HarvestText
V0.8
HarvestText: مجموعة أدوات لاستخراج النص والمعالجة المسبقة
وثيقة
تزامن على Github و Code Cloud Gite. إذا قمت بتصفح/تنزيل على Github ، فيمكنك الانتقال إلى Code Cloud للعمل.
HarvestText هي مكتبة تركز على طريقة الإشراف (الضعيفة) التي تدمج معرفة المجال (مثل الأنواع ، الاسم المستعار) لمعالجة وتحليل نصوص مجال محددة ببساطة وكفاءة. إنها مناسبة للعديد من مهام التحليل الاستكشافي الأولي والتحليل الاستكشافي للنص ، ولديها قيمة تطبيق محتملة في تحليل جديد ونص عبر الإنترنت والأدب المهني والمجالات الأخرى.
حالات الاستخدام:
[ملاحظة: تكمل هذه المكتبة فقط تجزئة الكلمات وتحليل المشاعر ، وتستخدم matplotlib لتصور]
يحتوي هذا ReadMe على أمثلة نموذجية للوظائف المختلفة. يمكن العثور على الاستخدام التفصيلي لبعض الوظائف في الوثائق:
وثيقة
الوظائف المحددة هي كما يلي:
جدول المحتويات:
أول تثبيت ، استخدم PIP
pip install --upgrade harvesttextأو أدخل الدليل حيث يوجد setup.py ، ثم سطر الأوامر:
python setup.py installثم في الكود:
from harvesttext import HarvestText
ht = HarvestText ()يمكنك استدعاء الواجهة الوظيفية لهذه المكتبة.
ملاحظة: تتطلب بعض الوظائف تثبيت مكتبات إضافية ، ولكن قد يفشل التثبيت ، لذا يرجى تثبيت يدويًا إذا لزم الأمر.
# 部分英语功能
pip install pattern
# 命名实体识别、句法分析等功能,需要python <= 3.8
pip install pyhanlpبالنظر إلى كيانات معينة ومرادفاتها المحتملة ، وكذلك الكيان المقابل. قم بتسجيل الدخول إلى القاموس ، وقم بتقسيمه أولاً عند فراق الكلمات ، واستخدم النوع المقابل كجزء من الكلام. يمكن أيضًا الحصول على جميع الكيانات ومواقعها في المجموعة بشكل منفصل:
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
entity_mention_dict = { '武磊' :[ '武磊' , '武球王' ], '郜林' :[ '郜林' , '郜飞机' ], '前锋' :[ '前锋' ], '上海上港' :[ '上港' ], '广州恒大' :[ '恒大' ], '单刀球' :[ '单刀' ]}
entity_type_dict = { '武磊' : '球员' , '郜林' : '球员' , '前锋' : '位置' , '上海上港' : '球队' , '广州恒大' : '球队' , '单刀球' : '术语' }
ht . add_entities ( entity_mention_dict , entity_type_dict )
print ( " n Sentence segmentation" )
print ( ht . seg ( para , return_sent = True )) # return_sent=False时,则返回词语列表من هم أفضل المهاجمين في الصين ، بما في ذلك وو لي من شنغهاي سيبغ وغاو لين من Evergrande؟ بالطبع هو وو لي ، ملك كرة وو. هو الأول في قائمة مطلق النار. اتضح أن السيف المنفرد الضعيف قد أحرز تقدماً.
يمكن أن يؤدي استخدام أدوات تجزئة الكلمات التقليدية بسهولة إلى تقسيم "Wuqiong King" إلى "Wuqiong King"
جزء من شرح الكلام ، بما في ذلك الأنواع الخاصة المحددة.
print ( " n POS tagging with entity types" )
for word , flag in ht . posseg ( para ):
print ( "%s:%s" % ( word , flag ), end = " " )SIPG: الفريق: UJ Wu Lei: لاعبين و: C Evergrande: الفريق: UJ Gao Lin: اللاعبين ،: X WHO: R IS: V China: NS BEST: A: UJ Forward: Position؟ : x that: r بالطبع: d is: v wu lei: player wu qiu king: player: ul ،: x he: r is: v terge arge: n first: m ،: x في الأصل: d is: v الضعف: n: uj SOSTORD SWORD: أيضًا: D HAS: V: V Progress
for span , entity in ht . entity_linking ( para ):
print ( span , entity )[0 ، 2] " [28 ، 31] ('wu lei' ، '# player#') [47 ، 49] ('Single-on-One Ball' ، '# term#')
هنا ، يمكن أن يسهل تحول "Wuqiu King" إلى مصطلح قياسي "Wu Lei" العمل الإحصائي الموحد.
جملة:
print ( ht . cut_sentences ( para ))["من هو أفضل مهاجم في الصين من شنغهاي سيبغ وغاو لين من Evergrande؟ "، بالطبع ، هو ملك كرة القدم وو لي لي. هو الأول في قائمة مطلق النار. اتضح أن السيف المنفرد الضعيف قد أحرز تقدماً "]
إذا لم يكن هناك قاموس متاح في متناول اليد في الوقت الحالي ، فيمكنك أيضًا معرفة ما إذا كان قاموس المجال في الموارد المدمجة لهذه المكتبة مناسبًا لاحتياجاتك.
