CodeAssist
v0.1.0
Китайский |

Codeassist -это расширенный инструмент завершения кода, который интеллектуально предоставляет высококачественные завершения кода для Python, Java и C ++ и т. Д.
Codeassist-это высококачественный инструмент завершения кода, который завершает код для языков программирования, таких как Python, Java и C ++.
Python , Java , C++ , javascript и т. Д.| Архи | BaseModel | Модель | Размер модели |
|---|---|---|---|
| Гф | GPT2 | Shibing624/Code-Autocoplete-gpt2-base | 487 МБ |
| Гф | Distilgpt2 | shibing624/code-autocoplete-distilgpt2-python | 319 МБ |
| Гф | BigCode/StarCoder | Wizardlm/WizardCoder-15B-V1.0 | 29 ГБ |
Demo GuggingFace: https://huggingface.co/spaces/shibing624/code-autocopplite
Бэкэнд-модель: shibing624/code-autocomplete-gpt2-base
pip install torch # conda install pytorch
pip install -U codeassistили
git clone https://github.com/shibing624/codeassist.git
cd CodeAssist
python setup.py install WizardCoder-15B-это точный настройка bigcode/starcoder с данными кода Alpaca, вы можете использовать следующий код для генерации кода:
Пример: примеры/wizardcoder_demo.py
import sys
sys . path . append ( '..' )
from codeassist import WizardCoder
m = WizardCoder ( "WizardLM/WizardCoder-15B-V1.0" )
print ( m . generate ( 'def load_csv_file(file_path):' )[ 0 ])выход:
import csv
def load_csv_file ( file_path ):
"""
Load data from a CSV file and return a list of dictionaries.
"""
# Open the file in read mode
with open ( file_path , 'r' ) as file :
# Create a CSV reader object
csv_reader = csv . DictReader ( file )
# Initialize an empty list to store the data
data = []
# Iterate over each row of data
for row in csv_reader :
# Append the row of data to the list
data . append ( row )
# Return the list of data
return dataВывод модели впечатляюще эффективен, в настоящее время он поддерживает ввод английского и китайского, вы можете ввести инструкции или префиксы кода по мере необходимости.
Distilgpt2 Автозаполняющий модель с тонким настройкой, вы можете использовать следующий код:
Пример: примеры/distilgpt2_demo.py
import sys
sys . path . append ( '..' )
from codeassist import GPT2Coder
m = GPT2Coder ( "shibing624/code-autocomplete-distilgpt2-python" )
print ( m . generate ( 'import torch.nn as' )[ 0 ])выход:
import torch.nn as nn
import torch.nn.functional as FПример: примеры/use_transformers_gpt2.py
Пример: примеры/training_wizardcoder_mydata.py
cd examples
