HarvestText
V0.8
HarvestText:テキストマイニングと前処理用のツールキット
書類
GithubとCode Cloud Giteeで同期します。 githubで閲覧/ダウンロードすると、コードクラウドに移動して動作できます。
HarvestTextは、特定のドメインテキストを簡単かつ効率的に処理および分析するためにドメインの知識(タイプ、エイリアスなど)を統合する(弱い)監視方法に焦点を当てたライブラリです。これは、多くのテキストの前処理および予備的な探索的分析タスクに適しており、新しい分析、オンラインテキスト、専門文献、その他の分野で潜在的なアプリケーション値を持っています。
ユースケース:
[注:このライブラリは、エンティティワードセグメンテーションとセンチメント分析のみを完了し、視覚化にmatplotlibを使用します]
このREADMEには、さまざまな機能の典型的な例が含まれています。一部の関数の詳細な使用法は、ドキュメントにあります。
書類
特定の関数は次のとおりです。
目次:
最初にインストールして、PIPを使用します
pip install --upgrade harvesttextまたは、setup.pyが配置されているディレクトリを入力し、次にコマンドラインを入力します。
python setup.py install次に、コードで:
from harvesttext import HarvestText
ht = HarvestText ()このライブラリの機能インターフェイスを呼び出すことができます。
注:一部の機能では、追加のライブラリをインストールする必要がありますが、インストールが失敗する可能性があるため、必要に応じて手動でインストールしてください。
# 部分英语功能
pip install pattern
# 命名实体识别、句法分析等功能,需要python <= 3.8
pip install pyhanlp特定のエンティティとその可能性のある同義語、および対応するエンティティが与えられます。辞書にログに記録し、最初に単語を分割するときにそれを分割し、音声の一部として対応するタイプを使用します。コーパス内のすべてのエンティティとその場所は、個別に取得することもできます。
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
entity_mention_dict = { '武磊' :[ '武磊' , '武球王' ], '郜林' :[ '郜林' , '郜飞机' ], '前锋' :[ '前锋' ], '上海上港' :[ '上港' ], '广州恒大' :[ '恒大' ], '单刀球' :[ '单刀' ]}
entity_type_dict = { '武磊' : '球员' , '郜林' : '球员' , '前锋' : '位置' , '上海上港' : '球队' , '广州恒大' : '球队' , '单刀球' : '术语' }
ht . add_entities ( entity_mention_dict , entity_type_dict )
print ( " n Sentence segmentation" )
print ( ht . seg ( para , return_sent = True )) # return_sent=False时,则返回词语列表上海SIPGのウーレイやエバーグランデのガオリンなど、中国で最高のフォワードは誰ですか?もちろん、それはウー・ボールの王であるウー・レイです。彼はシューターリストの最初の人です。弱い単一の剣も進歩していることがわかります。
従来の単語セグメンテーションツールを使用すると、「Wuqiong King」を「Wuqiong King」に簡単に分割できます
指定された特別なタイプを含む音声注釈の一部。
print ( " n POS tagging with entity types" )
for word , flag in ht . posseg ( para ):
print ( "%s:%s" % ( word , flag ), end = " " )SIPG:チーム:UJ WU LEI:プレーヤーと:C Evergrande:Team:UJ Gao Lin:x x who:r is:v china:ns best:a:uj forward:position? :xそれ:rもちろん:d is:v wu lei:player wu qiu king:player:ul、:x he:r is:v scorer list:n first:m、:x x is:v deakping:n:uj single sword:d has:v resodage:d d d d d
for span , entity in ht . entity_linking ( para ):
print ( span , entity )[0、2]( 'Shanghai Sipg'、 '#Team#')[3、5]( 'wu lei'、 '#player#')[6、8]( 'guangzhou evergrande'、 '#team#')[9、11]( 'gao lin'、 '#player#')[19、21]プレーヤー# ')[28、31](' wu lei '、'#player# ')[47、49](「シングルオンボール」、'#用語# ')
ここで、「ウキウ王」の標準用語「ウーレイ」への変換は、統合された統計作業を促進することができます。
文:
print ( ht . cut_sentences ( para ))['上海SIPGから中国で最高のフォワードとEvergrandeのGao Linは誰ですか? '、'もちろん、それはウーレイのウーフットボールキングです。彼はシューターリストの最初の人です。弱い単一の剣も進歩したことがわかります ']
当面の辞書が手元にない場合は、このライブラリの組み込みリソースにあるドメイン辞書がお客様のニーズに適しているかどうかを確認することもできます。