إذا كان هناك العديد من الكيانات الممكنة لنفس الاسم ("Li Na Play Ball و Li Na الغناء ليسوا نفس الشخص") ، فيمكنك تعيين keep_all=True للاحتفاظ بمرشحين متعددين. يمكنك استخدام استراتيجيات أخرى لإلصاقها لاحقًا ، راجع el_keep_all ()
إذا كان هناك الكثير من الكيانات المرتبطة بها ، وبعضها من الواضح أنه غير معقول ، فيمكن استخدام بعض الاستراتيجيات للتصفية. فيما يلي مثال Filter_el_with_rule ()
يمكن أن تستخدم هذه المكتبة أيضًا بعض الاستراتيجيات الأساسية للتعامل مع مهام عدم الغموض المعقدة للكيانات (مثل المعاني المتعددة للكلمة ["المعلم" يشير إلى "المعلم" أو "المعلم B"؟] ، وتتداخل الكلمات المرشحة [Mayor XX/Jiang yy؟ ، Mayor XX/Jiang yy؟]). للحصول على التفاصيل ، يمكنك رؤية linking_strategy ()
يمكنك معالجة أحرف خاصة في النص ، أو إزالة بعض التنسيقات الخاصة التي لا تريد الظهور في النص.
بما في ذلك: @، emoji على Weibo ؛ عنوان URL بريد إلكتروني؛ أحرف خاصة في كود HTML ؛ شخصيات خاصة في ٪ 20 في عنوان URL ؛ الصينيين التقليديين إلى الصينيين
الأمثلة على النحو التالي:
print ( "各种清洗文本" )
ht0 = HarvestText ()
# 默认的设置可用于清洗微博文本
text1 = "回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]"
print ( "清洗微博【@和表情符等】" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 ))各种清洗文本
清洗微博【@和表情符等】
原: 回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]
清洗后: 杨大哥
# URL的清理
text1 = "【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ"
print ( "清洗网址URL" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , remove_url = True ))清洗网址URL
原: 【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ
清洗后: 【#赵薇#:正筹备下一部电影 但不是青春片....
# 清洗邮箱
text1 = "我的邮箱是[email protected],欢迎联系"
print ( "清洗邮箱" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , email = True ))清洗邮箱
原: 我的邮箱是[email protected],欢迎联系
清洗后: 我的邮箱是,欢迎联系
# 处理URL转义字符
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print ( "URL转正常字符" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , norm_url = True , remove_url = False )) URL转正常字符
原: www.%E4%B8%AD%E6%96%87%20and%20space.com
清洗后: www.中文 and space.com
text1 = "www.中文 and space.com"
print ( "正常字符转URL[含有中文和空格的request需要注意]" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , to_url = True , remove_url = False ))正常字符转URL[含有中文和空格的request需要注意]
原: www.中文 and space.com
清洗后: www.%E4%B8%AD%E6%96%87%20and%20space.com
# 处理HTML转义字符
text1 = "<a c> ''"
print ( "HTML转正常字符" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , norm_html = True )) HTML转正常字符
原: <a c> ''
清洗后: <a c> ''
# 繁体字转简体
text1 = "心碎誰買單"
print ( "繁体字转简体" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , t2s = True ))繁体字转简体
原: 心碎誰買單
清洗后: 心碎谁买单
# markdown超链接提取文本
text1 = "欢迎使用[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)这个库"
print ( "markdown超链接提取文本" )
print ( "原:" , text1 )
print ( "清洗后:" , ht0 . clean_text ( text1 , t2s = True )) markdown超链接提取文本
原: 欢迎使用[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)这个库
清洗后: 欢迎使用HarvestText : A Toolkit for Text Mining and Preprocessing这个库
ابحث عن اسم الشخص ، والمكان ، والمنظمة ، وما إلى ذلك في جملة. يتم استخدام تطبيق واجهة Pyhanlp.
ht0 = HarvestText ()
sent = "上海上港足球队的武磊是中国最好的前锋。"
print ( ht0 . named_entity_recognition ( sent )) {'上海上港足球队': '机构名', '武磊': '人名', '中国': '地名'}
قم بتحليل تعديل كائن الموضوع والعلاقات النحوية الأخرى لكل كلمة في بيان (بما في ذلك الكيان المرتبط) واستخراج ثلاث مرات الحدث الممكنة. يتم استخدام تطبيق واجهة Pyhanlp.
