HarvestText
V0.8
HarvestText : 텍스트 마이닝 및 전처리를위한 툴킷
문서
GitHub 및 Code Cloud Gitee에서 동기화하십시오. GitHub에서 탐색/다운로드하면 코드 클라우드로 이동하여 작동 할 수 있습니다.
HarvestText는 도메인 지식 (예 : 유형, 별칭)을 통합하여 특정 도메인 텍스트를 간단하고 효율적으로 처리하고 분석하는 (약한) 감독 방법에 중점을 둔 라이브러리입니다. 많은 텍스트 전처리 및 예비 탐색 적 분석 작업에 적합하며 새로운 분석, 온라인 텍스트, 전문 문학 및 기타 분야에서 잠재적 인 적용 가치가 있습니다.
사용 사례 :
[참고 :이 라이브러리는 엔터티 워드 세분화 및 감정 분석 만 완료하고 시각화를 위해 Matplotlib를 사용합니다.]
이 readme에는 다양한 기능의 전형적인 예가 포함되어 있습니다. 일부 기능의 자세한 사용은 설명서에서 찾을 수 있습니다.
문서
특정 기능은 다음과 같습니다.
목차 :
먼저 PIP를 사용하십시오
pip install --upgrade harvesttext또는 setup.py가있는 디렉토리를 입력 한 다음 명령 줄을 입력하십시오.
python setup.py install그런 다음 코드에서 :
from harvesttext import HarvestText
ht = HarvestText ()이 라이브러리의 기능 인터페이스를 호출 할 수 있습니다.
참고 : 일부 기능에는 추가 라이브러리를 설치해야하지만 설치가 실패 할 수 있으므로 필요한 경우 수동으로 설치하십시오.
# 部分英语功能
pip install pattern
# 命名实体识别、句法分析等功能,需要python <= 3.8
pip install pyhanlp특정 법인과 가능한 동의어뿐만 아니라 엔티티 해당 유형을 감안할 때. 사전에 로그인하고 단어를 이별 할 때 먼저 나누고 해당 유형을 음성의 일부로 사용하십시오. 코퍼스의 모든 실체와 해당 위치는 별도로 얻을 수 있습니다.
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
entity_mention_dict = { '武磊' :[ '武磊' , '武球王' ], '郜林' :[ '郜林' , '郜飞机' ], '前锋' :[ '前锋' ], '上海上港' :[ '上港' ], '广州恒大' :[ '恒大' ], '单刀球' :[ '单刀' ]}
entity_type_dict = { '武磊' : '球员' , '郜林' : '球员' , '前锋' : '位置' , '上海上港' : '球队' , '广州恒大' : '球队' , '单刀球' : '术语' }
ht . add_entities ( entity_mention_dict , entity_type_dict )
print ( " n Sentence segmentation" )
print ( ht . seg ( para , return_sent = True )) # return_sent=False时,则返回词语列表상하이 SIPG의 Wu Lei와 Evergrande의 Gao Lin을 포함하여 중국에서 가장 좋은 선수는 누구입니까? 물론 우의 왕 우 레이입니다. 그는 사수 목록에서 첫 번째입니다. 약한 단일 검도 진전을 이루었습니다.
전통적인 단어 세분화 도구를 사용하면 "Wuqiong King"을 쉽게 나눌 수 있습니다.
지정된 특수 유형을 포함한 음성 주석의 일부.
print ( " n POS tagging with entity types" )
for word , flag in ht . posseg ( para ):
print ( "%s:%s" % ( word , flag ), end = " " )SIPG : 팀 : UJ Wu Lei : Players and : C Evergrande : Team : UJ Gao Lin : Players ,: X WHO : v China : NS Best : A : UJ Forward : 위치? : x 물론 : D IS : D IS : V WU LEI : PLAYER WU QIU KIN : PLAYER : ul, : X HE : r : v 득점자 목록 : n 첫 번째 : x 원래 : v e : v 약점 : n : uj 단일 소드 : d has is : v progress : d
for span , entity in ht . entity_linking ( para ):
print ( span , entity )[0, 2] ( 'Shanghai Sipg', '# Team#') [3, 5] ( 'Wu Lei', '# Player#') [6, 8] ( 'Guangzhou Evergrande', '# Team#') [28, 31] ( 'Wu Lei', '# player#') [47, 49] ( '단일 온 공', '# 용어#')
여기서, "Wuqiu King"을 표준 용어 "Wu Lei"로 바꾸는 것은 통합 통계 작업을 용이하게 할 수 있습니다.
문장:
print ( ht . cut_sentences ( para ))[ '상하이 SIPG와 Evergrande의 Gao Lin에서 중국에서 가장 좋은 사람은 누구입니까? ','물론 Wu Lei의 Wu 축구 왕입니다. 그는 사수 목록에서 첫 번째입니다. 약한 단일 검도 진전을 이루었다는 것이 밝혀졌습니다. ']
당분간에 사용할 수있는 사전이없는 경우이 라이브러리의 내장 리소스의 도메인 사전이 귀하의 요구에 적합한 지 확인할 수도 있습니다.
