CodeAssist
v0.1.0
??Chinese | English | Documents/Docs | ?Models/Models

CodeAssist is an advanced code completion tool that intelligently provides high-quality code completions for Python, Java, and C++ and so on.
CodeAssist is a high-quality code completion tool that completes code for programming languages such as Python, Java, and C++.
Python , Java , C++ , javascript and so on| Arch | BaseModel | Model | Model Size |
|---|---|---|---|
| GPT | gpt2 | shibing624/code-autocomplete-gpt2-base | 487MB |
| GPT | distilgpt2 | shibing624/code-autocomplete-distilgpt2-python | 319MB |
| GPT | bigcode/starcoder | WizardLM/WizardCoder-15B-V1.0 | 29GB |
HuggingFace Demo: https://huggingface.co/spaces/shibing624/code-autocomplete
backend model: shibing624/code-autocomplete-gpt2-base
pip install torch # conda install pytorch
pip install -U codeassistor
git clone https://github.com/shibing624/codeassist.git
cd CodeAssist
python setup.py install WizardCoder-15b is fine-tuned bigcode/starcoder with alpaca code data, you can use the following code to generate code:
example: examples/wizardcoder_demo.py
import sys
sys . path . append ( '..' )
from codeassist import WizardCoder
m = WizardCoder ( "WizardLM/WizardCoder-15B-V1.0" )
print ( m . generate ( 'def load_csv_file(file_path):' )[ 0 ])output:
import csv
def load_csv_file ( file_path ):
"""
Load data from a CSV file and return a list of dictionaries.
"""
# Open the file in read mode
with open ( file_path , 'r' ) as file :
# Create a CSV reader object
csv_reader = csv . DictReader ( file )
# Initialize an empty list to store the data
data = []
# Iterate over each row of data
for row in csv_reader :
# Append the row of data to the list
data . append ( row )
# Return the list of data
return datamodel output is impressively effective, it currently supports English and Chinese input, you can enter instructions or code prefixes as required.
distilgpt2 fine-tuned code autocomplete model, you can use the following code:
example: examples/distilgpt2_demo.py
import sys
sys . path . append ( '..' )
from codeassist import GPT2Coder
m = GPT2Coder ( "shibing624/code-autocomplete-distilgpt2-python" )
print ( m . generate ( 'import torch.nn as' )[ 0 ])output:
import torch.nn as nn
import torch.nn.functional as Fexample: examples/use_transformers_gpt2.py
example: examples/training_wizardcoder_mydata.py
cd examples
CUDA_VISIBLE_DEVICES=0,1 python training_wizardcoder_mydata.py --do_train --do_predict --num_epochs 1 --output_dir outputs-wizard --model_name WizardLM/WizardCoder-15B-V1.0example: examples/training_gpt2_mydata.py