同じ名前の複数の可能なエンティティがある場合(「li na playing ball and li na singingは同じ人ではありません」)、 keep_all=Trueを設定して複数の候補者を保持できます。他の戦略を使用して後で明確にすることができます。EL_KEEP_ALL()を参照してください
接続されているエンティティが多すぎる場合、その一部は明らかに不合理である場合、一部の戦略を使用してフィルタリングできます。これがfilter_el_with_ruleの例です。
このライブラリは、複雑なエンティティの曖昧性の除去タスク(単語の複数の意味[「教師」と「教師A」または「教師B」を指します]など、いくつかの基本的な戦略を使用することもできます。詳細については、linking_strategy()を見ることができます
テキストで特殊文字を処理したり、テキストに表示したくない特別な形式を削除したりできます。
含む: @、Weiboの絵文字; URL;メール; HTMLコードの特殊文字。 URLの%20の特殊文字。伝統的な中国人から簡素化された中国人
例は次のとおりです。
print ( "各种清洗文本" )
ht0 = HarvestText ()
# 默认的设置可用于清洗微博文本
text1 = "回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]"
print ( "清洗微博【@和表情符等】" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 ))各种清洗文本
清洗微博【@和表情符等】
原: 回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]
清洗后: 杨大哥
# URL的清理
text1 = "【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ"
print ( "清洗网址URL" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , remove_url = True ))清洗网址URL
原: 【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ
清洗后: 【#赵薇#:正筹备下一部电影 但不是青春片....
# 清洗邮箱
text1 = "我的邮箱是[email protected],欢迎联系"
print ( "清洗邮箱" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , email = True ))清洗邮箱
原: 我的邮箱是[email protected],欢迎联系
清洗后: 我的邮箱是,欢迎联系
# 处理URL转义字符
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print ( "URL转正常字符" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , norm_url = True , remove_url = False )) URL转正常字符
原: www.%E4%B8%AD%E6%96%87%20and%20space.com
清洗后: www.中文 and space.com
text1 = "www.中文 and space.com"
print ( "正常字符转URL[含有中文和空格的request需要注意]" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , to_url = True , remove_url = False ))正常字符转URL[含有中文和空格的request需要注意]
原: www.中文 and space.com
清洗后: www.%E4%B8%AD%E6%96%87%20and%20space.com
# 处理HTML转义字符
text1 = "<a c> ''"
print ( "HTML转正常字符" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , norm_html = True )) HTML转正常字符
原: <a c> ''
清洗后: <a c> ''
# 繁体字转简体
text1 = "心碎誰買單"
print ( "繁体字转简体" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , t2s = True ))繁体字转简体
原: 心碎誰買單
清洗后: 心碎谁买单
# markdown超链接提取文本
text1 = "欢迎使用[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)这个库"
print ( "markdown超链接提取文本" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , t2s = True )) markdown超链接提取文本
原: 欢迎使用[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)这个库
清洗后: 欢迎使用HarvestText : A Toolkit for Text Mining and Preprocessing这个库
文でその人、場所、組織などの名前を見つけます。 Pyhanlpインターフェイスの実装が使用されます。
ht0 = HarvestText ()
sent = "上海上港足球队的武磊是中国最好的前锋。"
print ( ht0 . named_entity_recognition ( sent )) {'上海上港足球队': '机构名', '武磊': '人名', '中国': '地名'}
主題対象のオブジェクトの変更と各単語のその他の文法的関係を分析し、ステートメント(リンクされたエンティティを含む)で、可能なイベントトリプルを抽出します。 Pyhanlpインターフェイスの実装が使用されます。