ht0 = HarvestText ()
para = "上港的武磊武球王是中国最好的前锋。"
entity_mention_dict = { '武磊' : [ '武磊' , '武球王' ], "上海上港" :[ "上港" ]}
entity_type_dict = { '武磊' : '球员' , "上海上港" : "球队" }
ht0 . add_entities ( entity_mention_dict , entity_type_dict )
for arc in ht0 . dependency_parse ( para ):
print ( arc )
print ( ht0 . triple_extraction ( para )) [0, '上港', '球队', '定中关系', 3]
[1, '的', 'u', '右附加关系', 0]
[2, '武磊', '球员', '定中关系', 3]
[3, '武球王', '球员', '主谓关系', 4]
[4, '是', 'v', '核心关系', -1]
[5, '中国', 'ns', '定中关系', 8]
[6, '最好', 'd', '定中关系', 8]
[7, '的', 'u', '右附加关系', 6]
[8, '前锋', 'n', '动宾关系', 4]
[9, '。', 'w', '标点符号', 4]
print ( ht0 . triple_extraction ( para )) [['上港武磊武球王', '是', '中国最好前锋']]
تم تعديله في الإصدار V0.7 ، استخدم التسامح لدعم نفس فحص Pinyin
ارتباط الكلمات في العبارة التي قد تكون كيانًا معروفًا (مع وجود حرف واحد أو خطأ بينيين) إلى الكيان المقابل.
def entity_error_check ():
ht0 = HarvestText ()
typed_words = { "人名" :[ "武磊" ]}
ht0 . add_typed_words ( typed_words )
sent0 = "武磊和吴磊拼音相同"
print ( sent0 )
print ( ht0 . entity_linking ( sent0 , pinyin_tolerance = 0 ))
"""
武磊和吴磊拼音相同
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent1 = "武磊和吴力只差一个拼音"
print ( sent1 )
print ( ht0 . entity_linking ( sent1 , pinyin_tolerance = 1 ))
"""
武磊和吴力只差一个拼音
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent2 = "武磊和吴磊只差一个字"
print ( sent2 )
print ( ht0 . entity_linking ( sent2 , char_tolerance = 1 ))
"""
武磊和吴磊只差一个字
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
"""
sent3 = "吴磊和吴力都可能是武磊的代称"
print ( sent3 )
print ( ht0 . get_linking_mention_candidates ( sent3 , pinyin_tolerance = 1 , char_tolerance = 1 ))
"""
吴磊和吴力都可能是武磊的代称
('吴磊和吴力都可能是武磊的代称', defaultdict(<class 'list'>, {(0, 2): {'武磊'}, (3, 5): {'武磊'}}))
"""تستخدم هذه المكتبة طريقة قاموس العاطفة لإجراء تحليل العاطفة ، وتتعلم تلقائيًا الميول العاطفية للكلمات الأخرى من المجموعة من خلال توفير عدد صغير من الكلمات الإيجابية والسلبية القياسية ("كلمات البذور") لتشكيل قاموس عاطفي. يتم استخدام ملخص ومتوسط الكلمات العاطفية في الاقتصاد للحكم على الاتجاه العاطفي للحكم:
print ( " n sentiment dictionary" )
sents = [ "武磊威武,中超第一射手!" ,
"武磊强,中超最第一本土球员!" ,
"郜林不行,只会抱怨的球员注定上限了" ,
"郜林看来不行,已经到上限了" ]
sent_dict = ht . build_sent_dict ( sents , min_times = 1 , pos_seeds = [ "第一" ], neg_seeds = [ "不行" ])
print ( "%s:%f" % ( "威武" , sent_dict [ "威武" ]))
print ( "%s:%f" % ( "球员" , sent_dict [ "球员" ]))
print ( "%s:%f" % ( "上限" , sent_dict [ "上限" ]))القاموس المشاعر: 1.000000 لاعب: 0.000000 غطاء: -1.0000000
print ( " n sentence sentiment" )
sent = "武球王威武,中超最强球员!"
print ( "%f:%s" % ( ht . analyse_sent ( sent ), sent ))0.600000: ملك فنون القتال هو أقوى لاعب في الدوري الصيني الممتاز!
إذا لم تكن قد اكتشفت الكلمات التي يجب اختيارها كـ "كلمات بذرة" ، فإن هذه المكتبة لديها أيضًا مورد مدمج للقاموس العاطفي العام ، وهو الخيار الافتراضي عند عدم تحديد الكلمات العاطفية ، ويمكنك أيضًا اختيارها حسب الحاجة.