같은 이름에 대한 여러 개체가있는 경우 ( "Li na Playing Ball과 Li na 노래는 같은 사람이 아니다"), 여러 후보자를 유지하도록 keep_all=True 설정할 수 있습니다. 다른 전략을 사용하여 나중에 명확하게 표시 할 수 있습니다. El_Keep_all ()을 참조하십시오.
너무 많은 엔티티가 연결되어 있고 그 중 일부는 분명히 불합리한 경우 일부 전략을 사용하여 필터링 할 수 있습니다. 다음은 필터 _el_with_rule () 예입니다.
이 라이브러리는 또한 복잡한 엔티티 명료 작업을 처리하기 위해 몇 가지 기본 전략을 사용할 수 있습니다 (예 : [ "교사"라는 단어의 여러 의미와 같은 "교사 A"또는 "교사 B"? 후보 단어는 XX/Jiang YY?, 시장 XX/Jiang YY?]). 자세한 내용은 linking_strategy ()를 참조하십시오.
텍스트에서 특수 문자를 처리하거나 텍스트로 표시하지 않으려는 특수 형식을 제거 할 수 있습니다.
포함 : @, Weibo의 이모티콘; URL; 이메일; HTML 코드의 특수 문자; URL의 %20의 특수 문자; 중국 전통 중국어에서 중국어를 단순화했습니다
예는 다음과 같습니다.
print ( "各种清洗文本" )
ht0 = HarvestText ()
# 默认的设置可用于清洗微博文本
text1 = "回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]"
print ( "清洗微博【@和表情符等】" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 ))各种清洗文本
清洗微博【@和表情符等】
原: 回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]
清洗后: 杨大哥
# URL的清理
text1 = "【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ"
print ( "清洗网址URL" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , remove_url = True ))清洗网址URL
原: 【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ
清洗后: 【#赵薇#:正筹备下一部电影 但不是青春片....
# 清洗邮箱
text1 = "我的邮箱是[email protected],欢迎联系"
print ( "清洗邮箱" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , email = True ))清洗邮箱
原: 我的邮箱是[email protected],欢迎联系
清洗后: 我的邮箱是,欢迎联系
# 处理URL转义字符
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print ( "URL转正常字符" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , norm_url = True , remove_url = False )) URL转正常字符
原: www.%E4%B8%AD%E6%96%87%20and%20space.com
清洗后: www.中文 and space.com
text1 = "www.中文 and space.com"
print ( "正常字符转URL[含有中文和空格的request需要注意]" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , to_url = True , remove_url = False ))正常字符转URL[含有中文和空格的request需要注意]
原: www.中文 and space.com
清洗后: www.%E4%B8%AD%E6%96%87%20and%20space.com
# 处理HTML转义字符
text1 = "<a c> ''"
print ( "HTML转正常字符" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , norm_html = True )) HTML转正常字符
原: <a c> ''
清洗后: <a c> ''
# 繁体字转简体
text1 = "心碎誰買單"
print ( "繁体字转简体" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , t2s = True ))繁体字转简体
原: 心碎誰買單
清洗后: 心碎谁买单
# markdown超链接提取文本
text1 = "欢迎使用[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)这个库"
print ( "markdown超链接提取文本" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , t2s = True )) markdown超链接提取文本
原: 欢迎使用[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)这个库
清洗后: 欢迎使用HarvestText : A Toolkit for Text Mining and Preprocessing这个库
문장에서 사람, 장소, 조직 등의 이름을 찾으십시오. pyhanlp 인터페이스 구현이 사용됩니다.
ht0 = HarvestText ()
sent = "上海上港足球队的武磊是中国最好的前锋。"
print ( ht0 . named_entity_recognition ( sent )) {'上海上港足球队': '机构名', '武磊': '人名', '中国': '地名'}
진술 (링크 된 개체 포함)에서 각 단어의 주제 예측 물체 수정 및 기타 문법 관계를 분석하고 가능한 이벤트 트리플을 추출하십시오. pyhanlp 인터페이스 구현이 사용됩니다.
ht0 = HarvestText ()
para = "上港的武磊武球王是中国最好的前锋。"
entity_mention_dict = { '武磊' : [ '武磊' , '武球王' ], "上海上港" :[ "上港" ]}
entity_type_dict = { '武磊' : '球员' , "上海上港" : "球队" }
ht0 . add_entities ( entity_mention_dict , entity_type_dict )
for arc in ht0 . dependency_parse ( para ):
print ( arc )
print ( ht0 . triple_extraction ( para )) [0, '上港', '球队', '定中关系', 3]
[1, '的', 'u', '右附加关系', 0]
[2, '武磊', '球员', '定中关系', 3]
[3, '武球王', '球员', '主谓关系', 4]
[4, '是', 'v', '核心关系', -1]
[5, '中国', 'ns', '定中关系', 8]
[6, '最好', 'd', '定中关系', 8]
[7, '的', 'u', '右附加关系', 6]
[8, '前锋', 'n', '动宾关系', 4]
[9, '。', 'w', '标点符号', 4]
print ( ht0 . triple_extraction ( para )) [['上港武磊武球王', '是', '中国最好前锋']]
버전 v0.7에서 수정 된 내성을 사용하여 동일한 Pinyin 검사를 지원합니다.