ht0 = HarvestText ()
para = "上港的武磊武球王是中国最好的前锋。"
entity_mention_dict = { '武磊' : [ '武磊' , '武球王' ], "上海上港" :[ "上港" ]}
entity_type_dict = { '武磊' : '球员' , "上海上港" : "球队" }
ht0 . add_entities ( entity_mention_dict , entity_type_dict )
for arc in ht0 . dependency_parse ( para ):
print ( arc )
print ( ht0 . triple_extraction ( para )) [0, '上港', '球队', '定中关系', 3]
[1, '的', 'u', '右附加关系', 0]
[2, '武磊', '球员', '定中关系', 3]
[3, '武球王', '球员', '主谓关系', 4]
[4, '是', 'v', '核心关系', -1]
[5, '中国', 'ns', '定中关系', 8]
[6, '最好', 'd', '定中关系', 8]
[7, '的', 'u', '右附加关系', 6]
[8, '前锋', 'n', '动宾关系', 4]
[9, '。', 'w', '标点符号', 4]
print ( ht0 . triple_extraction ( para )) [['上港武磊武球王', '是', '中国最好前锋']]
バージョンv0.7で変更された、許容範囲を使用して同じPinyinチェックをサポートする
既知のエンティティ(1つの文字またはピニインエラーを使用)である可能性のあるステートメントの単語を対応するエンティティにリンクします。
def entity_error_check ():
ht0 = HarvestText ()
typed_words = { "人名" :[ "武磊" ]}
ht0 . add_typed_words ( typed_words )
sent0 = "武磊和吴磊拼音相同"
print ( sent0 )
print ( ht0 . entity_linking ( sent0 , pinyin_tolerance = 0 ))
"""
武磊和吴磊拼音相同
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent1 = "武磊和吴力只差一个拼音"
print ( sent1 )
print ( ht0 . entity_linking ( sent1 , pinyin_tolerance = 1 ))
"""
武磊和吴力只差一个拼音
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent2 = "武磊和吴磊只差一个字"
print ( sent2 )
print ( ht0 . entity_linking ( sent2 , char_tolerance = 1 ))
"""
武磊和吴磊只差一个字
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent3 = "吴磊和吴力都可能是武磊的代称"
print ( sent3 )
print ( ht0 . get_linking_mention_candidates ( sent3 , pinyin_tolerance = 1 , char_tolerance = 1 ))
"""
吴磊和吴力都可能是武磊的代称
('吴磊和吴力都可能是武磊的代称', defaultdict(<class 'list'>, {(0, 2): {'武磊'}, (3, 5): {'武磊'}}))
"""このライブラリは、感情辞書の方法を使用して感情分析を実行し、少数の標準的な肯定的および否定的な単語(「シードワード」)を提供して感情的な辞書を形成することにより、コーパスからの他の単語の感情的傾向を自動的に学習します。カプレットの感情的な言葉の合計と平均は、文の感情的な傾向を判断するために使用されます。
print ( " n sentiment dictionary" )
sents = [ "武磊威武,中超第一射手!" ,
"武磊强,中超最第一本土球员!" ,
"郜林不行,只会抱怨的球员注定上限了" ,
"郜林看来不行,已经到上限了" ]
sent_dict = ht . build_sent_dict ( sents , min_times = 1 , pos_seeds = [ "第一" ], neg_seeds = [ "不行" ])
print ( "%s:%f" % ( "威武" , sent_dict [ "威武" ]))
print ( "%s:%f" % ( "球员" , sent_dict [ "球员" ]))
print ( "%s:%f" % ( "上限" , sent_dict [ "上限" ]))センチメント辞書:1.000000プレーヤー:0.000000キャップ:-1.0000000
print ( " n sentence sentiment" )
sent = "武球王威武,中超最强球员!"
print ( "%f:%s" % ( ht . analyse_sent ( sent ), sent ))0.600000:武道の王は強大で、中国のスーパーリーグで最も強い選手です!
どの単語を「シードワード」として選択するかを理解していない場合、このライブラリには一般的な感情辞書の組み込みリソースもあります。これは、感情的な単語を指定していないときにデフォルトの選択肢であり、必要に応じて選択することもできます。
デフォルトで使用されるSO-PMIアルゴリズムには、感情的価値に上限と下限の制約がありません。 [0,1]や[-1,1]などの間隔に制限する必要がある場合は、スケールパラメーターを調整できます。例は次のとおりです。
print ( " n sentiment dictionary using default seed words" )
