CodeAssist
v0.1.0
Modelos / Modelos / Modelos

O CodeAssist é uma ferramenta avançada de conclusão de código que fornece inteligentemente as conclusões de código de alta qualidade para Python, Java e C ++ e assim por diante.
O CodeAssist é uma ferramenta de conclusão de código de alta qualidade que conclui o código para linguagens de programação, como Python, Java e C ++.
Python , Java , C++ , javascript e assim por diante| Arco | Basemodel | Modelo | Tamanho do modelo |
|---|---|---|---|
| Gpt | GPT2 | Shibing624/Code-Autocomplete-GPT2-BASE | 487 MB |
| Gpt | destilgpt2 | Shibing624/Code-Autocomplete-Distilgpt2-Python | 319 MB |
| Gpt | BigCode/Starcoder | Wizardlm/wizardcoder-15b-v1.0 | 29 GB |
Huggingface Demo: https://huggingface.co/spaces/shibing624/code-autocomplete
Modelo de back-end: shibing624/code-autocomplete-gpt2-base
pip install torch # conda install pytorch
pip install -U codeassistou
git clone https://github.com/shibing624/codeassist.git
cd CodeAssist
python setup.py install WizardCoder-15b é bigcode/starcoder de ajuste fino com dados de código ALPACA, você pode usar o seguinte código para gerar código:
Exemplo: exemplos/wizardcoder_demo.py
import sys
sys . path . append ( '..' )
from codeassist import WizardCoder
m = WizardCoder ( "WizardLM/WizardCoder-15B-V1.0" )
print ( m . generate ( 'def load_csv_file(file_path):' )[ 0 ])saída:
import csv
def load_csv_file ( file_path ):
"""
Load data from a CSV file and return a list of dictionaries.
"""
# Open the file in read mode
with open ( file_path , 'r' ) as file :
# Create a CSV reader object
csv_reader = csv . DictReader ( file )
# Initialize an empty list to store the data
data = []
# Iterate over each row of data
for row in csv_reader :
# Append the row of data to the list
data . append ( row )
# Return the list of data
return dataA saída do modelo é impressionantemente eficaz, atualmente suporta informações em inglês e chinês, você pode inserir instruções ou prefixos de código, conforme necessário.
Modelo de código autocompleto DistilGPT2 Tuned AutoComplete, você pode usar o seguinte código:
Exemplo: Exemplos/DISTILGPT2_DEMO.PY
import sys
sys . path . append ( '..' )
from codeassist import GPT2Coder
m = GPT2Coder ( "shibing624/code-autocomplete-distilgpt2-python" )
print ( m . generate ( 'import torch.nn as' )[ 0 ])saída:
import torch.nn as nn
import torch.nn.functional as FExemplo: exemplos/use_transformers_gpt2.py
Exemplo: Exemplos/Training_wizardcoder_mydata.py
cd examples
CUDA_VISIBLE_DEVICES=0,1 python training_wizardcoder_mydata.py --do_train --do_predict --num_epochs 1 --output_dir outputs-wizard --model_name WizardLM/WizardCoder-15B-V1.0Exemplo: Exemplos/Training_GPT2_Mydata.py
cd examples
python training_gpt2_mydata.py --do_train --do_predict --num_epochs 15 --output_dir outputs-gpt2 --model_name gpt2PS: O modelo de resultado ajustado é GPT2-Python: Shibing624/Code-Autocomplete-GPT2-BASE, passei cerca de 24 horas com o V100 para ajustá-lo.