문자가 해당 엔티티에 알려진 엔티티 (하나의 문자 또는 Pinyin 오류 포함) 일 수있는 문자를 링크하십시오.
def entity_error_check ():
ht0 = HarvestText ()
typed_words = { "人名" :[ "武磊" ]}
ht0 . add_typed_words ( typed_words )
sent0 = "武磊和吴磊拼音相同"
print ( sent0 )
print ( ht0 . entity_linking ( sent0 , pinyin_tolerance = 0 ))
"""
武磊和吴磊拼音相同
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent1 = "武磊和吴力只差一个拼音"
print ( sent1 )
print ( ht0 . entity_linking ( sent1 , pinyin_tolerance = 1 ))
"""
武磊和吴力只差一个拼音
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent2 = "武磊和吴磊只差一个字"
print ( sent2 )
print ( ht0 . entity_linking ( sent2 , char_tolerance = 1 ))
"""
武磊和吴磊只差一个字
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent3 = "吴磊和吴力都可能是武磊的代称"
print ( sent3 )
print ( ht0 . get_linking_mention_candidates ( sent3 , pinyin_tolerance = 1 , char_tolerance = 1 ))
"""
吴磊和吴力都可能是武磊的代称
('吴磊和吴力都可能是武磊的代称', defaultdict(<class 'list'>, {(0, 2): {'武磊'}, (3, 5): {'武磊'}}))
"""이 라이브러리는 감정 사전 방법을 사용하여 감정 분석을 수행하고 감정 사전을 형성하기 위해 소수의 표준 긍정적 및 부정적인 단어 ( "종자 단어")를 제공하여 코퍼스의 다른 단어의 감정적 경향을 자동으로 배웁니다. 커플 렛의 감정적 단어의 요약과 평균은 문장의 감정적 경향을 판단하는 데 사용됩니다.
print ( " n sentiment dictionary" )
sents = [ "武磊威武,中超第一射手!" ,
"武磊强,中超最第一本土球员!" ,
"郜林不行,只会抱怨的球员注定上限了" ,
"郜林看来不行,已经到上限了" ]
sent_dict = ht . build_sent_dict ( sents , min_times = 1 , pos_seeds = [ "第一" ], neg_seeds = [ "不行" ])
print ( "%s:%f" % ( "威武" , sent_dict [ "威武" ]))
print ( "%s:%f" % ( "球员" , sent_dict [ "球员" ]))
print ( "%s:%f" % ( "上限" , sent_dict [ "上限" ]))감정 사전 : 1.000000 플레이어 : 0.000000 캡 : -1.0000000
print ( " n sentence sentiment" )
sent = "武球王威武,中超最强球员!"
print ( "%f:%s" % ( ht . analyse_sent ( sent ), sent ))0.600000 : 무술의 왕은 중국 슈퍼 리그에서 강력하고 가장 강력한 선수입니다!
"종자 단어"로 선택할 단어를 알지 못했다면이 라이브러리에는 일반적인 감정 사전을위한 내장 리소스가 있습니다. 이는 감정적 인 단어를 지정하지 않을 때 기본 선택이며 필요에 따라 선택할 수도 있습니다.
기본적으로 사용되는 SO-PMI 알고리즘은 감정적 가치에 대한 상한 및 하한 제약이 없습니다. [0,1] 또는 [-1,1]과 같은 간격으로 제한되어야하는 경우 스케일 매개 변수를 조정할 수 있습니다. 예는 다음과 같습니다.
