interpretable embeddings
1.0.0
Criação de incorporações interpretáveis fazendo perguntas ao LLMS, código para o artigo de QA-EMB.
O QA-EMBS cria uma incorporação interpretável fazendo uma série de perguntas sim-não a um LLM autoregressivo pré-treinado. 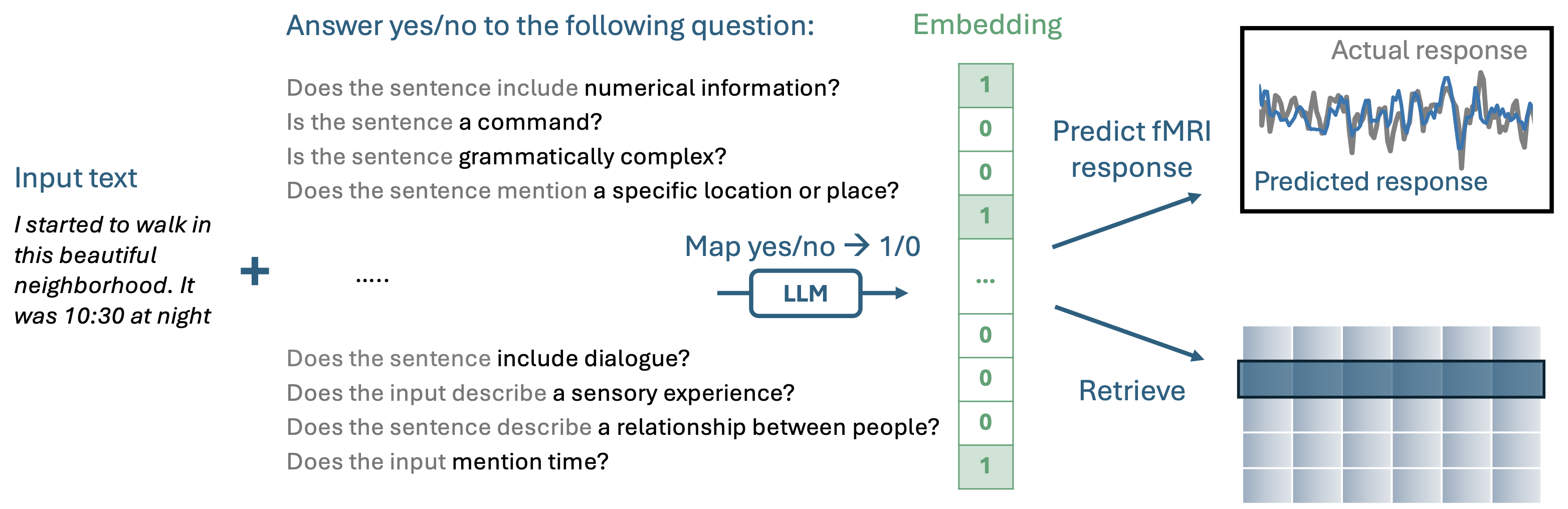
Se você deseja apenas usar o QA-EMB em seu próprio aplicativo, a maneira mais fácil é através do pacote Imodelsx. Para instalar, basta executar pip install imodelsx .
Em seguida, você pode gerar suas próprias incorporações interpretáveis, apresentando perguntas para o seu domínio:
from imodelsx import QAEmb
import pandas as pd
questions = [
'Is the input related to food preparation?' ,
'Does the input mention laughter?' ,
'Is there an expression of surprise?' ,
'Is there a depiction of a routine or habit?' ,
'Does the sentence contain stuttering?' ,
'Does the input contain a first-person pronoun?' ,
]
examples = [
'i sliced some cucumbers and then moved on to what was next' ,
'the kids were giggling about the silly things they did' ,
'and i was like whoa that was unexpected' ,
'walked down the path like i always did' ,
'um no um then it was all clear' ,
'i was walking to school and then i saw a cat' ,
]
checkpoint = 'meta-llama/Meta-Llama-3-8B-Instruct'
embedder = QAEmb (
questions = questions , checkpoint = checkpoint , use_cache = False )
embeddings = embedder ( examples )
df = pd . DataFrame ( embeddings . astype ( int ), columns = [
q . split ()[ - 1 ] for q in questions ])
df . index = examples
df . columns . name = 'Question (abbreviated)'
display ( df . style . background_gradient ( axis = None ))
- - - - - - - - DISPLAYS ANSWER FOR EACH QUESTION IN EMBEDDING - - - - - - - -Instruções para instalar os conjuntos de dados necessários para reproduzir os experimentos de fMRI no papel.
python experiments/00_load_dataset.pydata Dir sob onde você o executar e usará o DATALAD para baixar os dados pré -processados, bem como os espaços de recursos necessários para ajustar modelos de codificação semânticaneuro1.config.root_dir para onde você deseja armazenar os dados{root_dir}/ds003020/derivative/pycortex-db/em_data daqui e mover seu conteúdo para {root_dir}/em_dataneuro1.data.response_utils Função load_response{root_dir}/ds003020/derivative/preprocessed_data/{subject} , eles são armazenados em um arquivo H5 para cada história, por exemplo, wheretheressmoke.h5neuro1.features.stim_utils função load_story_wordseqs{root_dir}/ds003020/derivative/TextGrids", where each story has a TextGrid file, eg wheretheressmoke.textGrid`{root_dir}/ds003020/derivative/respdict.json para obter a duração de cada históriaInstruções para instalar o código aqui como um pacote para o desenvolvimento completo.
pip install -e . Para instalar localmente o pacote neuro1python 01_fit_encoding.py --subject UTS03 --feature eng1000 @ misc { benara2024crafting ,
title = { Crafting Interpretable Embeddings by Asking LLMs Questions },
author = { Vinamra Benara and Chandan Singh and John X. Morris and Richard Antonello and Ion Stoica and Alexander G. Huth and Jianfeng Gao },
year = { 2024 },
eprint = { 2405.16714 },
archivePrefix = { arXiv },
primaryClass = { cs.CL }
}