docs = [ "张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资" ,
"打倒万恶的资本家" ,
"该公司原定资本总额为二十五万万元,现已由各界分认达二十万万元,所属各厂、各公司亦募得股金一万万余元" ,
"连日来解放区以外各工商人士,投函向该公司询问经营性质与范围以及股东权限等问题者甚多,络绎抵此的许多资本家,于参观该公司所属各厂经营状况后,对民主政府扶助与奖励私营企业发展的政策,均极表赞同,有些资本家因款项未能即刻汇来,多向筹备处预认投资的额数。由平津来张的林明棋先生,一次即以现款入股六十余万元"
]
# scale: 将所有词语的情感值范围调整到[-1,1]
# 省略pos_seeds, neg_seeds,将采用默认的情感词典 get_qh_sent_dict()
print ( "scale= " 0-1 " , 按照最大为1,最小为0进行线性伸缩,0.5未必是中性" )
sent_dict = ht . build_sent_dict ( docs , min_times = 1 , scale = "0-1" )
print ( "%s:%f" % ( "赞同" , sent_dict [ "赞同" ]))
print ( "%s:%f" % ( "二十万" , sent_dict [ "二十万" ]))
print ( "%s:%f" % ( "万恶" , sent_dict [ "万恶" ]))
print ( "%f:%s" % ( ht . analyse_sent ( docs [ 0 ]), docs [ 0 ]))
print ( "%f:%s" % ( ht . analyse_sent ( docs [ 1 ]), docs [ 1 ])) sentiment dictionary using default seed words
scale="0-1", 按照最大为1,最小为0进行线性伸缩,0.5未必是中性
赞同:1.000000
二十万:0.153846
万恶:0.000000
0.449412:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
0.364910:打倒万恶的资本家
print("scale="+-1", 在正负区间内分别伸缩,保留0作为中性的语义")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="+-1")
print("%s:%f" % ("赞同",sent_dict["赞同"]))
print("%s:%f" % ("二十万",sent_dict["二十万"]))
print("%s:%f" % ("万恶",sent_dict["万恶"]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))
scale="+-1", 在正负区间内分别伸缩,保留0作为中性的语义
赞同:1.000000
二十万:0.000000
万恶:-1.000000
0.349305:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
-0.159652:打倒万恶的资本家
ドキュメントリストから対応するエンティティ(およびそのエイリアス)を含むドキュメントを見つけることができ、エンティティを含むドキュメントの数をカウントできます。反転インデックスを使用してデータ構造を使用して、迅速な取得を完了します。
次のコードは、エンティティを追加するプロセスからの抜粋です。 ADD_ENTITIESなどの関数を使用して、注意を払うエンティティを追加し、インデックスと検索を行います。
docs = [ "武磊威武,中超第一射手!" ,
"郜林看来不行,已经到上限了。" ,
"武球王威武,中超最强前锋!" ,
"武磊和郜林,谁是中国最好的前锋?" ]
inv_index = ht . build_index ( docs )
print ( ht . get_entity_counts ( docs , inv_index )) # 获得文档中所有实体的出现次数
# {'武磊': 3, '郜林': 2, '前锋': 2}
print ( ht . search_entity ( "武磊" , docs , inv_index )) # 单实体查找
# ['武磊威武,中超第一射手!', '武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
print ( ht . search_entity ( "武磊 郜林" , docs , inv_index )) # 多实体共现
# ['武磊和郜林,谁是中国最好的前锋?']
# 谁是最被人们热议的前锋?用这里的接口可以很简便地回答这个问题
subdocs = ht . search_entity ( "#球员# 前锋" , docs , inv_index )
print ( subdocs ) # 实体、实体类型混合查找
# ['武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
inv_index2 = ht . build_index ( subdocs )
print ( ht . get_entity_counts ( subdocs , inv_index2 , used_type = [ "球员" ])) # 可以限定类型
# {'武磊': 2, '郜林': 1}(NetworkXを使用して実装)Word共起関係を使用して、ボディ間のグラフ構造間のネットワーク関係を確立します(NetworkX.Graphタイプに戻ります)。キャラクターなどの間のソーシャルネットワークを構築するために使用できます。
# 在现有实体库的基础上随时新增,比如从新词发现中得到的漏网之鱼
ht . add_new_entity ( "颜骏凌" , "颜骏凌" , "球员" )