print ( " n sentiment dictionary using default seed words" )
docs = [ "张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资" ,
"打倒万恶的资本家" ,
"该公司原定资本总额为二十五万万元,现已由各界分认达二十万万元,所属各厂、各公司亦募得股金一万万余元" ,
"连日来解放区以外各工商人士,投函向该公司询问经营性质与范围以及股东权限等问题者甚多,络绎抵此的许多资本家,于参观该公司所属各厂经营状况后,对民主政府扶助与奖励私营企业发展的政策,均极表赞同,有些资本家因款项未能即刻汇来,多向筹备处预认投资的额数。由平津来张的林明棋先生,一次即以现款入股六十余万元"
]
# scale: 将所有词语的情感值范围调整到[-1,1]
# 省略pos_seeds, neg_seeds,将采用默认的情感词典 get_qh_sent_dict()
print ( "scale= " 0-1 " , 按照最大为1,最小为0进行线性伸缩,0.5未必是中性" )
sent_dict = ht . build_sent_dict ( docs , min_times = 1 , scale = "0-1" )
print ( "%s:%f" % ( "赞同" , sent_dict [ "赞同" ]))
print ( "%s:%f" % ( "二十万" , sent_dict [ "二十万" ]))
print ( "%s:%f" % ( "万恶" , sent_dict [ "万恶" ]))
print ( "%f:%s" % ( ht . analyse_sent ( docs [ 0 ]), docs [ 0 ]))
print ( "%f:%s" % ( ht . analyse_sent ( docs [ 1 ]), docs [ 1 ])) sentiment dictionary using default seed words
scale="0-1", 按照最大为1,最小为0进行线性伸缩,0.5未必是中性
赞同:1.000000
二十万:0.153846
万恶:0.000000
0.449412:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
0.364910:打倒万恶的资本家
print("scale="+-1", 在正负区间内分别伸缩,保留0作为中性的语义")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="+-1")
print("%s:%f" % ("赞同",sent_dict["赞同"]))
print("%s:%f" % ("二十万",sent_dict["二十万"]))
print("%s:%f" % ("万恶",sent_dict["万恶"]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))
scale="+-1", 在正负区间内分别伸缩,保留0作为中性的语义
赞同:1.000000
二十万:0.000000
万恶:-1.000000
0.349305:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
-0.159652:打倒万恶的资本家
문서 목록에서 해당 엔티티 (및 별칭)가 포함 된 문서를 찾아서 엔티티가 포함 된 문서 수를 계산할 수 있습니다. 반전 인덱스와 함께 데이터 구조를 사용하여 빠른 검색을 완료하십시오.
다음 코드는 엔티티를 추가하는 과정에서 발췌 한 것입니다. Add_entities와 같은 기능을 사용하여주의를 기울이고 싶은 엔티티를 추가 한 다음 색인 및 검색을하십시오.
docs = [ "武磊威武,中超第一射手!" ,
"郜林看来不行,已经到上限了。" ,
"武球王威武,中超最强前锋!" ,
"武磊和郜林,谁是中国最好的前锋?" ]
inv_index = ht . build_index ( docs )
print ( ht . get_entity_counts ( docs , inv_index )) # 获得文档中所有实体的出现次数
# {'武磊': 3, '郜林': 2, '前锋': 2}
print ( ht . search_entity ( "武磊" , docs , inv_index )) # 单实体查找
# ['武磊威武,中超第一射手!', '武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
print ( ht . search_entity ( "武磊 郜林" , docs , inv_index )) # 多实体共现
# ['武磊和郜林,谁是中国最好的前锋?']
# 谁是最被人们热议的前锋?用这里的接口可以很简便地回答这个问题
subdocs = ht . search_entity ( "#球员# 前锋" , docs , inv_index )
print ( subdocs ) # 实体、实体类型混合查找
# ['武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
inv_index2 = ht . build_index ( subdocs )
print ( ht . get_entity_counts ( subdocs , inv_index2 , used_type = [ "球员" ])) # 可以限定类型
# {'武磊': 2, '郜林': 1}(NetworkX를 사용하여 구현) Word Co-Currence 관계를 사용하여 본문 사이의 그래프 구조 사이의 네트워크 관계를 설정하십시오 (NetworkX.graph 유형으로 돌아 가기). 캐릭터 사이에 소셜 네트워크를 구축하는 데 사용될 수 있습니다.
# 在现有实体库的基础上随时新增,比如从新词发现中得到的漏网之鱼
ht . add_new_entity ( "颜骏凌" , "颜骏凌" , "球员" )
docs = [ "武磊和颜骏凌是队友" ,
"武磊和郜林都是国内顶尖前锋" ]
G = ht . build_entity_graph ( docs )
print ( dict ( G . edges . items ()))
G = ht . build_entity_graph ( docs , used_types = [ "球员" ])
print ( dict ( G . edges . items ()))단어를 중심으로하는 단어 네트워크를 얻습니다. 주인공 Liu Bei의 만남을 탐구하기위한 세 왕국의 첫 번째 장을 예로 들어보십시오 (다음은 주요 코드입니다.