لا تحتوي خوارزمية So-PMI المستخدمة افتراضيًا على قيود أعلى وأسفل على القيم العاطفية. إذا كان من الضروري أن يقتصر على فترات مثل [0،1] أو [-1،1] ، فيمكنك ضبط معلمات المقياس. الأمثلة على النحو التالي:
print ( " n sentiment dictionary using default seed words" )
docs = [ "张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资" ,
"打倒万恶的资本家" ,
"该公司原定资本总额为二十五万万元,现已由各界分认达二十万万元,所属各厂、各公司亦募得股金一万万余元" ,
"连日来解放区以外各工商人士,投函向该公司询问经营性质与范围以及股东权限等问题者甚多,络绎抵此的许多资本家,于参观该公司所属各厂经营状况后,对民主政府扶助与奖励私营企业发展的政策,均极表赞同,有些资本家因款项未能即刻汇来,多向筹备处预认投资的额数。由平津来张的林明棋先生,一次即以现款入股六十余万元"
]
# scale: 将所有词语的情感值范围调整到[-1,1]
# 省略pos_seeds, neg_seeds,将采用默认的情感词典 get_qh_sent_dict()
print ( "scale= " 0-1 " , 按照最大为1,最小为0进行线性伸缩,0.5未必是中性" )
sent_dict = ht . build_sent_dict ( docs , min_times = 1 , scale = "0-1" )
print ( "%s:%f" % ( "赞同" , sent_dict [ "赞同" ]))
print ( "%s:%f" % ( "二十万" , sent_dict [ "二十万" ]))
print ( "%s:%f" % ( "万恶" , sent_dict [ "万恶" ]))
print ( "%f:%s" % ( ht . analyse_sent ( docs [ 0 ]), docs [ 0 ]))
print ( "%f:%s" % ( ht . analyse_sent ( docs [ 1 ]), docs [ 1 ])) sentiment dictionary using default seed words
scale="0-1", 按照最大为1,最小为0进行线性伸缩,0.5未必是中性
赞同:1.000000
二十万:0.153846
万恶:0.000000
0.449412:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
0.364910:打倒万恶的资本家
print("scale="+-1", 在正负区间内分别伸缩,保留0作为中性的语义")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="+-1")
print("%s:%f" % ("赞同",sent_dict["赞同"]))
print("%s:%f" % ("二十万",sent_dict["二十万"]))
print("%s:%f" % ("万恶",sent_dict["万恶"]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))
scale="+-1", 在正负区间内分别伸缩,保留0作为中性的语义
赞同:1.000000
二十万:0.000000
万恶:-1.000000
0.349305:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
-0.159652:打倒万恶的资本家
يمكنك العثور على مستندات تحتوي على الكيان المقابل (ومستعاره) من قائمة المستندات ، وحساب عدد المستندات التي تحتوي على كيان. استخدم بنية البيانات مع فهارس مقلوبة لإكمال استرجاع سريع.
الكود التالي هو مقتطف من عملية إضافة الكيانات. يرجى استخدام وظائف مثل add_entities لإضافة الكيان الذي تريد الانتباه إليه ، ثم الفهرس والبحث.
docs = [ "武磊威武,中超第一射手!" ,
"郜林看来不行,已经到上限了。" ,
"武球王威武,中超最强前锋!" ,
"武磊和郜林,谁是中国最好的前锋?" ]
inv_index = ht . build_index ( docs )
print ( ht . get_entity_counts ( docs , inv_index )) # 获得文档中所有实体的出现次数
# {'武磊': 3, '郜林': 2, '前锋': 2}
print ( ht . search_entity ( "武磊" , docs , inv_index )) # 单实体查找
# ['武磊威武,中超第一射手!', '武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
print ( ht . search_entity ( "武磊 郜林" , docs , inv_index )) # 多实体共现
# ['武磊和郜林,谁是中国最好的前锋?']
# 谁是最被人们热议的前锋?用这里的接口可以很简便地回答这个问题
subdocs = ht . search_entity ( "#球员# 前锋" , docs , inv_index )
print ( subdocs ) # 实体、实体类型混合查找
# ['武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
inv_index2 = ht . build_index ( subdocs )
print ( ht . get_entity_counts ( subdocs , inv_index2 , used_type = [ "球员" ])) # 可以限定类型
# {'武磊': 2, '郜林': 1}(تم تنفيذه باستخدام NetworkX) استخدم علاقات Word Co-Corcatrence لإنشاء علاقة شبكة بين هياكل الرسم البياني بين الهيئات (العودة إلى نوع networkx.graph). يمكن استخدامه لبناء الشبكات الاجتماعية بين الشخصيات ، إلخ.
# 在现有实体库的基础上随时新增,比如从新词发现中得到的漏网之鱼
ht . add_new_entity ( "颜骏凌" , "颜骏凌" , "球员" )
docs = [ "武磊和颜骏凌是队友" ,
"武磊和郜林都是国内顶尖前锋" ]
G = ht . build_entity_graph ( docs )
print ( dict ( G . edges . items ()))
G = ht . build_entity_graph ( docs , used_types = [ "球员" ])
print ( dict ( G . edges . items ()))الحصول على شبكة كلمة تركزت على كلمة. خذ الفصل الأول من الممالك الثلاث كمثال لاستكشاف لقاء بطل الرواية ليو باي (فيما يلي هو الكود الرئيسي ، راجع build_word_ego_graph () على سبيل المثال).
