interpretable embeddings
1.0.0
صياغة التضمينات القابلة للتفسير من خلال طرح أسئلة LLMS ، رمز لورقة QA-EMB.
تقوم QA-EMBS ببناء تضمينات قابلة للتفسير من خلال طرح سلسلة من الأسئلة على YES-NO إلى LLM التلقائي الذي تم تدريبه مسبقًا. 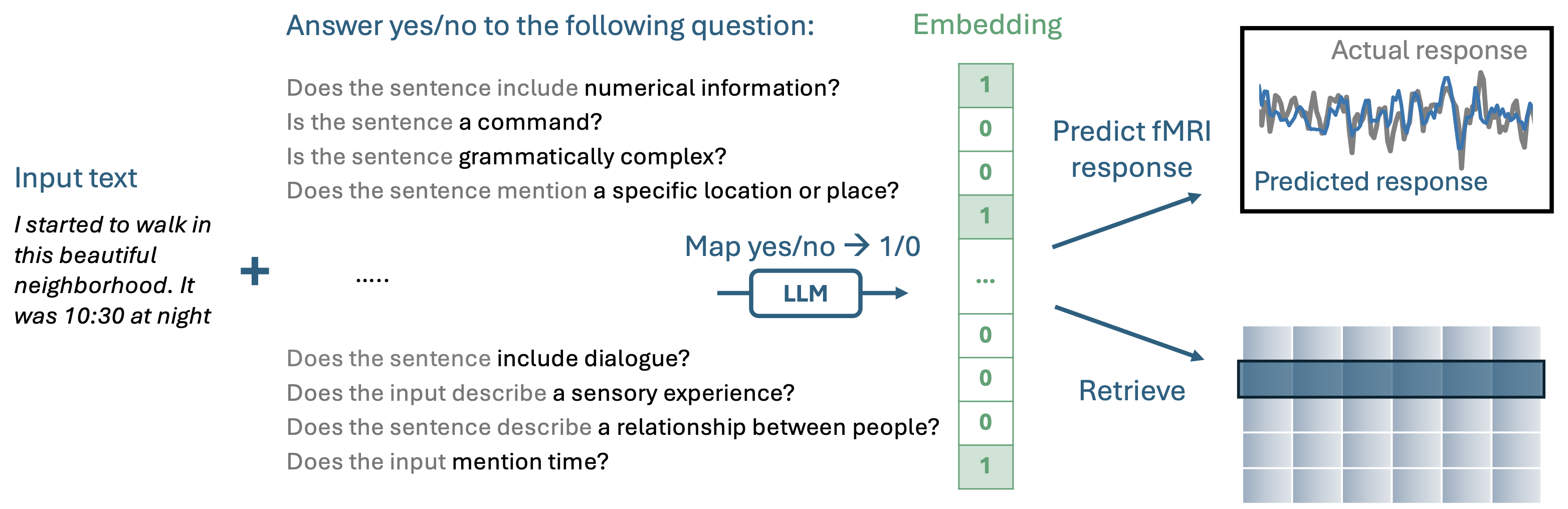
إذا كنت ترغب فقط في استخدام QA-EMB في تطبيقك الخاص ، فإن أسهل طريقة هي من خلال حزمة Imodelsx. للتثبيت ، ما عليك سوى تشغيل pip install imodelsx .
بعد ذلك ، يمكنك إنشاء تضميناتك القابلة للتفسير عن طريق طرح أسئلة لمجالك:
from imodelsx import QAEmb
import pandas as pd
questions = [
'Is the input related to food preparation?' ,
'Does the input mention laughter?' ,
'Is there an expression of surprise?' ,
'Is there a depiction of a routine or habit?' ,
'Does the sentence contain stuttering?' ,
'Does the input contain a first-person pronoun?' ,
]
examples = [
'i sliced some cucumbers and then moved on to what was next' ,
'the kids were giggling about the silly things they did' ,
'and i was like whoa that was unexpected' ,
'walked down the path like i always did' ,
'um no um then it was all clear' ,
'i was walking to school and then i saw a cat' ,
]
checkpoint = 'meta-llama/Meta-Llama-3-8B-Instruct'
embedder = QAEmb (
questions = questions , checkpoint = checkpoint , use_cache = False )
embeddings = embedder ( examples )
df = pd . DataFrame ( embeddings . astype ( int ), columns = [
q . split ()[ - 1 ] for q in questions ])
df . index = examples
df . columns . name = 'Question (abbreviated)'
display ( df . style . background_gradient ( axis = None ))
- - - - - - - - DISPLAYS ANSWER FOR EACH QUESTION IN EMBEDDING - - - - - - - -اتجاهات تثبيت مجموعات البيانات المطلوبة لاستنساخ تجارب الرنين المغناطيسي الوظيفي في الورقة.
python experiments/00_load_dataset.pydata div dire تحت أي مكان تقوم فيه بتشغيله وسوف تستخدم datalad لتنزيل البيانات المعالجة مسبقًا بالإضافة إلى مساحات الميزات اللازمة لتركيب نماذج الترميز الدلاليneuro1.config.root_dir إلى حيث تريد تخزين البيانات{root_dir}/ds003020/derivative/pycortex-db/em_data من هنا ونقل محتوياته إلى {root_dir}/em_dataneuro1.data.response_utils وظيفة load_response{root_dir}/ds003020/derivative/preprocessed_data/{subject} ، hwere يتم تخزينها في ملف H5 لكل قصة ، على سبيل المثال wheretheressmoke.h5neuro1.features.stim_utils وظيفة load_story_wordseqs{root_dir}/ds003020/derivative/TextGrids", where each story has a TextGrid file, eg{root_dir}/ds003020/derivative/respdict.json للحصول على طول كل قصةاتجاهات لتثبيت الكود هنا كحزمة للتطوير الكامل.
pip install -e . لتثبيت حزمة neuro1 محليًاpython 01_fit_encoding.py --subject UTS03 --feature eng1000 @ misc { benara2024crafting ,
title = { Crafting Interpretable Embeddings by Asking LLMs Questions },
author = { Vinamra Benara and Chandan Singh and John X. Morris and Richard Antonello and Ion Stoica and Alexander G. Huth and Jianfeng Gao },
year = { 2024 },
eprint = { 2405.16714 },
archivePrefix = { arXiv },
primaryClass = { cs.CL }
}