entity_mention_dict , entity_type_dict = get_sanguo_entity_dict ()
ht0 . add_entities ( entity_mention_dict , entity_type_dict )
sanguo1 = get_sanguo ()[ 0 ]
stopwords = get_baidu_stopwords ()
docs = ht0 . cut_sentences ( sanguo1 )
G = ht0 . build_word_ego_graph ( docs , "刘备" , min_freq = 3 , other_min_freq = 2 , stopwords = stopwords )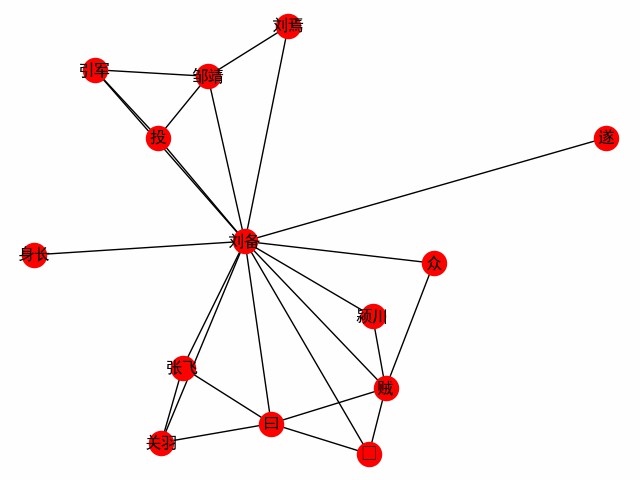
이것은 Liu, Guan 및 Zhang, Liu Bei가 결함이있는 후원자와 도둑과의 싸움에 대한 Liu Bei의 경험입니다.
(NetworkX를 사용하여 구현) TextTrank 알고리즘을 사용하여 문서 컬렉션에서 추출 된 대표 문장을 요약 정보로 얻습니다. 중복을 처벌하는 문장을 설정하거나 단어 제한 (Maxlen 매개 변수)을 설정할 수 있습니다.
print ( " n Text summarization" )
docs = [ "武磊威武,中超第一射手!" ,
"郜林看来不行,已经到上限了。" ,
"武球王威武,中超最强前锋!" ,
"武磊和郜林,谁是中国最好的前锋?" ]
for doc in ht . get_summary ( docs , topK = 2 ):
print ( doc )
print ( " n Text summarization(避免重复)" )
for doc in ht . get_summary ( docs , topK = 3 , avoid_repeat = True ):
print ( doc ) Text summarization
武球王威武,中超最强前锋!
武磊威武,中超第一射手!
Text summarization(避免重复)
武球王威武,中超最强前锋!
郜林看来不行,已经到上限了。
武磊和郜林,谁是中国最好的前锋?
현재 textrank 및 HarvestText를 포함하여 Jieba를 캡슐화하고 매개 변수를 구성하고 jieba_tfidf 중지하는 두 가지 알고리즘이 있습니다.
예제 (완료에 대한 예제 참조) :
# text为林俊杰《关键词》歌词
print ( "《关键词》里的关键词" )
kwds = ht . extract_keywords ( text , 5 , method = "jieba_tfidf" )
print ( "jieba_tfidf" , kwds )
kwds = ht . extract_keywords ( text , 5 , method = "textrank" )
print ( "textrank" , kwds ) 《关键词》里的关键词
jieba_tfidf ['自私', '慷慨', '落叶', '消逝', '故事']
textrank ['自私', '落叶', '慷慨', '故事', '位置']
csl.ipynb는 CSL 데이터 세트에서 Textrank4zh 와이 라이브러리의 구현을 비교할뿐만 아니라 다양한 알고리즘을 제공합니다. 데이터 세트가 하나만 있고 데이터 세트는 위의 알고리즘에 친숙하지 않기 때문에 성능은 참조 용입니다.
| 연산 | p@5 | r@5 | f@5 |
|---|---|---|---|
| Textrank4zh | 0.0836 | 0.1174 | 0.0977 |
| ht_texttransk | 0.0955 | 0.1342 | 0.1116 |
| ht_jieba_tfidf | 0.1035 | 0.1453 | 0.1209 |
이제 일부 리소스 가이 라이브러리에 통합되어 사용을 용이하게하고 데모를 설정합니다.
리소스는 다음과 같습니다.
get_qh_sent_dict : Tsinghua University의 준수 및 비평 사전 li Jun jun http://nlp.csai.tsinghua.edu.cn/site2/index.php/13-Sms에서 편집했습니다.get_baidu_stopwords : Baidu 중지 단어 사전 사전은 인터넷에서 나옵니다 : https://wenku.baidu.com/view/98c46383e53a580216fcfed9.htmlget_qh_typed_words : tsinghua thunlp의 도메인 사전 : http://thuocl.thunlp.org/ 모든 유형 ['IT', '动物', '医药', '历史人名', '地名', '成语', '法律', '财经', '食物']get_english_senti_lexicon : 영어 감성 사전get_jieba_dict : (다운로드해야합니다) jieba 단어 주파수 사전또한 특별한 자원이 제공됩니다.
