CodeAssist
v0.1.0
Chinesisch |

Codeassist ist ein erweitertes Code-Completion-Tool, das intelligent qualitativ hochwertige Code-Abschlüsse für Python, Java und C ++ usw. bietet.
Codeassist ist ein qualitativ hochwertiges Code-Completion-Tool, das den Code für Programmiersprachen wie Python, Java und C ++ vervollständigt.
Python , Java , C++ , javascript usw.| Bogen | Basemodel | Modell | Modellgröße |
|---|---|---|---|
| Gpt | gpt2 | Shibing624/Code-Autokometer-GPT2-Base | 487MB |
| Gpt | DISTILGPT2 | Shibing624/Code-Autokometer-Distilgpt2-Python | 319MB |
| Gpt | BigCode/StarCoder | WizardLM/WizardCoder-15b-V1.0 | 29 GB |
Huggingface Demo: https://huggingface.co/spaces/Shibing624/Code-autocomplete
Backend-Modell: shibing624/code-autocomplete-gpt2-base
pip install torch # conda install pytorch
pip install -U codeassistoder
git clone https://github.com/shibing624/codeassist.git
cd CodeAssist
python setup.py install WizardCoder-15b ist fein abgestimmter bigcode/starcoder mit Alpaca-Codedaten. Sie können den folgenden Code verwenden, um Code zu generieren:
Beispiel: Beispiele/WizardCoder_demo.py
import sys
sys . path . append ( '..' )
from codeassist import WizardCoder
m = WizardCoder ( "WizardLM/WizardCoder-15B-V1.0" )
print ( m . generate ( 'def load_csv_file(file_path):' )[ 0 ])Ausgabe:
import csv
def load_csv_file ( file_path ):
"""
Load data from a CSV file and return a list of dictionaries.
"""
# Open the file in read mode
with open ( file_path , 'r' ) as file :
# Create a CSV reader object
csv_reader = csv . DictReader ( file )
# Initialize an empty list to store the data
data = []
# Iterate over each row of data
for row in csv_reader :
# Append the row of data to the list
data . append ( row )
# Return the list of data
return dataDie Modellausgabe ist beeindruckend effektiv. Derzeit unterstützt sie englische und chinesische Eingaben. Sie können Anweisungen oder Codepräfixe bei Bedarf eingeben.
DISTILGPT2 FIND-TUND-CODE Autokaponete Modell, Sie können den folgenden Code verwenden:
Beispiel: Beispiele/distilgpt2_demo.py
import sys
sys . path . append ( '..' )
from codeassist import GPT2Coder
m = GPT2Coder ( "shibing624/code-autocomplete-distilgpt2-python" )
print ( m . generate ( 'import torch.nn as' )[ 0 ])Ausgabe:
import torch.nn as nn
import torch.nn.functional as FBeispiel: Beispiele/USE_TRANSFORMERS_GPT2.PY
Beispiel: Beispiele/Training_wizardcoder_mydata.py
cd examples
CUDA_VISIBLE_DEVICES=0,1 python training_wizardcoder_mydata.py --do_train --do_predict --num_epochs 1 --output_dir outputs-wizard --model_name WizardLM/WizardCoder-15B-V1.0Beispiel: Beispiele/Training_GPT2_MYDATA.PY
cd examples
python training_gpt2_mydata.py --do_train --do_predict --num_epochs 15 --output_dir outputs-gpt2 --model_name gpt2PS: Das feinstimmige Ergebnismodell ist GPT2-Python: Shibing624/Code-Autokompleter-GPT2-Base, ich habe ungefähr 24 Stunden mit V100 verbracht, um es zu optimieren.