CUDA_VISIBLE_DEVICES=0,1 python training_wizardcoder_mydata.py --do_train --do_predict --num_epochs 1 --output_dir outputs-wizard --model_name WizardLM/WizardCoder-15B-V1.0Пример: примеры/training_gpt2_mydata.py
cd examples
python training_gpt2_mydata.py --do_train --do_predict --num_epochs 15 --output_dir outputs-gpt2 --model_name gpt2PS: тонкая модель результатов-GPT2-Python: Shibing624/Code-AutocOpplite-GPT2-база, я потратил около 24 часов с V100, чтобы настраивать его.
запустить сервер FASTAPI:
Пример: примеры/server.py
cd examples
python server.pyОткрытый URL: http://0.0.0.0:8001/docs
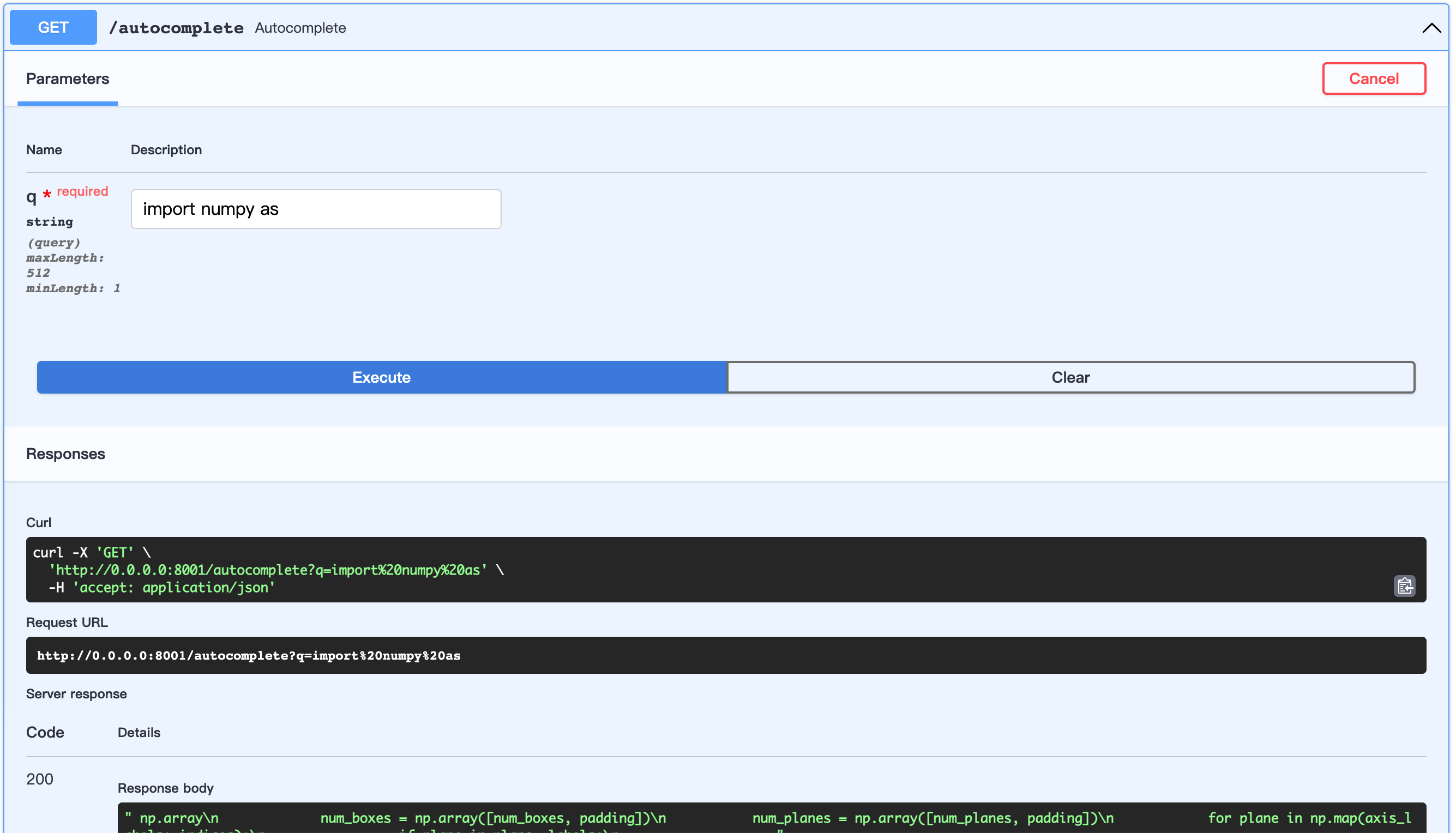
Это позволяет настроить наборы данных.
Давайте использовать коды Python от Awesome-Pytorch-List
Дерево наборов данных:
examples/download/python
├── train.txt
└── valid.txt
└── test.txtЕсть три способа создания набора данных:
from datasets import load_dataset
dataset = load_dataset ( "shibing624/source_code" , "python" ) # python or java or cpp
print ( dataset )
print ( dataset [ 'test' ][ 0 : 10 ])выход:
DatasetDict({
train: Dataset({
features: [ ' text ' ],
num_rows: 5215412
})
validation: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
test: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
})
{ ' text ' : [
" {'max_epochs': [1, 2]},n " ,
' refit=False,n ' , ' cv=3,n ' ,
" scoring='roc_auc',n " , ' )n ' ,
' search.fit(*data)n ' ,
' ' ,
' def test_module_output_not_1d(self, net_cls, data):n ' ,
' from skorch.toy import make_classifiern ' ,
' module = make_classifier(n '
]}| Имя | Источник | Скачать | Размер |
|---|---|---|---|
| Python+Java+CPP исходный код | Awesome-Pytorch-List (5,22 миллиона строк) | github_source_code.zip | 105 м |
Загрузите набор данных и раскрипипируйте его, поместите в examples/ .
PRIPARE_CODE_DATA.PY
cd examples
python prepare_code_data.py --num_repos 260
Если вы используете CodeAssist в своем исследовании, укажите его в следующем формате:
APA:
Xu, M. codeassist: Code AutoComplete with GPT model (Version 1.0.0) [Computer software]. https://github.com/shibing624/codeassistBibtex:
@software{Xu_codeassist,
author = {Ming Xu},
title = {CodeAssist: Code AutoComplete with Generation model},
url = {https://github.com/shibing624/codeassist},
version = {1.0.0}
}Этот репозиторий лицензируется по лицензии Apache 2.0.
Пожалуйста, следуйте Attribution-Noncommercial 4.0 International, чтобы использовать модель WizardCoder.
Код проекта по -прежнему очень грубо.
testspython setup.py test для запуска всех модульных тестов, чтобы убедиться, что все отдельные тесты проходятВы можете отправить свой PR позже.