어떤 흥미로운 발견을 얻을 수 있는지 탐구 할 수 있습니까?
def load_resources ():
from harvesttext . resources import get_qh_sent_dict , get_baidu_stopwords , get_sanguo , get_sanguo_entity_dict
sdict = get_qh_sent_dict () # {"pos":[积极词...],"neg":[消极词...]}
print ( "pos_words:" , list ( sdict [ "pos" ])[ 10 : 15 ])
print ( "neg_words:" , list ( sdict [ "neg" ])[ 5 : 10 ])
stopwords = get_baidu_stopwords ()
print ( "stopwords:" , list ( stopwords )[ 5 : 10 ])
docs = get_sanguo () # 文本列表,每个元素为一章的文本
print ( "三国演义最后一章末16字: n " , docs [ - 1 ][ - 16 :])
entity_mention_dict , entity_type_dict = get_sanguo_entity_dict ()
print ( "刘备 指称:" , entity_mention_dict [ "刘备" ])
print ( "刘备 类别:" , entity_type_dict [ "刘备" ])
print ( "蜀 类别:" , entity_type_dict [ "蜀" ])
print ( "益州 类别:" , entity_type_dict [ "益州" ])
load_resources () pos_words: ['宰相肚里好撑船', '查实', '忠实', '名手', '聪明']
neg_words: ['散漫', '谗言', '迂执', '肠肥脑满', '出卖']
stopwords: ['apart', '左右', '结果', 'probably', 'think']
三国演义最后一章末16字:
鼎足三分已成梦,后人凭吊空牢骚。
刘备 指称: ['刘备', '刘玄德', '玄德']
刘备 类别: 人名
蜀 类别: 势力
益州 类别: 州名
Tsinghua 현장 사전을로드하고 중지 단어를 사용하십시오.
def using_typed_words ():
from harvesttext . resources import get_qh_typed_words , get_baidu_stopwords
ht0 = HarvestText ()
typed_words , stopwords = get_qh_typed_words (), get_baidu_stopwords ()
ht0 . add_typed_words ( typed_words )
sentence = "THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。"
print ( sentence )
print ( ht0 . posseg ( sentence , stopwords = stopwords ))
using_typed_words () THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。
[('THUOCL', 'eng'), ('自然语言处理', 'IT'), ('一套', 'm'), ('中文', 'nz'), ('词库', 'n'), ('词表', 'n'), ('来自', 'v'), ('主流', 'b'), ('网站', 'n'), ('社会', 'n'), ('标签', '财经'), ('搜索', 'v'), ('热词', 'n'), ('输入法', 'IT'), ('词库', 'n')]
일부 단어에는 특별한 유형이 주어지고 "예"와 같은 단어가 선별됩니다.
일부 통계 지표를 사용하여 비교적 많은 텍스트에서 새로운 단어를 발견하십시오. (선택 사항) 품질의 정도를 결정하는 단어는 씨앗 단어를 제공하여 찾을 수 있습니다. (즉, 특정 기본 요구 사항이 충족된다는 전제로 최소한 모든 종자 단어가 발견 될 것입니다.)
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
#返回关于新词质量的一系列信息,允许手工改进筛选(pd.DataFrame型)
new_words_info = ht . word_discover ( para )
#new_words_info = ht.word_discover(para, threshold_seeds=["武磊"])
new_words = new_words_info . index . tolist ()
print ( new_words )[ "Wu Lei"]
알고리즘은 기본 경험적 매개 변수를 사용합니다. 결과 수에 만족하지 않으면 auto_param=False 를 설정하여 매개 변수를 직접 조정하고 최종 결과 수를 조정할 수 있습니다. 관련 매개 변수는 다음과 같습니다.
:param max_word_len: 允许被发现的最长的新词长度
:param min_freq: 被发现的新词,在给定文本中需要达到的最低频率
:param min_entropy: 被发现的新词,在给定文本中需要达到的最低左右交叉熵
:param min_aggregation: 被发现的新词,在给定文本中需要达到的最低凝聚度
예를 들어, 기본값보다 더 많은 결과를 얻으려면 (예 : 일부 새 단어가 발견되지 않음) 기본 매개 변수와 다음 기본 매개 변수를 기반으로 하향 조절할 수 있습니다.
min_entropy = np.log(length) / 10
min_freq = min(0.00005, 20.0 / length)
min_aggregation = np.sqrt(length) / 15
특정 알고리즘 세부 정보 및 매개 변수 의미는 다음을 참조하십시오. http://www.matrix67.com/blog/archives/5044
피드백 업데이트에 따르면 원래 기본적으로 별도의 문자열을 수락했습니다. 이제 문자열 목록 입력을 허용 할 수 있으며 자동으로 스 플라이 싱됩니다.
피드백 업데이트에 따르면 워드 주파수의 기본 순서는 이제 기본적으로 정렬 할 수 있습니다. sort_by='score' 매개 변수를 전달하여 포괄적 인 품질 점수로 정렬 할 수도 있습니다.
