interpretable embeddings
1.0.0
Crafting Interpretable Embeddings by Asking LLMs Questions, code for the QA-Emb paper.
QA-Embs builds an interpretable embeddings by asking a series of yes-no questions to a pre-trained autoregressive LLM.
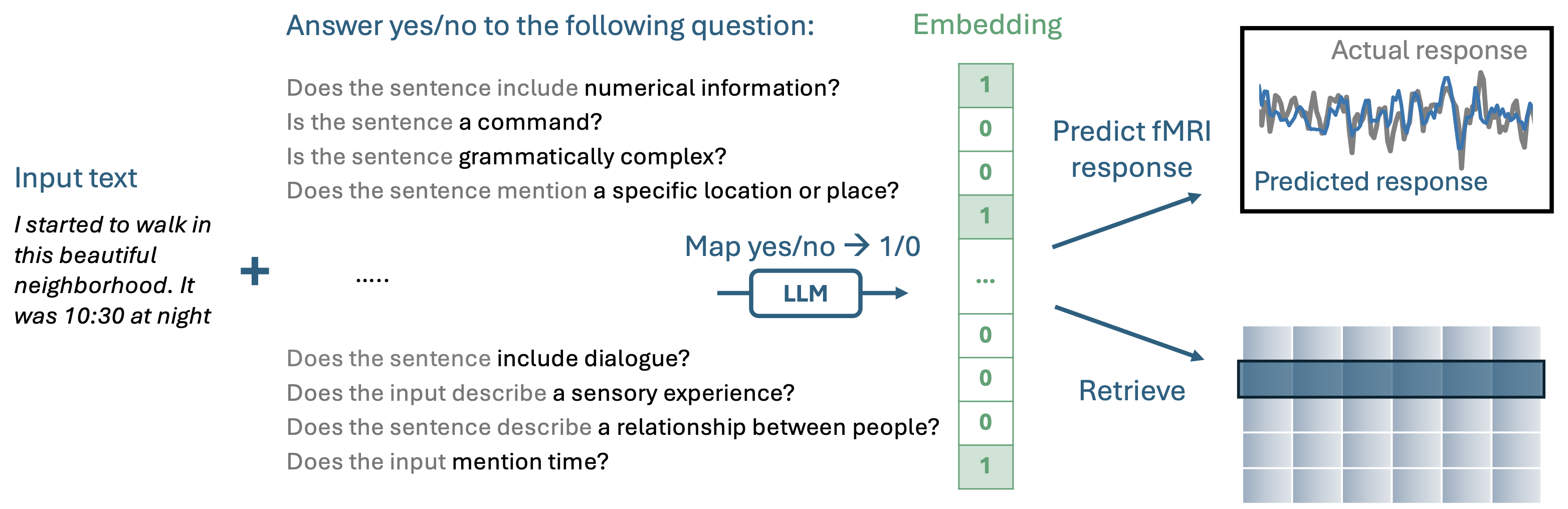
If you just want to use QA-Emb in your own application, the easiest way is through the imodelsX package. To install, just run pip install imodelsx.
Then, you can generate your own interpretable embeddings by coming up with questions for your domain:
from imodelsx import QAEmb
import pandas as pd
questions = [
'Is the input related to food preparation?',
'Does the input mention laughter?',
'Is there an expression of surprise?',
'Is there a depiction of a routine or habit?',
'Does the sentence contain stuttering?',
'Does the input contain a first-person pronoun?',
]
examples = [
'i sliced some cucumbers and then moved on to what was next',
'the kids were giggling about the silly things they did',
'and i was like whoa that was unexpected',
'walked down the path like i always did',
'um no um then it was all clear',
'i was walking to school and then i saw a cat',
]
checkpoint = 'meta-llama/Meta-Llama-3-8B-Instruct'
embedder = QAEmb(
questions=questions, checkpoint=checkpoint, use_cache=False)
embeddings = embedder(examples)
df = pd.DataFrame(embeddings.astype(int), columns=[
q.split()[-1] for q in questions])
df.index = examples
df.columns.name = 'Question (abbreviated)'
display(df.style.background_gradient(axis=None))
--------DISPLAYS ANSWER FOR EACH QUESTION IN EMBEDDING--------Directions for installing the datasets required for reproducing the fMRI experiments in the paper.
python experiments/00_load_dataset.py
data dir under wherever you run it and will use datalad to download the preprocessed data as well as feature spaces needed for fitting semantic encoding modelsneuro1.config.root_dir to where you want to store the data{root_dir}/ds003020/derivative/pycortex-db/em_data directory from here and move its contents to {root_dir}/em_dataneuro1.data.response_utils function load_response{root_dir}/ds003020/derivative/preprocessed_data/{subject}, hwere they are stored in an h5 file for each story, e.g. wheretheressmoke.h5neuro1.features.stim_utils function load_story_wordseqs{root_dir}/ds003020/derivative/TextGrids", where each story has a TextGrid file, e.g. wheretheressmoke.TextGrid`{root_dir}/ds003020/derivative/respdict.json to get the length of each storyDirections for installing the code here as a package for full development.
pip install -e . to locally install the neuro1 packagepython 01_fit_encoding.py --subject UTS03 --feature eng1000
@misc{benara2024crafting,
title={Crafting Interpretable Embeddings by Asking LLMs Questions},
author={Vinamra Benara and Chandan Singh and John X. Morris and Richard Antonello and Ion Stoica and Alexander G. Huth and Jianfeng Gao},
year={2024},
eprint={2405.16714},
archivePrefix={arXiv},
primaryClass={cs.CL}
}