docs = [ "武磊和颜骏凌是队友" ,
"武磊和郜林都是国内顶尖前锋" ]
G = ht . build_entity_graph ( docs )
print ( dict ( G . edges . items ()))
G = ht . build_entity_graph ( docs , used_types = [ "球员" ])
print ( dict ( G . edges . items ()))単語を中心とした単語ネットワークを取得します。 3つの王国の最初の章を取り上げて、主人公のLiu Beiの出会いを探る例として考えてみましょう(以下はメインコードです。たとえば、build_word_ego_graph()を参照してください)。
entity_mention_dict , entity_type_dict = get_sanguo_entity_dict ()
ht0 . add_entities ( entity_mention_dict , entity_type_dict )
sanguo1 = get_sanguo ()[ 0 ]
stopwords = get_baidu_stopwords ()
docs = ht0 . cut_sentences ( sanguo1 )
G = ht0 . build_word_ego_graph ( docs , "刘备" , min_freq = 3 , other_min_freq = 2 , stopwords = stopwords )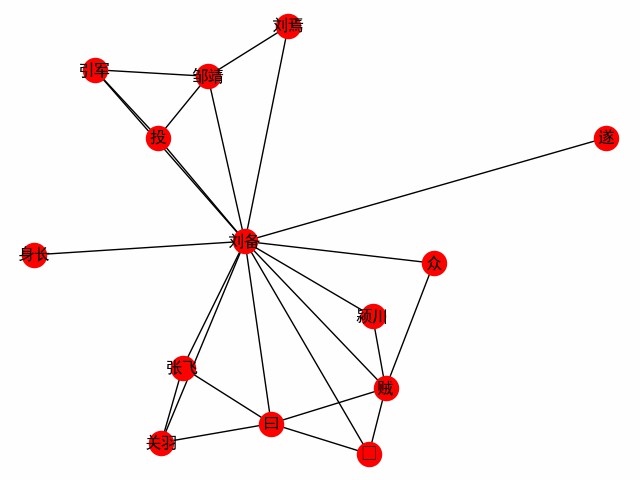
これは、Liu、Guan、Zhangの友情であり、Li Beiが亡命した支援者であり、Li Beiが泥棒と戦う経験です。
(NetworkXを使用して実装)TextTrankアルゴリズムを使用して、概要情報としてドキュメントコレクションから抽出された代表文を取得します。重複を罰する文を設定することも、単語制限を設定することもできます(Maxlenパラメーター):
print ( " n Text summarization" )
docs = [ "武磊威武,中超第一射手!" ,
"郜林看来不行,已经到上限了。" ,
"武球王威武,中超最强前锋!" ,
"武磊和郜林,谁是中国最好的前锋?" ]
for doc in ht . get_summary ( docs , topK = 2 ):
print ( doc )
print ( " n Text summarization(避免重复)" )
for doc in ht . get_summary ( docs , topK = 3 , avoid_repeat = True ):
print ( doc ) Text summarization
武球王威武,中超最强前锋!
武磊威武,中超第一射手!
Text summarization(避免重复)
武球王威武,中超最强前锋!
郜林看来不行,已经到上限了。
武磊和郜林,谁是中国最好的前锋?
現在、Jiebaをカプセル化してパラメーターを構成してjieba_tfidfを停止するために、 textrankとHarvestTextを含む2つのアルゴリズムがあります。
例(完全な例を参照):
# text为林俊杰《关键词》歌词
print ( "《关键词》里的关键词" )
kwds = ht . extract_keywords ( text , 5 , method = "jieba_tfidf" )
print ( "jieba_tfidf" , kwds )
kwds = ht . extract_keywords ( text , 5 , method = "textrank" )
print ( "textrank" , kwds ) 《关键词》里的关键词
jieba_tfidf ['自私', '慷慨', '落叶', '消逝', '故事']
textrank ['自私', '落叶', '慷慨', '故事', '位置']
CSL.IPYNBは、さまざまなアルゴリズムと、CSLデータセット上のこのライブラリとTexTrank4ZHの実装の比較を提供します。データセットは1つしかなく、データセットは上記のアルゴリズムに友好的ではないため、パフォーマンスは参照のみです。
| アルゴリズム | P@5 | R@5 | F@5 |
|---|---|---|---|
| textrank4zh | 0.0836 | 0.1174 | 0.0977 |
| ht_texttransk | 0.0955 | 0.1342 | 0.1116 |
| ht_jieba_tfidf | 0.1035 | 0.1453 | 0.1209 |
現在、いくつかのリソースがこのライブラリに統合されており、使用を促進し、デモを確立しています。
リソースは次のとおりです。
get_qh_sent_dict :tsinghua大学の無料およびネガティブ辞書li junはhttp://nlp.csai.tsinghua.edu.cn/site2/index.php/13-smsからそれをまとめましたget_baidu_stopwords :baiduストップワードディクショナリはインターネットから来ています:https://wenku.baidu.com/view/98c46383e53a580216fcfed9.htmlget_qh_typed_words :tsinghua thunlpのドメイン辞書:http://thuocl.thunlp.org/すべてのタイプ['IT', '动物', '医药', '历史人名', '地名', '成语', '法律', '财经', '食物']get_english_senti_lexicon :英語の感情辞書get_jieba_dict :(ダウンロードする必要があります)Jieba Word Frequency Dictionaryさらに、特別なリソースが提供されます - 「3つの王国のロマンス」を含む:
あなたはそれからどのような興味深い発見を得ることができるかを探ることができますか?