Fastapi Server starten:
Beispiel: Beispiele/Server.py
cd examples
python server.pyÖffnen Sie die URL: http://0.0.0.0:8001/docs
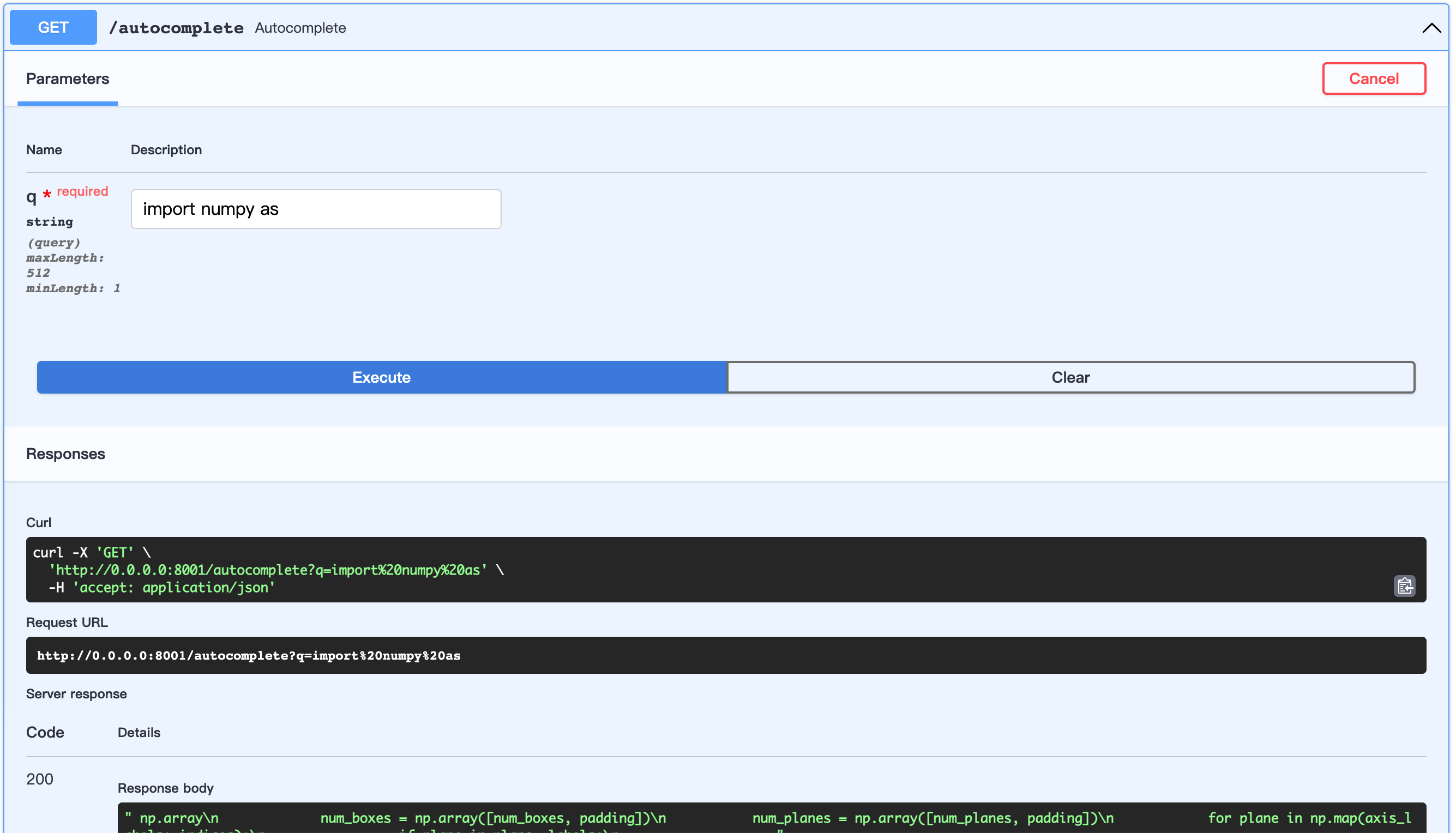
Dies ermöglicht das Anpassen des Datensatzes.
Verwenden wir Python-Codes von Awesome-Pytorch-List
Datensatzbaum:
examples/download/python
├── train.txt
└── valid.txt
└── test.txtEs gibt drei Möglichkeiten, den Datensatz zu erstellen:
from datasets import load_dataset
dataset = load_dataset ( "shibing624/source_code" , "python" ) # python or java or cpp
print ( dataset )
print ( dataset [ 'test' ][ 0 : 10 ])Ausgabe:
DatasetDict({
train: Dataset({
features: [ ' text ' ],
num_rows: 5215412
})
validation: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
test: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
})
{ ' text ' : [
" {'max_epochs': [1, 2]},n " ,
' refit=False,n ' , ' cv=3,n ' ,
" scoring='roc_auc',n " , ' )n ' ,
' search.fit(*data)n ' ,
' ' ,
' def test_module_output_not_1d(self, net_cls, data):n ' ,
' from skorch.toy import make_classifiern ' ,
' module = make_classifier(n '
]}| Name | Quelle | Herunterladen | Größe |
|---|---|---|---|
| Python+Java+CPP -Quellcode | Awesome-Pytorch-Liste (5,22 Millionen Linien) | github_source_code.zip | 105 m |
Laden Sie den Datensatz herunter und entpacken Sie es, geben Sie es an examples/ .
prepe_code_data.py
cd examples
python prepare_code_data.py --num_repos 260
Wenn Sie Codeassist in Ihrer Forschung verwenden, zitieren Sie diese bitte im folgenden Format:
APA:
Xu, M. codeassist: Code AutoComplete with GPT model (Version 1.0.0) [Computer software]. https://github.com/shibing624/codeassistBibtex:
@software{Xu_codeassist,
author = {Ming Xu},
title = {CodeAssist: Code AutoComplete with Generation model},
url = {https://github.com/shibing624/codeassist},
version = {1.0.0}
}Dieses Repository ist unter der Apache -Lizenz 2.0 lizenziert.
Bitte folgen Sie dem Attribution-Noncommercial 4.0 International, um das Assistentcoder-Modell zu verwenden.
Der Projektcode ist immer noch sehr rau.
testspython setup.py test um alle Unit -Tests auszuführen, um sicherzustellen, dass alle einzelnen Tests bestanden werdenSie können Ihre PR später einreichen.


