子今年岁小儿子还不到岁这对我来说是一起悲剧对我们生活的影响肯定是很大的田女士告诉新
京报记者丈夫遇害后他们一家的主劳动力没有了她自己带着两个孩子和两个老人一起过生活很艰辛她说还好有妹妹的陪伴现在已经好些了
Модель может быть сохранена локально и читать мультиплексирование, или записи текущей модели могут быть устранены.
from harvesttext import loadHT , saveHT
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
saveHT ( ht , "ht_model1" )
ht2 = loadHT ( "ht_model1" )
# 消除记录
ht2 . clear ()
print ( "cut with cleared model" )
print ( ht2 . seg ( para ))Конкретные реализации и примеры находятся в NAIVEKGQA.PY, и некоторые схемы приведены ниже:
QA = NaiveKGQA ( SVOs , entity_type_dict = entity_type_dict )
questions = [ "你好" , "孙中山干了什么事?" , "谁发动了什么?" , "清政府签订了哪些条约?" ,
"英国与鸦片战争的关系是什么?" , "谁复辟了帝制?" ]
for question0 in questions :
print ( "问:" + question0 )
print ( "答:" + QA . answer ( question0 ))问:孙中山干了什么事?
答:就任临时大总统、发动护法运动、让位于袁世凯
问:谁发动了什么?
答:英法联军侵略中国、国民党人二次革命、英国鸦片战争、日本侵略朝鲜、孙中山护法运动、法国侵略越南、英国侵略中国西藏战争、慈禧太后戊戌政变
问:清政府签订了哪些条约?
答:北京条约、天津条约
问:英国与鸦片战争的关系是什么?
答:发动
问:谁复辟了帝制?
答:袁世凯
Эта библиотека в основном предназначена для поддержки интеллектуального анализа данных на китайском языке, но добавила небольшое количество поддержки английского языка, включая анализ настроений.
Чтобы использовать эти функции, вам необходимо создать объект HarvestText с помощью специального английского шаблона.
# ♪ "Until the Day" by JJ Lin
test_text = """
In the middle of the night.
Lonely souls travel in time.
Familiar hearts start to entwine.
We imagine what we'll find, in another life.
""" . lower ()
ht_eng = HarvestText ( language = "en" )
sentences = ht_eng . cut_sentences ( test_text ) # 分句
print ( " n " . join ( sentences ))
print ( ht_eng . seg ( sentences [ - 1 ])) # 分词[及词性标注]
print ( ht_eng . posseg ( sentences [ 0 ], stopwords = { "in" }))
# 情感分析
sent_dict = ht_eng . build_sent_dict ( sentences , pos_seeds = [ "familiar" ], neg_seeds = [ "lonely" ],
min_times = 1 , stopwords = { 'in' , 'to' })
print ( "sentiment analysis" )
for sent0 in sentences :
print ( sent0 , "%.3f" % ht_eng . analyse_sent ( sent0 ))
# 自动分段
print ( "Segmentation" )
print ( " n " . join ( ht_eng . cut_paragraphs ( test_text , num_paras = 2 )))
# 情感分析也提供了一个内置英文词典资源
# from harvesttext.resources import get_english_senti_lexicon
# sent_lexicon = get_english_senti_lexicon()
# sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=sent_lexicon["pos"], neg_seeds=sent_lexicon["neg"], min_times=1) in the middle of the night.
lonely souls travel in time.
familiar hearts start to entwine.
we imagine what we'll find, in another life.
['we', 'imagine', 'what', 'we', "'ll", 'find', ',', 'in', 'another', 'life', '.']
[('the', 'DET'), ('middle', 'NOUN'), ('of', 'ADP'), ('the', 'DET'), ('night', 'NOUN'), ('.', '.')]
sentiment analysis
in the middle of the night. 0.000
lonely souls travel in time. -1.600
familiar hearts start to entwine. 1.600
we imagine what we'll find, in another life. 0.000
Segmentation
in the middle of the night. lonely souls travel in time. familiar hearts start to entwine.
we imagine what we'll find, in another life.
В настоящее время поддержка английского языка не идеальна. За исключением функций в приведенных выше примерах, другие функции не гарантируются.
Если вы обнаружите эту библиотеку полезной для вашей академической работы, пожалуйста, обратитесь к следующему формату
@misc{zhangHarvestText,
author = {Zhiling Zhang},
title = {HarvestText: A Toolkit for Text Mining and Preprocessing},
journal = {GitHub repository},
howpublished = {url{https://github.com/blmoistawinde/HarvestText}},
year = {2023}
}
Эта библиотека находится в стадии разработки, и улучшения существующих функций и дополнений к большему количеству функций могут прийти один за другим. Добро пожаловать, чтобы предоставить предложения по вопросам. Если вы думаете, что это легко использовать, у вас может быть звезда ~
Спасибо следующему репо для вдохновения:
злой
pyhanlp
Funnlp
Китайский словесний
EventTriplesextraction
Textrank4ZH