Inicie o servidor FASTAPI:
Exemplo: exemplos/server.py
cd examples
python server.pyURL aberto: http://0.0.0.0:8001/docs
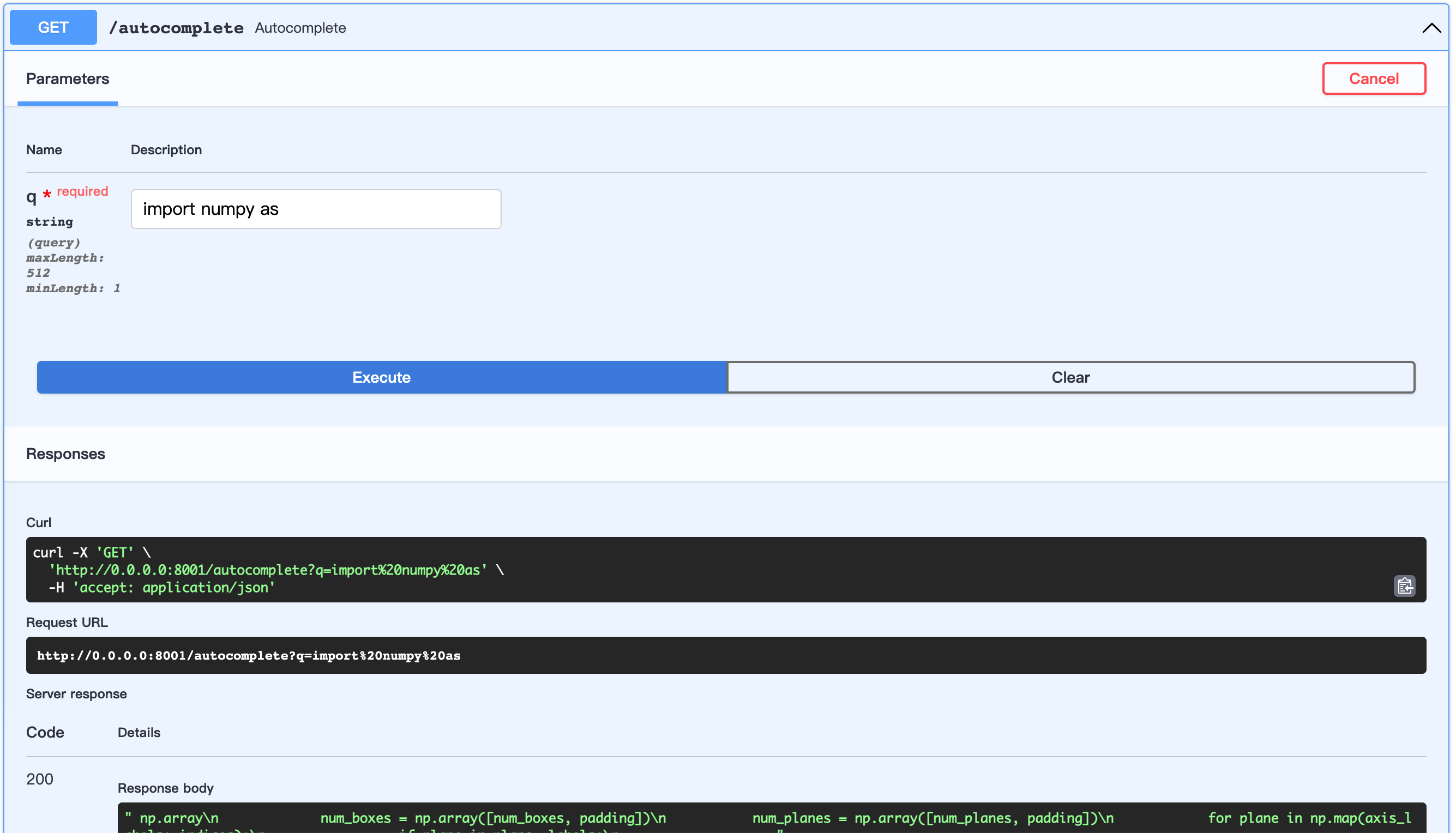
Isso permite personalizar a construção do conjunto de dados.
Vamos usar os códigos python da Awesome-Pytorch-List
Árvore do conjunto de dados:
examples/download/python
├── train.txt
└── valid.txt
└── test.txtExistem três maneiras de criar o conjunto de dados:
from datasets import load_dataset
dataset = load_dataset ( "shibing624/source_code" , "python" ) # python or java or cpp
print ( dataset )
print ( dataset [ 'test' ][ 0 : 10 ])saída:
DatasetDict({
train: Dataset({
features: [ ' text ' ],
num_rows: 5215412
})
validation: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
test: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
})
{ ' text ' : [
" {'max_epochs': [1, 2]},n " ,
' refit=False,n ' , ' cv=3,n ' ,
" scoring='roc_auc',n " , ' )n ' ,
' search.fit(*data)n ' ,
' ' ,
' def test_module_output_not_1d(self, net_cls, data):n ' ,
' from skorch.toy import make_classifiern ' ,
' module = make_classifier(n '
]}| Nome | Fonte | Download | Tamanho |
|---|---|---|---|
| Python+Java+Código Fonte de CPP | Awesome-Pytorch-List (5,22 milhões de linhas) | github_source_code.zip | 105m |
Faça o download do conjunto de dados e descompacte -o, coloque para examples/ .
prepare_code_data.py
cd examples
python prepare_code_data.py --num_repos 260
Se você usar o CodeAssist em sua pesquisa, cite -a no seguinte formato:
APA:
Xu, M. codeassist: Code AutoComplete with GPT model (Version 1.0.0) [Computer software]. https://github.com/shibing624/codeassistBibtex:
@software{Xu_codeassist,
author = {Ming Xu},
title = {CodeAssist: Code AutoComplete with Generation model},
url = {https://github.com/shibing624/codeassist},
version = {1.0.0}
}Este repositório está licenciado sob a licença Apache 2.0.
Siga o International Attribution-NonCommercial 4.0 para usar o modelo WizardCoder.
O código do projeto ainda é muito difícil.
testspython setup.py test para executar todos os testes de unidade para garantir que todos os testes únicos sejam passadosVocê pode enviar seu PR mais tarde.


