interpretable embeddings
1.0.0
LLMS 질문, QA-EMB 용지에 대한 코드를 요청하여 해석 가능한 임베드 제작.
QA-EMBS는 미리 훈련 된 자동 회귀 LLM에 일련의 예-아니오 질문을함으로써 해석 가능한 임베딩을 구축합니다. 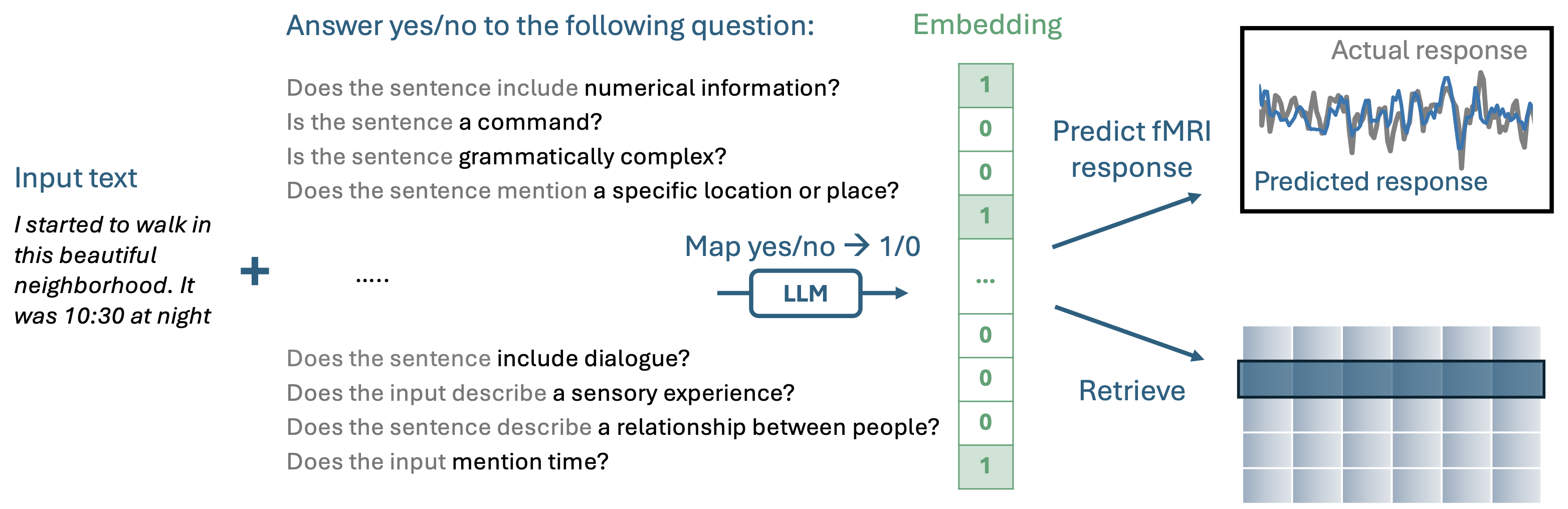
자신의 응용 프로그램에서 QA-EMB를 사용하려면 가장 쉬운 방법은 Imodelsx 패키지를 사용하는 것입니다. 설치하려면 pip install imodelsx 실행하십시오.
그런 다음 도메인에 대한 질문을 제기하여 해석 가능한 임베딩을 생성 할 수 있습니다.
from imodelsx import QAEmb
import pandas as pd
questions = [
'Is the input related to food preparation?' ,
'Does the input mention laughter?' ,
'Is there an expression of surprise?' ,
'Is there a depiction of a routine or habit?' ,
'Does the sentence contain stuttering?' ,
'Does the input contain a first-person pronoun?' ,
]
examples = [
'i sliced some cucumbers and then moved on to what was next' ,
'the kids were giggling about the silly things they did' ,
'and i was like whoa that was unexpected' ,
'walked down the path like i always did' ,
'um no um then it was all clear' ,
'i was walking to school and then i saw a cat' ,
]
checkpoint = 'meta-llama/Meta-Llama-3-8B-Instruct'
embedder = QAEmb (
questions = questions , checkpoint = checkpoint , use_cache = False )
embeddings = embedder ( examples )
df = pd . DataFrame ( embeddings . astype ( int ), columns = [
q . split ()[ - 1 ] for q in questions ])
df . index = examples
df . columns . name = 'Question (abbreviated)'
display ( df . style . background_gradient ( axis = None ))
- - - - - - - - DISPLAYS ANSWER FOR EACH QUESTION IN EMBEDDING - - - - - - - -논문에서 FMRI 실험을 재현하는 데 필요한 데이터 세트 설치 지침.
python experiments/00_load_dataset.py 로 데이터를 다운로드하십시오data 생성하고 Datalad를 사용하여 전처리 데이터를 다운로드하고 시맨틱 인코딩 모델을 맞추는 데 필요한 기능 공간을 다운로드합니다.neuro1.config.root_dir 데이터를 저장할 위치로 설정하십시오.{root_dir}/ds003020/derivative/pycortex-db/ 로 설정해야합니다.em_data 디렉토리를 잡고 내용을 {root_dir}/em_data 로 이동해야합니다.neuro1.data.response_utils 함수 load_response{root_dir}/ds003020/derivative/preprocessed_data/{subject} 에서 응답을로드합니다. 각 스토리 wheretheressmoke.h5 대해 H5 파일에 저장됩니다.neuro1.features.stim_utils 함수 load_story_wordseqs{root_dir}/ds003020/derivative/TextGrids", where each story has a TextGrid file, eg{root_dir}/ds003020/derivative/respdict.json 사용하여 각 스토리의 길이를 얻습니다전체 개발을위한 패키지로 여기에 코드를 설치하기위한 지침.
pip install -e . neuro1 패키지를 로컬로 설치합니다python 01_fit_encoding.py --subject UTS03 --feature eng1000 @ misc { benara2024crafting ,
title = { Crafting Interpretable Embeddings by Asking LLMs Questions },
author = { Vinamra Benara and Chandan Singh and John X. Morris and Richard Antonello and Ion Stoica and Alexander G. Huth and Jianfeng Gao },
year = { 2024 },
eprint = { 2405.16714 },
archivePrefix = { arXiv },
primaryClass = { cs.CL }
}