def load_resources ():
from harvesttext . resources import get_qh_sent_dict , get_baidu_stopwords , get_sanguo , get_sanguo_entity_dict
sdict = get_qh_sent_dict () # {"pos":[积极词...],"neg":[消极词...]}
print ( "pos_words:" , list ( sdict [ "pos" ])[ 10 : 15 ])
print ( "neg_words:" , list ( sdict [ "neg" ])[ 5 : 10 ])
stopwords = get_baidu_stopwords ()
print ( "stopwords:" , list ( stopwords )[ 5 : 10 ])
docs = get_sanguo () # 文本列表,每个元素为一章的文本
print ( "三国演义最后一章末16字: n " , docs [ - 1 ][ - 16 :])
entity_mention_dict , entity_type_dict = get_sanguo_entity_dict ()
print ( "刘备 指称:" , entity_mention_dict [ "刘备" ])
print ( "刘备 类别:" , entity_type_dict [ "刘备" ])
print ( "蜀 类别:" , entity_type_dict [ "蜀" ])
print ( "益州 类别:" , entity_type_dict [ "益州" ])
load_resources () pos_words: ['宰相肚里好撑船', '查实', '忠实', '名手', '聪明']
neg_words: ['散漫', '谗言', '迂执', '肠肥脑满', '出卖']
stopwords: ['apart', '左右', '结果', 'probably', 'think']
三国演义最后一章末16字:
鼎足三分已成梦,后人凭吊空牢骚。
刘备 指称: ['刘备', '刘玄德', '玄德']
刘备 类别: 人名
蜀 类别: 势力
益州 类别: 州名
Tsinghuaフィールド辞書をロードし、停止ワードを使用します。
def using_typed_words ():
from harvesttext . resources import get_qh_typed_words , get_baidu_stopwords
ht0 = HarvestText ()
typed_words , stopwords = get_qh_typed_words (), get_baidu_stopwords ()
ht0 . add_typed_words ( typed_words )
sentence = "THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。"
print ( sentence )
print ( ht0 . posseg ( sentence , stopwords = stopwords ))
using_typed_words () THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。
[('THUOCL', 'eng'), ('自然语言处理', 'IT'), ('一套', 'm'), ('中文', 'nz'), ('词库', 'n'), ('词表', 'n'), ('来自', 'v'), ('主流', 'b'), ('网站', 'n'), ('社会', 'n'), ('标签', '财经'), ('搜索', 'v'), ('热词', 'n'), ('输入法', 'IT'), ('词库', 'n')]
いくつかの単語には特別なタイプが与えられますが、「はい」などの単語は上映されます。
いくつかの統計的指標を使用して、比較的多数のテキストから新しい単語を発見します。 (オプション)品質の程度を決定する単語は、いくつかの種子の単語を提供することで見つけることができます。 (つまり、特定の基本要件が満たされているという前提で、少なくともすべての種子の単語が見つかります。)
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
#返回关于新词质量的一系列信息,允许手工改进筛选(pd.DataFrame型)
new_words_info = ht . word_discover ( para )
#new_words_info = ht.word_discover(para, threshold_seeds=["武磊"])
new_words = new_words_info . index . tolist ()
print ( new_words )["wu lei"]
アルゴリズムは、デフォルトの経験的パラメーターを使用します。結果の数に満足していない場合は、 auto_param=Falseを設定してパラメーターを自分で調整し、最終結果の数を調整できます。関連するパラメーターは次のとおりです。
:param max_word_len: 允许被发现的最长的新词长度
:param min_freq: 被发现的新词,在给定文本中需要达到的最低频率
:param min_entropy: 被发现的新词,在给定文本中需要达到的最低左右交叉熵
:param min_aggregation: 被发现的新词,在给定文本中需要达到的最低凝聚度
たとえば、デフォルトよりも多くの結果を取得する場合(たとえば、いくつかの新しい単語は発見されていません)、デフォルトのパラメーターと次のデフォルトパラメーターに基づいてそれらをダウンレギュレートできます。
min_entropy = np.log(length) / 10
min_freq = min(0.00005, 20.0 / length)
min_aggregation = np.sqrt(length) / 15
特定のアルゴリズムの詳細とパラメーターの意味、http://www.matrix67.com/blog/archives/5044を参照してください
フィードバックの更新によると、元々はデフォルトで個別の文字列を受け入れました。また、文字列リスト入力を受け入れることができ、自動的にスプライスされます
フィードバックの更新によると、デフォルトでデフォルトでソートできるようになりました。 sort_by='score'パラメーターを渡して、包括的な品質スコアでソートすることもできます。
見つかった新しい単語の多くは、テキストの特別なキーワードである可能性があるため、見つかった新しい単語をログインすることができ、その後の分詞がこれらの単語を優先するようにします。
def new_word_register ():
new_words = [ "落叶球" , "666" ]