entity_mention_dict , entity_type_dict = get_sanguo_entity_dict ()
ht0 . add_entities ( entity_mention_dict , entity_type_dict )
sanguo1 = get_sanguo ()[ 0 ]
stopwords = get_baidu_stopwords ()
docs = ht0 . cut_sentences ( sanguo1 )
G = ht0 . build_word_ego_graph ( docs , "刘备" , min_freq = 3 , other_min_freq = 2 , stopwords = stopwords )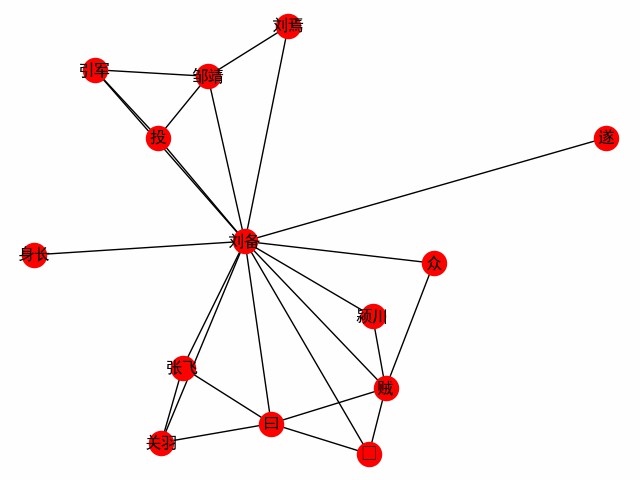
هذه هي الصداقة بين ليو وغوان وتشانغ ، الداعمين الذين انشقوا ليو بي ، وتجربة ليو باي في القتال ضد اللصوص.
(تم تنفيذه باستخدام NetworkX) استخدم خوارزمية TextTrank للحصول على جمل تمثيلية مستخرجة من مجموعة المستندات كمعلومات موجزة. يمكنك تعيين جمل تعاقب التكرارات ، أو يمكنك تعيين حدود الكلمات (معلمة Maxlen):
print ( " n Text summarization" )
docs = [ "武磊威武,中超第一射手!" ,
"郜林看来不行,已经到上限了。" ,
"武球王威武,中超最强前锋!" ,
"武磊和郜林,谁是中国最好的前锋?" ]
for doc in ht . get_summary ( docs , topK = 2 ):
print ( doc )
print ( " n Text summarization(避免重复)" )
for doc in ht . get_summary ( docs , topK = 3 , avoid_repeat = True ):
print ( doc ) Text summarization
武球王威武,中超最强前锋!
武磊威武,中超第一射手!
Text summarization(避免重复)
武球王威武,中超最强前锋!
郜林看来不行,已经到上限了。
武磊和郜林,谁是中国最好的前锋?
حاليًا ، هناك خوارزميتان تتضمن textrank و HarvestText لتغليف Jieba وتكوين المعلمات وإيقاف jieba_tfidf .
مثال (انظر مثال لكامل):
# text为林俊杰《关键词》歌词
print ( "《关键词》里的关键词" )
kwds = ht . extract_keywords ( text , 5 , method = "jieba_tfidf" )
print ( "jieba_tfidf" , kwds )
kwds = ht . extract_keywords ( text , 5 , method = "textrank" )
print ( "textrank" , kwds ) 《关键词》里的关键词
jieba_tfidf ['自私', '慷慨', '落叶', '消逝', '故事']
textrank ['自私', '落叶', '慷慨', '故事', '位置']
يوفر csl.ipynb خوارزميات مختلفة ، وكذلك مقارنة تنفيذ هذه المكتبة مع Textrank4ZH على مجموعة بيانات CSL. نظرًا لوجود مجموعة بيانات واحدة فقط ومجموعة البيانات ليست ودية للخوارزميات المذكورة أعلاه ، فإن الأداء هو للرجوع إليه فقط.
| خوارزمية | P@5 | ص@5 | و@5 |
|---|---|---|---|
| Textrank4zh | 0.0836 | 0.1174 | 0.0977 |
| ht_texttransk | 0.0955 | 0.1342 | 0.1116 |
| ht_jieba_tfidf | 0.1035 | 0.1453 | 0.1209 |
الآن تم دمج بعض الموارد في هذه المكتبة لتسهيل الاستخدام وإنشاء العروض التوضيحية.
