CodeAssist
v0.1.0
?? chino |

CodeAssist es una herramienta avanzada de finalización de código que proporciona inteligentemente las finalizaciones de código de alta calidad para Python, Java y C ++, etc.
CodeAssist es una herramienta de finalización de código de alta calidad que completa el código para lenguajes de programación como Python, Java y C ++.
Python , Java , C++ , javascript , etc.| Arco | Base de base | Modelo | Tamaño del modelo |
|---|---|---|---|
| GPT | GPT2 | shibing624/code-eutocomplete-gpt2-base | 487mb |
| GPT | Distilgpt2 | shibing624/code-eutocomplete-distilgpt2-python | 319MB |
| GPT | Bigcode/Starcoder | Wizardlm/WizardCoder-15B-V1.0 | 29GB |
Demo de Huggingface: https://huggingface.co/spaces/shibing624/code-autocomplete
Modelo de back-end: shibing624/code-autocomplete-gpt2-base
pip install torch # conda install pytorch
pip install -U codeassisto
git clone https://github.com/shibing624/codeassist.git
cd CodeAssist
python setup.py install WizardCoder-15b está ajustado bigcode/starcoder con datos de código Alpaca, puede usar el siguiente código para generar código:
Ejemplo: ejemplos/wizardcoder_demo.py
import sys
sys . path . append ( '..' )
from codeassist import WizardCoder
m = WizardCoder ( "WizardLM/WizardCoder-15B-V1.0" )
print ( m . generate ( 'def load_csv_file(file_path):' )[ 0 ])producción:
import csv
def load_csv_file ( file_path ):
"""
Load data from a CSV file and return a list of dictionaries.
"""
# Open the file in read mode
with open ( file_path , 'r' ) as file :
# Create a CSV reader object
csv_reader = csv . DictReader ( file )
# Initialize an empty list to store the data
data = []
# Iterate over each row of data
for row in csv_reader :
# Append the row of data to the list
data . append ( row )
# Return the list of data
return dataLa salida del modelo es impresionantemente efectiva, actualmente admite la entrada en inglés y china, puede ingresar instrucciones o prefijos de código según sea necesario.
DISTILGPT2 Código ajustado Modelo de autocompleto, puede usar el siguiente código:
Ejemplo: Ejemplos/Distilgpt2_Demo.py
import sys
sys . path . append ( '..' )
from codeassist import GPT2Coder
m = GPT2Coder ( "shibing624/code-autocomplete-distilgpt2-python" )
print ( m . generate ( 'import torch.nn as' )[ 0 ])producción:
import torch.nn as nn
import torch.nn.functional as FEjemplo: ejemplos/use_transformers_gpt2.py
Ejemplo: ejemplos/entrenador_wizardcoder_mydata.py
cd examples