ht . add_new_words ( new_words ) # 作为广义上的"新词"登录
ht . add_new_entity ( "落叶球" , mention0 = "落叶球" , type0 = "术语" ) # 作为特定类型登录
print ( ht . seg ( "这个落叶球踢得真是666" , return_sent = True ))
for word , flag in ht . posseg ( "这个落叶球踢得真是666" ):
print ( "%s:%s" % ( word , flag ), end = " " )この落ちたリーフボールは本当に666です
これ:r leaf ball:term kick:v get:ud really:d 666:new word
また、いくつかの特別なルールを使用して、必要なキーワードを見つけて、すべて英語のようなタイプに直接割り当てたり、特定のPresとサフィックスなどを持っています。
# find_with_rules()
from harvesttext . match_patterns import UpperFirst , AllEnglish , Contains , StartsWith , EndsWith
text0 = "我喜欢Python,因为requests库很适合爬虫"
ht0 = HarvestText ()
found_entities = ht0 . find_entity_with_rule ( text0 , rulesets = [ AllEnglish ()], type0 = "英文名" )
print ( found_entities )
print ( ht0 . posseg ( text0 )) {'Python', 'requests'}
[('我', 'r'), ('喜欢', 'v'), ('Python', '英文名'), (',', 'x'), ('因为', 'c'), ('requests', '英文名'), ('库', 'n'), ('很', 'd'), ('适合', 'v'), ('爬虫', 'n')]
Textタイリングアルゴリズムを使用して、セグメントなしでテキストを自動的にセグメント化するか、既存の段落に基づいてさらに整理/回復を整理します。
ht0 = HarvestText ()
text = """备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”"""
print ( "原始文本[5段]" )
print ( text + " n " )
print ( "预测文本[手动设置分3段]" )
predicted_paras = ht0 . cut_paragraphs ( text , num_paras = 3 )
print ( " n " . join ( predicted_paras ) + " n " )原始文本[5段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
预测文本[手动设置分3段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
元の論文とは異なり、文の結果は基本単位として使用され、文字の使用は固定数ではなく、より明確になり、パラメーターを設定するトラブルを節約します。したがって、デフォルト設定の下のアルゴリズムは、句読点なしではテキストをサポートしません。ただし、 seq_chars正の整数に設定して、句読点なしでテキストをセグメント化することにより、元の論文の設定を使用できます。段落ラップがない場合は、 align_boundary=Falseを設定してください。たとえば、 examples/basic.pyのcut_paragraph()参照してください:
print ( "去除标点以后的分段" )
text2 = extract_only_chinese ( text )
predicted_paras2 = ht0 . cut_paragraphs ( text2 , num_paras = 5 , seq_chars = 10 , align_boundary = False )
print ( " n " . join ( predicted_paras2 ) + " n " )去除标点以后的分段
备受社会关注的湖南常德滴滴司机遇害案将于月日时许在汉寿县人民法院开庭审理此前犯罪嫌疑人岁大学生杨某淇被鉴定为作案时患有抑郁症为有
限定刑事责任能力新京报此前报道年
月日凌晨滴滴司机陈师
傅搭载岁大学生杨某淇到常南汽车总站附近坐在后排的杨某淇趁陈某不备朝陈某连捅数刀致其死亡事发监控显示杨某淇杀人后下车离开随后杨某淇
到公安机关自首并供述称因悲观厌世精神崩溃无故将司机杀害据杨某淇就读学校的工作人员称他家有四口人姐姐是聋哑人今日上午田女士告诉新京
报记者明日开庭时间不变此前已提出刑事附带民事赔偿但通过与法院的沟通后获知对方父母已经没有赔偿的意愿当时按照人身死亡赔偿金计算共计
多万元那时也想考虑对方家庭的经济状况田女士说她相信法律对最后的结果也做好心理准备对方一家从未道歉此前庭前会议中对方提
出了嫌疑人杨某淇作案时患有抑郁症的辩护意见另具警方出具的鉴定书显示嫌疑人作案时有限定刑事责任能力新京
报记者从陈师傅的家属处获知陈师傅有两个儿子大儿子今年岁小儿子还不到岁这对我来说是一起悲剧对我们生活的影响肯定是很大的田女士告诉新
京报记者丈夫遇害后他们一家的主劳动力没有了她自己带着两个孩子和两个老人一起过生活很艰辛她说还好有妹妹的陪伴现在已经好些了
モデルはローカルに保存して多重化を読み取ることができます。または、現在のモデルのレコードを排除できます。
from harvesttext import loadHT , saveHT
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
saveHT ( ht , "ht_model1" )
ht2 = loadHT ( "ht_model1" )
# 消除记录
ht2 . clear ()
print ( "cut with cleared model" )
print ( ht2 . seg ( para ))具体的な実装と例はnaivekgqa.pyにあり、いくつかの概略図を以下に示します。
QA = NaiveKGQA ( SVOs , entity_type_dict = entity_type_dict )
questions = [ "你好" , "孙中山干了什么事?" , "谁发动了什么?" , "清政府签订了哪些条约?" ,
"英国与鸦片战争的关系是什么?" , "谁复辟了帝制?" ]
for question0 in questions :
print ( "问:" + question0 )
print ( "答:" + QA . answer ( question0 ))问:孙中山干了什么事?