تشمل الموارد:
get_qh_sent_dict : قام القاموس بالامتثال والانتقاد Li Jun من جامعة Tsinghua إلى تجميعها من http://nlp.csai.tsinghua.edu.cn/site2/index.php/13-3get_baidu_stopwords : Baidu Stop Word Dictionary يأتي من الإنترنت: https://wenku.baidu.com/view/98c4638e53a580216fcfed9.htmlget_qh_typed_words : قاموس المجال من tsinghua thunlp: http://thuocl.thunlp.org/ جميع الأنواع ['IT', '动物', '医药', '历史人名', '地名', '成语', '法律', '财经', '食物']get_english_senti_lexicon : القاموس العاطفي الإنجليزيget_jieba_dict : (بحاجة إلى تنزيل) قاموس الترددات Jieba Wordبالإضافة إلى ذلك ، يتم توفير مورد خاص - "رومانسية الممالك الثلاث" ، بما في ذلك:
يمكنك استكشاف الاكتشافات المثيرة للاهتمام التي يمكن الحصول عليها منه؟
def load_resources ():
from harvesttext . resources import get_qh_sent_dict , get_baidu_stopwords , get_sanguo , get_sanguo_entity_dict
sdict = get_qh_sent_dict () # {"pos":[积极词...],"neg":[消极词...]}
print ( "pos_words:" , list ( sdict [ "pos" ])[ 10 : 15 ])
print ( "neg_words:" , list ( sdict [ "neg" ])[ 5 : 10 ])
stopwords = get_baidu_stopwords ()
print ( "stopwords:" , list ( stopwords )[ 5 : 10 ])
docs = get_sanguo () # 文本列表,每个元素为一章的文本
print ( "三国演义最后一章末16字: n " , docs [ - 1 ][ - 16 :])
entity_mention_dict , entity_type_dict = get_sanguo_entity_dict ()
print ( "刘备 指称:" , entity_mention_dict [ "刘备" ])
print ( "刘备 类别:" , entity_type_dict [ "刘备" ])
print ( "蜀 类别:" , entity_type_dict [ "蜀" ])
print ( "益州 类别:" , entity_type_dict [ "益州" ])
load_resources () pos_words: ['宰相肚里好撑船', '查实', '忠实', '名手', '聪明']
neg_words: ['散漫', '谗言', '迂执', '肠肥脑满', '出卖']
stopwords: ['apart', '左右', '结果', 'probably', 'think']
三国演义最后一章末16字:
鼎足三分已成梦,后人凭吊空牢骚。
刘备 指称: ['刘备', '刘玄德', '玄德']
刘备 类别: 人名
蜀 类别: 势力
益州 类别: 州名
قم بتحميل قاموس حقل Tsinghua واستخدم الكلمات.
def using_typed_words ():
from harvesttext . resources import get_qh_typed_words , get_baidu_stopwords
ht0 = HarvestText ()
typed_words , stopwords = get_qh_typed_words (), get_baidu_stopwords ()
ht0 . add_typed_words ( typed_words )
sentence = "THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。"
print ( sentence )
print ( ht0 . posseg ( sentence , stopwords = stopwords ))
using_typed_words () THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。
[('THUOCL', 'eng'), ('自然语言处理', 'IT'), ('一套', 'm'), ('中文', 'nz'), ('词库', 'n'), ('词表', 'n'), ('来自', 'v'), ('主流', 'b'), ('网站', 'n'), ('社会', 'n'), ('标签', '财经'), ('搜索', 'v'), ('热词', 'n'), ('输入法', 'IT'), ('词库', 'n')]
يتم إعطاء بعض الكلمات أنواعًا خاصة منه ، بينما يتم فحص كلمات مثل "نعم".
استخدم بعض المؤشرات الإحصائية لاكتشاف كلمات جديدة من عدد كبير نسبيًا من النصوص. (اختياري) الكلمات التي تحدد درجة الجودة يمكن العثور عليها من خلال توفير بعض كلمات البذور. (أي على الأقل سيتم العثور على جميع كلمات البذور ، على أساس أن هناك متطلبات أساسية معينة.)
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
#返回关于新词质量的一系列信息,允许手工改进筛选(pd.DataFrame型)
new_words_info = ht . word_discover ( para )
#new_words_info = ht.word_discover(para, threshold_seeds=["武磊"])
new_words = new_words_info . index . tolist ()
print ( new_words )["وو لي"]
تستخدم الخوارزمية المعلمات التجريبية الافتراضية. إذا لم تكن راضيًا عن عدد النتائج ، فيمكنك تعيين auto_param=False لضبط المعلمات بنفسك وتعديل عدد النتائج النهائية. المعلمات ذات الصلة هي كما يلي:
:param max_word_len: 允许被发现的最长的新词长度
:param min_freq: 被发现的新词,在给定文本中需要达到的最低频率
:param min_entropy: 被发现的新词,在给定文本中需要达到的最低左右交叉熵
:param min_aggregation: 被发现的新词,在给定文本中需要达到的最低凝聚度
على سبيل المثال ، إذا كنت ترغب في الحصول على نتائج أكثر من الافتراضي (على سبيل المثال ، لم يتم اكتشاف بعض الكلمات الجديدة) ، فيمكنك تنظيمها بناءً على المعلمات الافتراضية ، والمعلمات الافتراضية التالية:
min_entropy = np.log(length) / 10
min_freq = min(0.00005, 20.0 / length)
min_aggregation = np.sqrt(length) / 15
تفاصيل خوارزمية محددة ومعاني المعلمة ، راجع: http://www.matrix67.com/blog/archives/5044
وفقًا لتحديث التغذية المرتدة ، قبلت في الأصل سلسلة منفصلة بشكل افتراضي. الآن يمكن أيضًا قبول إدخال قائمة السلسلة ، وسيتم تقطيعه تلقائيًا
وفقًا لتحديث التغذية المرتدة ، يمكن الآن فرز الترتيب الافتراضي لتردد الكلمات افتراضيًا. يمكنك أيضًا تمرير المعلمة sort_by='score' لفرز درجة الجودة الشاملة.