발견 된 많은 새로운 단어는 텍스트에서 특별한 키워드 일 수 있으므로, 발견 된 새로운 단어를 로그인하여 후속 분사 가이 단어에 우선 순위를 부여 할 수 있습니다.
def new_word_register ():
new_words = [ "落叶球" , "666" ]
ht . add_new_words ( new_words ) # 作为广义上的"新词"登录
ht . add_new_entity ( "落叶球" , mention0 = "落叶球" , type0 = "术语" ) # 作为特定类型登录
print ( ht . seg ( "这个落叶球踢得真是666" , return_sent = True ))
for word , flag in ht . posseg ( "这个落叶球踢得真是666" ):
print ( "%s:%s" % ( word , flag ), end = " " )이 타락한 잎 공은 실제로 666입니다
this : r 리프 볼 : 용어 킥 : v get : ud really : d 666 : 새로운 단어
또한 특별한 규칙을 사용하여 필요한 키워드를 찾아 영어로 된 모든 유형에 직접 할당하거나 특정 PRES 및 접미사 등을 할 수 있습니다.
# find_with_rules()
from harvesttext . match_patterns import UpperFirst , AllEnglish , Contains , StartsWith , EndsWith
text0 = "我喜欢Python,因为requests库很适合爬虫"
ht0 = HarvestText ()
found_entities = ht0 . find_entity_with_rule ( text0 , rulesets = [ AllEnglish ()], type0 = "英文名" )
print ( found_entities )
print ( ht0 . posseg ( text0 )) {'Python', 'requests'}
[('我', 'r'), ('喜欢', 'v'), ('Python', '英文名'), (',', 'x'), ('因为', 'c'), ('requests', '英文名'), ('库', 'n'), ('很', 'd'), ('适合', 'v'), ('爬虫', 'n')]
텍스트 타일 알고리즘을 사용하여 세그먼트가없는 텍스트를 자동으로 세그먼트하거나 기존 단락을 기반으로 추가로 구성/재시험하십시오.
ht0 = HarvestText ()
text = """备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”"""
print ( "原始文本[5段]" )
print ( text + " n " )
print ( "预测文本[手动设置分3段]" )
predicted_paras = ht0 . cut_paragraphs ( text , num_paras = 3 )
print ( " n " . join ( predicted_paras ) + " n " )原始文本[5段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
预测文本[手动设置分3段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
원래 논문과 달리 문장 결과는 기본 단위로 사용되며 문자 사용은 고정 숫자가 아니므로 의미 적으로 더 명확하고 매개 변수 설정 문제를 저장합니다. 따라서 기본 설정의 알고리즘은 구두점없이 텍스트를 지원하지 않습니다. 그러나 seq_chars 양의 정수로 설정하여 구두점없이 텍스트를 세그먼트로 설정하여 원본 용지의 설정을 사용할 수 있습니다. 단락 래핑이 없으면 align_boundary=False 설정하십시오. 예를 들어, examples/basic.py 의 cut_paragraph() 참조하십시오.
print ( "去除标点以后的分段" )
text2 = extract_only_chinese ( text )
predicted_paras2 = ht0 . cut_paragraphs ( text2 , num_paras = 5 , seq_chars = 10 , align_boundary = False )
print ( " n " . join ( predicted_paras2 ) + " n " )去除标点以后的分段
备受社会关注的湖南常德滴滴司机遇害案将于月日时许在汉寿县人民法院开庭审理此前犯罪嫌疑人岁大学生杨某淇被鉴定为作案时患有抑郁症为有
限定刑事责任能力新京报此前报道年
月日凌晨滴滴司机陈师
傅搭载岁大学生杨某淇到常南汽车总站附近坐在后排的杨某淇趁陈某不备朝陈某连捅数刀致其死亡事发监控显示杨某淇杀人后下车离开随后杨某淇
到公安机关自首并供述称因悲观厌世精神崩溃无故将司机杀害据杨某淇就读学校的工作人员称他家有四口人姐姐是聋哑人今日上午田女士告诉新京
报记者明日开庭时间不变此前已提出刑事附带民事赔偿但通过与法院的沟通后获知对方父母已经没有赔偿的意愿当时按照人身死亡赔偿金计算共计
多万元那时也想考虑对方家庭的经济状况田女士说她相信法律对最后的结果也做好心理准备对方一家从未道歉此前庭前会议中对方提
出了嫌疑人杨某淇作案时患有抑郁症的辩护意见另具警方出具的鉴定书显示嫌疑人作案时有限定刑事责任能力新京
报记者从陈师傅的家属处获知陈师傅有两个儿子大儿子今年岁小儿子还不到岁这对我来说是一起悲剧对我们生活的影响肯定是很大的田女士告诉新
京报记者丈夫遇害后他们一家的主劳动力没有了她自己带着两个孩子和两个老人一起过生活很艰辛她说还好有妹妹的陪伴现在已经好些了
모델을 로컬로 저장하고 멀티플렉싱하거나 현재 모델의 레코드를 제거 할 수 있습니다.
from harvesttext import loadHT , saveHT
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
saveHT ( ht , "ht_model1" )
ht2 = loadHT ( "ht_model1" )
# 消除记录
ht2 . clear ()
print ( "cut with cleared model" )
print ( ht2 . seg ( para ))특정 구현 및 예제는 NaiveKGQA.Py에 있으며 일부 도식은 다음과 같습니다.