cd examples
python training_gpt2_mydata.py --do_train --do_predict --num_epochs 15 --output_dir outputs-gpt2 --model_name gpt2PS: fine-tuned result model is GPT2-python: shibing624/code-autocomplete-gpt2-base, I spent about 24 hours with V100 to fine-tune it.
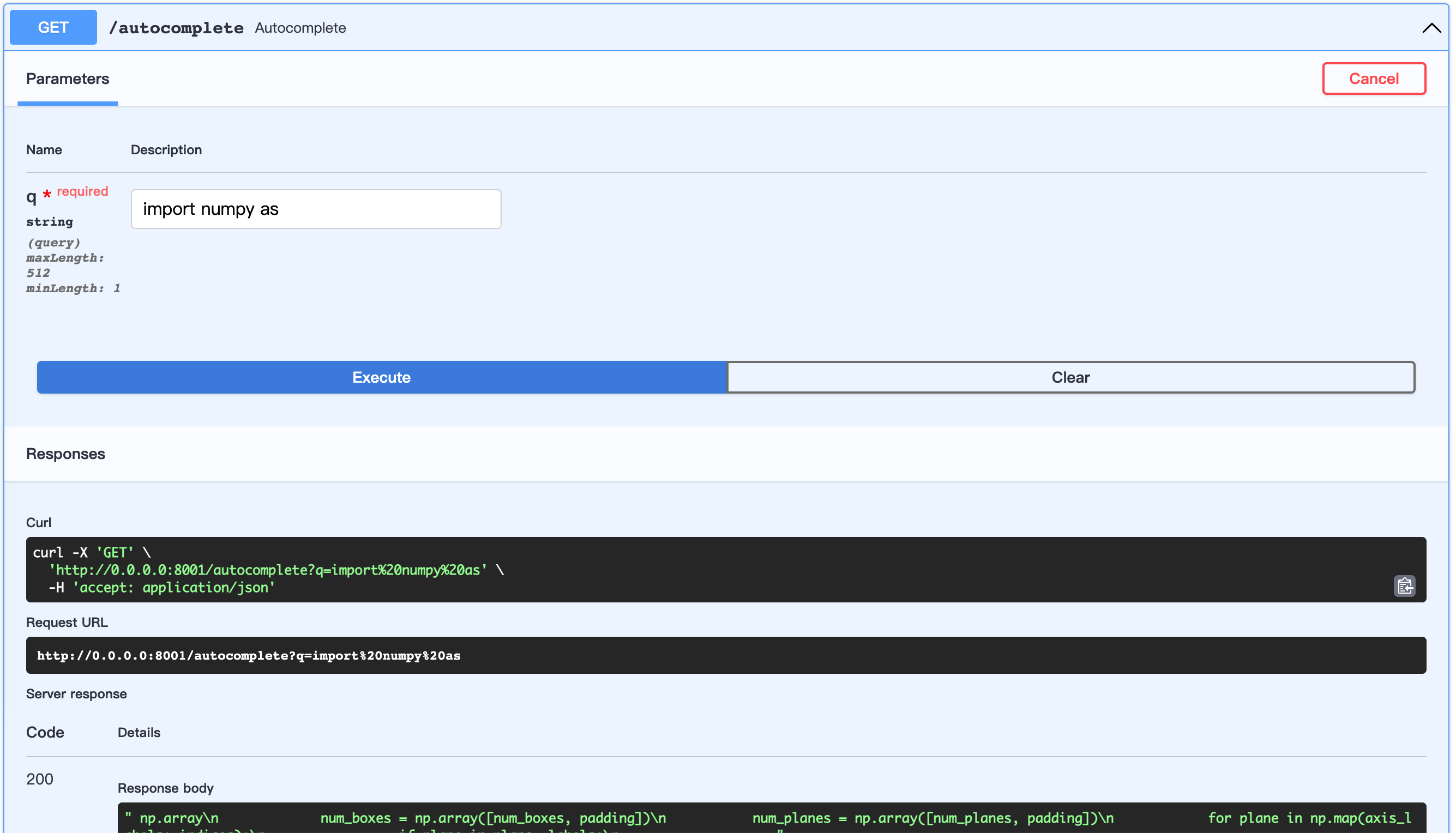
start FastAPI server:
example: examples/server.py
cd examples
python server.pyopen url: http://0.0.0.0:8001/docs
This allows to customize dataset building. Below is an example of the building process.
Let's use Python codes from Awesome-pytorch-list
dataset tree:
examples/download/python
├── train.txt
└── valid.txt
└── test.txtThere are three ways to build dataset:
from datasets import load_dataset
dataset = load_dataset ( "shibing624/source_code" , "python" ) # python or java or cpp
print ( dataset )
print ( dataset [ 'test' ][ 0 : 10 ])output:
DatasetDict({
train: Dataset({
features: [ ' text ' ],
num_rows: 5215412
})
validation: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
test: Dataset({
features: [ ' text ' ],
num_rows: 10000
})
})
{ ' text ' : [
" {'max_epochs': [1, 2]},n " ,
' refit=False,n ' , ' cv=3,n ' ,
" scoring='roc_auc',n " , ' )n ' ,
' search.fit(*data)n ' ,
' ' ,
' def test_module_output_not_1d(self, net_cls, data):n ' ,
' from skorch.toy import make_classifiern ' ,
' module = make_classifier(n '
]}| Name | Source | Download | Size |
|---|---|---|---|
| Python+Java+CPP source code | Awesome-pytorch-list(5.22 Million lines) | github_source_code.zip | 105M |
download dataset and unzip it, put to examples/ .
prepare_code_data.py
cd examples
python prepare_code_data.py --num_repos 260
If you use codeassist in your research, please quote it in the following format:
APA:
Xu, M. codeassist: Code AutoComplete with GPT model (Version 1.0.0) [Computer software]. https://github.com/shibing624/codeassistBibTeX:
@software{Xu_codeassist,
author = {Ming Xu},
title = {CodeAssist: Code AutoComplete with Generation model},
url = {https://github.com/shibing624/codeassist},
version = {1.0.0}
}This repository is licensed under the Apache License 2.0.
Please follow the Attribution-NonCommercial 4.0 International to use the WizardCoder model.
The project code is still very rough. If you have improved the code, you are welcome to submit it back to this project. Before submitting, pay attention to the following two points:
testspython setup.py test to run all unit tests to ensure that all single tests are passedYou can submit your PR later.