قد تكون العديد من الكلمات الجديدة التي تم العثور عليها كلمات رئيسية خاصة في النص ، بحيث يمكن تسجيل الكلمات الجديدة التي تم العثور عليها بحيث تعطي المشاركين اللاحقة أولوية لهذه الكلمات.
def new_word_register ():
new_words = [ "落叶球" , "666" ]
ht . add_new_words ( new_words ) # 作为广义上的"新词"登录
ht . add_new_entity ( "落叶球" , mention0 = "落叶球" , type0 = "术语" ) # 作为特定类型登录
print ( ht . seg ( "这个落叶球踢得真是666" , return_sent = True ))
for word , flag in ht . posseg ( "这个落叶球踢得真是666" ):
print ( "%s:%s" % ( word , flag ), end = " " )كرة الأوراق الساقطة هذه هي حقا 666
هذا: R Leaf Ball: المصطلح: V Get: UD حقًا: D 666: كلمة جديدة
يمكنك أيضًا استخدام بعض القواعد الخاصة للعثور على الكلمات الرئيسية المطلوبة وتعيينها مباشرةً إلى النوع ، مثل كل شيء باللغة الإنجليزية ، أو لديك PRES والاحقات المحددة ، إلخ.
# find_with_rules()
from harvesttext . match_patterns import UpperFirst , AllEnglish , Contains , StartsWith , EndsWith
text0 = "我喜欢Python,因为requests库很适合爬虫"
ht0 = HarvestText ()
found_entities = ht0 . find_entity_with_rule ( text0 , rulesets = [ AllEnglish ()], type0 = "英文名" )
print ( found_entities )
print ( ht0 . posseg ( text0 )) {'Python', 'requests'}
[('我', 'r'), ('喜欢', 'v'), ('Python', '英文名'), (',', 'x'), ('因为', 'c'), ('requests', '英文名'), ('库', 'n'), ('很', 'd'), ('适合', 'v'), ('爬虫', 'n')]
استخدم خوارزمية TextTiping لتصنيف النص تلقائيًا دون شرائح ، أو تنظيم/إعادة تنظيم مزيد من التنظيم بناءً على الفقرات الحالية.
ht0 = HarvestText ()
text = """备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”"""
print ( "原始文本[5段]" )
print ( text + " n " )
print ( "预测文本[手动设置分3段]" )
predicted_paras = ht0 . cut_paragraphs ( text , num_paras = 3 )
print ( " n " . join ( predicted_paras ) + " n " )原始文本[5段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
预测文本[手动设置分3段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
على عكس الورقة الأصلية ، يتم استخدام نتيجة الجملة كوحدة أساسية ، ولا يعد استخدام الأحرف رقمًا ثابتًا ، وهو أكثر وضوحًا بشكل أكثر وضوحًا ويوفر مشكلة في تحديد المعلمات. لذلك ، لا تدعم الخوارزمية تحت الإعداد الافتراضي النص دون علامات الترقيم. ومع ذلك ، يمكنك استخدام إعدادات الورقة الأصلية عن طريق تعيين seq_chars على عدد صحيح موجب إلى نص قطاع دون علامات ترقيم. إذا لم يكن هناك غلاف فقرة ، فيرجى تعيين align_boundary=False . على سبيل المثال ، راجع cut_paragraph() في examples/basic.py :
print ( "去除标点以后的分段" )
text2 = extract_only_chinese ( text )
predicted_paras2 = ht0 . cut_paragraphs ( text2 , num_paras = 5 , seq_chars = 10 , align_boundary = False )
print ( " n " . join ( predicted_paras2 ) + " n " )去除标点以后的分段
备受社会关注的湖南常德滴滴司机遇害案将于月日时许在汉寿县人民法院开庭审理此前犯罪嫌疑人岁大学生杨某淇被鉴定为作案时患有抑郁症为有
限定刑事责任能力新京报此前报道年
月日凌晨滴滴司机陈师
傅搭载岁大学生杨某淇到常南汽车总站附近坐在后排的杨某淇趁陈某不备朝陈某连捅数刀致其死亡事发监控显示杨某淇杀人后下车离开随后杨某淇
到公安机关自首并供述称因悲观厌世精神崩溃无故将司机杀害据杨某淇就读学校的工作人员称他家有四口人姐姐是聋哑人今日上午田女士告诉新京
报记者明日开庭时间不变此前已提出刑事附带民事赔偿但通过与法院的沟通后获知对方父母已经没有赔偿的意愿当时按照人身死亡赔偿金计算共计
多万元那时也想考虑对方家庭的经济状况田女士说她相信法律对最后的结果也做好心理准备对方一家从未道歉此前庭前会议中对方提
出了嫌疑人杨某淇作案时患有抑郁症的辩护意见另具警方出具的鉴定书显示嫌疑人作案时有限定刑事责任能力新京
报记者从陈师傅的家属处获知陈师傅有两个儿子大儿子今年岁小儿子还不到岁这对我来说是一起悲剧对我们生活的影响肯定是很大的田女士告诉新
京报记者丈夫遇害后他们一家的主劳动力没有了她自己带着两个孩子和两个老人一起过生活很艰辛她说还好有妹妹的陪伴现在已经好些了
يمكن حفظ النموذج محليًا وقراءة التعدد ، أو يمكن القضاء على سجلات النموذج الحالي.