QA = NaiveKGQA ( SVOs , entity_type_dict = entity_type_dict )
questions = [ "你好" , "孙中山干了什么事?" , "谁发动了什么?" , "清政府签订了哪些条约?" ,
"英国与鸦片战争的关系是什么?" , "谁复辟了帝制?" ]
for question0 in questions :
print ( "问:" + question0 )
print ( "答:" + QA . answer ( question0 ))问:孙中山干了什么事?
答:就任临时大总统、发动护法运动、让位于袁世凯
问:谁发动了什么?
答:英法联军侵略中国、国民党人二次革命、英国鸦片战争、日本侵略朝鲜、孙中山护法运动、法国侵略越南、英国侵略中国西藏战争、慈禧太后戊戌政变
问:清政府签订了哪些条约?
答:北京条约、天津条约
问:英国与鸦片战争的关系是什么?
答:发动
问:谁复辟了帝制?
答:袁世凯
이 라이브러리는 주로 중국어의 데이터 마이닝을 지원하도록 설계되었지만 감정 분석을 포함하여 소량의 영어 지원을 추가했습니다.
이러한 기능을 사용하려면 특별한 영어 패턴의 HarvestText 객체를 만들어야합니다.
# ♪ "Until the Day" by JJ Lin
test_text = """
In the middle of the night.
Lonely souls travel in time.
Familiar hearts start to entwine.
We imagine what we'll find, in another life.
""" . lower ()
ht_eng = HarvestText ( language = "en" )
sentences = ht_eng . cut_sentences ( test_text ) # 分句
print ( " n " . join ( sentences ))
print ( ht_eng . seg ( sentences [ - 1 ])) # 分词[及词性标注]
print ( ht_eng . posseg ( sentences [ 0 ], stopwords = { "in" }))
# 情感分析
sent_dict = ht_eng . build_sent_dict ( sentences , pos_seeds = [ "familiar" ], neg_seeds = [ "lonely" ],
min_times = 1 , stopwords = { 'in' , 'to' })
print ( "sentiment analysis" )
for sent0 in sentences :
print ( sent0 , "%.3f" % ht_eng . analyse_sent ( sent0 ))
# 自动分段
print ( "Segmentation" )
print ( " n " . join ( ht_eng . cut_paragraphs ( test_text , num_paras = 2 )))
# 情感分析也提供了一个内置英文词典资源
# from harvesttext.resources import get_english_senti_lexicon
# sent_lexicon = get_english_senti_lexicon()
# sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=sent_lexicon["pos"], neg_seeds=sent_lexicon["neg"], min_times=1) in the middle of the night.
lonely souls travel in time.
familiar hearts start to entwine.
we imagine what we'll find, in another life.
['we', 'imagine', 'what', 'we', "'ll", 'find', ',', 'in', 'another', 'life', '.']
[('the', 'DET'), ('middle', 'NOUN'), ('of', 'ADP'), ('the', 'DET'), ('night', 'NOUN'), ('.', '.')]
sentiment analysis
in the middle of the night. 0.000
lonely souls travel in time. -1.600
familiar hearts start to entwine. 1.600
we imagine what we'll find, in another life. 0.000
Segmentation
in the middle of the night. lonely souls travel in time. familiar hearts start to entwine.
we imagine what we'll find, in another life.
현재 영어에 대한 지원은 완벽하지 않습니다. 위의 예제의 기능을 제외하고 다른 기능은 사용되지 않습니다.
이 라이브러리가 학업에 도움이되면 다음 형식을 참조하십시오.
@misc{zhangHarvestText,
author = {Zhiling Zhang},
title = {HarvestText: A Toolkit for Text Mining and Preprocessing},
journal = {GitHub repository},
howpublished = {url{https://github.com/blmoistawinde/HarvestText}},
year = {2023}
}
이 라이브러리는 개발 중이며 기존 기능 및 더 많은 기능에 대한 추가가 개선 된 것은 차례로 나올 수 있습니다. 문제에 대한 제안을 제공하는 데 오신 것을 환영합니다. 사용하기 쉽다고 생각되면 별도있을 수도 있습니다 ~
영감에 대한 다음 리포지토리 덕분에 :
snownlp
pyhanlp
funnlp
chinesewordsementation
EventTripLesextraction
Textrank4zh