答:就任临时大总统、发动护法运动、让位于袁世凯
问:谁发动了什么?
答:英法联军侵略中国、国民党人二次革命、英国鸦片战争、日本侵略朝鲜、孙中山护法运动、法国侵略越南、英国侵略中国西藏战争、慈禧太后戊戌政变
问:清政府签订了哪些条约?
答:北京条约、天津条约
问:英国与鸦片战争的关系是什么?
答:发动
问:谁复辟了帝制?
答:袁世凯
このライブラリは、主に中国語のデータマイニングをサポートするように設計されていますが、センチメント分析を含む少量の英語サポートを追加しました。
これらの関数を使用するには、特別な英語のパターンを持つHarvestTextオブジェクトを作成する必要があります。
# ♪ "Until the Day" by JJ Lin
test_text = """
In the middle of the night.
Lonely souls travel in time.
Familiar hearts start to entwine.
We imagine what we'll find, in another life.
""" . lower ()
ht_eng = HarvestText ( language = "en" )
sentences = ht_eng . cut_sentences ( test_text ) # 分句
print ( " n " . join ( sentences ))
print ( ht_eng . seg ( sentences [ - 1 ])) # 分词[及词性标注]
print ( ht_eng . posseg ( sentences [ 0 ], stopwords = { "in" }))
# 情感分析
sent_dict = ht_eng . build_sent_dict ( sentences , pos_seeds = [ "familiar" ], neg_seeds = [ "lonely" ],
min_times = 1 , stopwords = { 'in' , 'to' })
print ( "sentiment analysis" )
for sent0 in sentences :
print ( sent0 , "%.3f" % ht_eng . analyse_sent ( sent0 ))
# 自动分段
print ( "Segmentation" )
print ( " n " . join ( ht_eng . cut_paragraphs ( test_text , num_paras = 2 )))
# 情感分析也提供了一个内置英文词典资源
# from harvesttext.resources import get_english_senti_lexicon
# sent_lexicon = get_english_senti_lexicon()
# sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=sent_lexicon["pos"], neg_seeds=sent_lexicon["neg"], min_times=1) in the middle of the night.
lonely souls travel in time.
familiar hearts start to entwine.
we imagine what we'll find, in another life.
['we', 'imagine', 'what', 'we', "'ll", 'find', ',', 'in', 'another', 'life', '.']
[('the', 'DET'), ('middle', 'NOUN'), ('of', 'ADP'), ('the', 'DET'), ('night', 'NOUN'), ('.', '.')]
sentiment analysis
in the middle of the night. 0.000
lonely souls travel in time. -1.600
familiar hearts start to entwine. 1.600
we imagine what we'll find, in another life. 0.000
Segmentation
in the middle of the night. lonely souls travel in time. familiar hearts start to entwine.
we imagine what we'll find, in another life.
現在、英語のサポートは完璧ではありません。上記の例の関数を除き、他の機能を使用することは保証されていません。
このライブラリがあなたの学術作業に役立つと思う場合は、次の形式を参照してください
@misc{zhangHarvestText,
author = {Zhiling Zhang},
title = {HarvestText: A Toolkit for Text Mining and Preprocessing},
journal = {GitHub repository},
howpublished = {url{https://github.com/blmoistawinde/HarvestText}},
year = {2023}
}
このライブラリは開発中であり、既存の機能の改善と、より多くの機能への追加が次々に来る場合があります。問題の提案を提供するためのようこそ。使いやすいと思うなら、星を持っているかもしれません〜
インスピレーションについては、次のリポジトリに感謝します。
snownlp
pyhanlp
funnlp
中国語のセグメンテーション
eventTriplesexTraction
textrank4zh