from harvesttext import loadHT , saveHT
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
saveHT ( ht , "ht_model1" )
ht2 = loadHT ( "ht_model1" )
# 消除记录
ht2 . clear ()
print ( "cut with cleared model" )
print ( ht2 . seg ( para ))توجد تطبيقات وأمثلة محددة في naivekgqa.py ، وبعض المخططات الواردة أدناه:
QA = NaiveKGQA ( SVOs , entity_type_dict = entity_type_dict )
questions = [ "你好" , "孙中山干了什么事?" , "谁发动了什么?" , "清政府签订了哪些条约?" ,
"英国与鸦片战争的关系是什么?" , "谁复辟了帝制?" ]
for question0 in questions :
print ( "问:" + question0 )
print ( "答:" + QA . answer ( question0 ))问:孙中山干了什么事?
答:就任临时大总统、发动护法运动、让位于袁世凯
问:谁发动了什么?
答:英法联军侵略中国、国民党人二次革命、英国鸦片战争、日本侵略朝鲜、孙中山护法运动、法国侵略越南、英国侵略中国西藏战争、慈禧太后戊戌政变
问:清政府签订了哪些条约?
答:北京条约、天津条约
问:英国与鸦片战争的关系是什么?
答:发动
问:谁复辟了帝制?
答:袁世凯
تم تصميم هذه المكتبة بشكل أساسي لدعم استخراج البيانات باللغة الصينية ، لكنها أضافت كمية صغيرة من الدعم باللغة الإنجليزية ، بما في ذلك تحليل المشاعر.
لاستخدام هذه الوظائف ، تحتاج إلى إنشاء كائن HarvestText بنمط إنجليزي خاص.
# ♪ "Until the Day" by JJ Lin
test_text = """
In the middle of the night.
Lonely souls travel in time.
Familiar hearts start to entwine.
We imagine what we'll find, in another life.
""" . lower ()
ht_eng = HarvestText ( language = "en" )
sentences = ht_eng . cut_sentences ( test_text ) # 分句
print ( " n " . join ( sentences ))
print ( ht_eng . seg ( sentences [ - 1 ])) # 分词[及词性标注]
print ( ht_eng . posseg ( sentences [ 0 ], stopwords = { "in" }))
# 情感分析
sent_dict = ht_eng . build_sent_dict ( sentences , pos_seeds = [ "familiar" ], neg_seeds = [ "lonely" ],
min_times = 1 , stopwords = { 'in' , 'to' })
print ( "sentiment analysis" )
for sent0 in sentences :
print ( sent0 , "%.3f" % ht_eng . analyse_sent ( sent0 ))
# 自动分段
print ( "Segmentation" )
print ( " n " . join ( ht_eng . cut_paragraphs ( test_text , num_paras = 2 )))
# 情感分析也提供了一个内置英文词典资源
# from harvesttext.resources import get_english_senti_lexicon
# sent_lexicon = get_english_senti_lexicon()
# sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=sent_lexicon["pos"], neg_seeds=sent_lexicon["neg"], min_times=1) in the middle of the night.
lonely souls travel in time.
familiar hearts start to entwine.
we imagine what we'll find, in another life.
['we', 'imagine', 'what', 'we', "'ll", 'find', ',', 'in', 'another', 'life', '.']
[('the', 'DET'), ('middle', 'NOUN'), ('of', 'ADP'), ('the', 'DET'), ('night', 'NOUN'), ('.', '.')]
sentiment analysis
in the middle of the night. 0.000
lonely souls travel in time. -1.600
familiar hearts start to entwine. 1.600
we imagine what we'll find, in another life. 0.000
Segmentation
in the middle of the night. lonely souls travel in time. familiar hearts start to entwine.
we imagine what we'll find, in another life.
حاليا ، دعم اللغة الإنجليزية ليس مثاليًا. باستثناء الوظائف في الأمثلة المذكورة أعلاه ، لا يتم ضمان استخدام الوظائف الأخرى.
إذا وجدت هذه المكتبة مفيدة لعملك الأكاديمي ، فيرجى الرجوع إلى التنسيق التالي
@misc{zhangHarvestText,
author = {Zhiling Zhang},
title = {HarvestText: A Toolkit for Text Mining and Preprocessing},
journal = {GitHub repository},
howpublished = {url{https://github.com/blmoistawinde/HarvestText}},
year = {2023}
}
هذه المكتبة قيد التطوير ، وقد تأتي التحسينات على الميزات والإضافات الحالية لمزيد من الميزات واحدة تلو الأخرى. مرحبا بكم لتقديم الاقتراحات في القضايا. إذا كنت تعتقد أنه من السهل استخدامه ، فقد يكون لديك أيضًا نجمة ~
بفضل الريبو التالي للإلهام:
snownlp
Pyhanlp
funnlp
ChinesewordSegmentation
EventTriplesextraction
Textrank4zh