CUDA_VISIBLE_DEVICES=0,1 python training_wizardcoder_mydata.py --do_train --do_predict --num_epochs 1 --output_dir outputs-wizard --model_name WizardLM/WizardCoder-15B-V1.0Ejemplo: ejemplos/entrenador_gpt2_mydata.py
cd examples
python training_gpt2_mydata.py --do_train --do_predict --num_epochs 15 --output_dir outputs-gpt2 --model_name gpt2PS: el modelo de resultado ajustado es GPT2-Python: Shibing624/Code-Autocomplete-GPT2-Base, pasé unas 24 horas con V100 para ajustarlo.
Iniciar servidor Fastapi:
Ejemplo: ejemplos/server.py
cd examples
python server.pyURL abierta: http://0.0.0.0:8001/docs
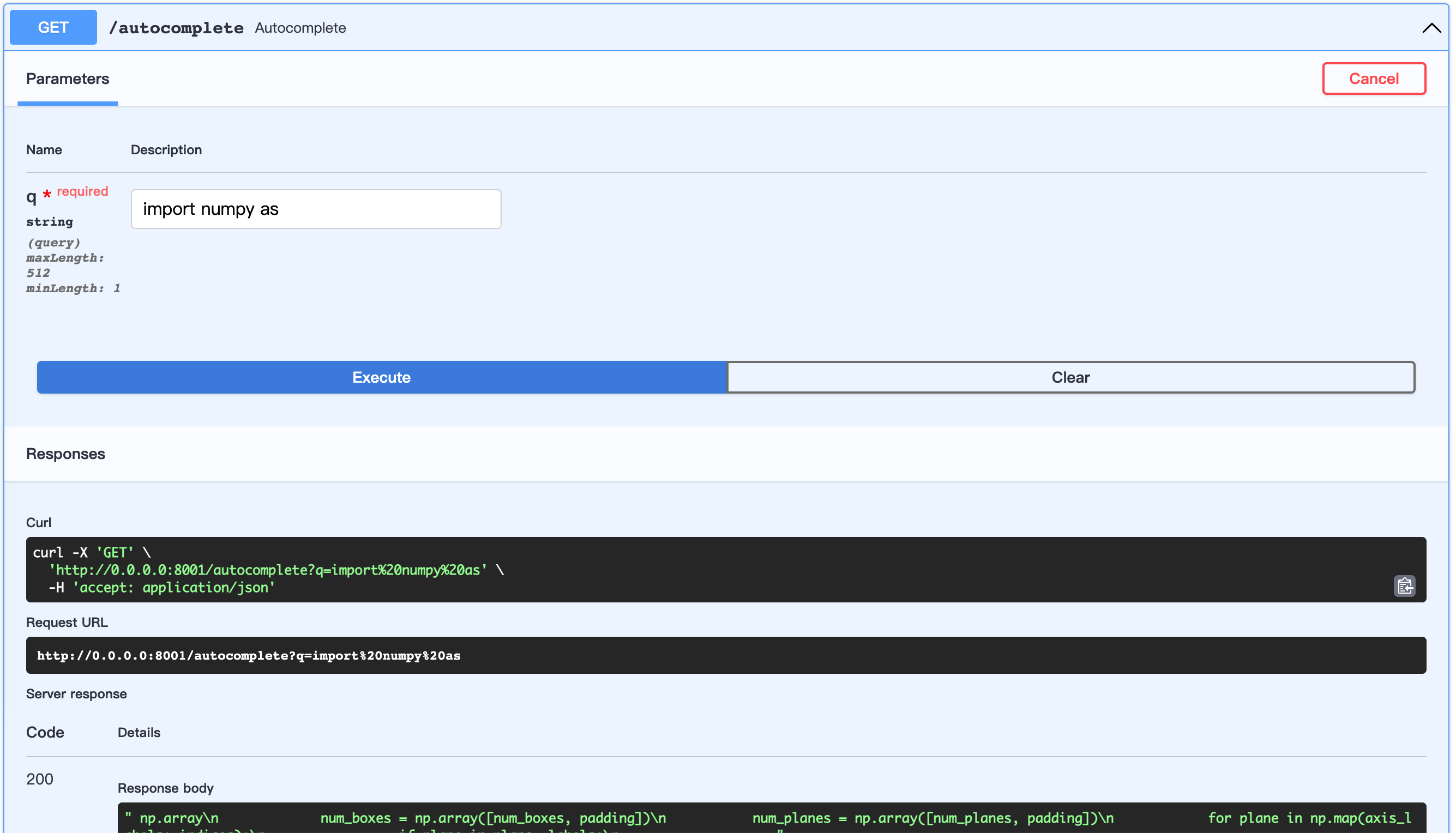
Esto permite personalizar la construcción del conjunto de datos.
Usemos los códigos de Python de Awesome-Pytorch-List
Árbol del conjunto de datos:
examples/download/python
├── train.txt
└── valid.txt
└── test.txtHay tres formas de crear un conjunto de datos:
from datasets import load_dataset
dataset = load_dataset ( "shibing624/source_code" , "python" ) # python or java or cpp
print ( dataset )
print ( dataset [ 'test' ][ 0 : 10 ])producción:
DatasetDict({
train: Dataset({
features: [ ' text ' ],
num_rows: 5215412
})
validation: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
test: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
})
{ ' text ' : [
" {'max_epochs': [1, 2]},n " ,
' refit=False,n ' , ' cv=3,n ' ,
" scoring='roc_auc',n " , ' )n ' ,
' search.fit(*data)n ' ,
' ' ,
' def test_module_output_not_1d(self, net_cls, data):n ' ,
' from skorch.toy import make_classifiern ' ,
' module = make_classifier(n '
]}| Nombre | Fuente | Descargar | Tamaño |
|---|---|---|---|
| Código fuente de Python+Java+CPP | Awesome-Pytorch-List (5.22 millones de líneas) | github_source_code.zip | 105m |
Descargue el conjunto de datos y descúplalo, póngalo a examples/ .
preparar_code_data.py
cd examples
python prepare_code_data.py --num_repos 260
Si usa CodeAssist en su investigación, cite en el siguiente formato:
APA:
Xu, M. codeassist: Code AutoComplete with GPT model (Version 1.0.0) [Computer software]. https://github.com/shibing624/codeassistBibtex:
@software{Xu_codeassist,
author = {Ming Xu},
title = {CodeAssist: Code AutoComplete with Generation model},
url = {https://github.com/shibing624/codeassist},
version = {1.0.0}
}Este repositorio tiene licencia bajo la Licencia Apache 2.0.
Siga la atribución no comercial 4.0 International para usar el modelo WizardCoder.
El código del proyecto sigue siendo muy duro.
testspython setup.py test para ejecutar todas las pruebas unitarias para garantizar que se pasen todas las pruebas individualesPuede enviar su PR más tarde.


