interpretable embeddings
1.0.0
Création d'incorporation interprétable en posant des questions LLMS, code pour le papier QA-EMB.
QA-EMBS construit des intégrés d'incorporation en posant une série de questions oui-non à un LLM autorégressif pré-formé. 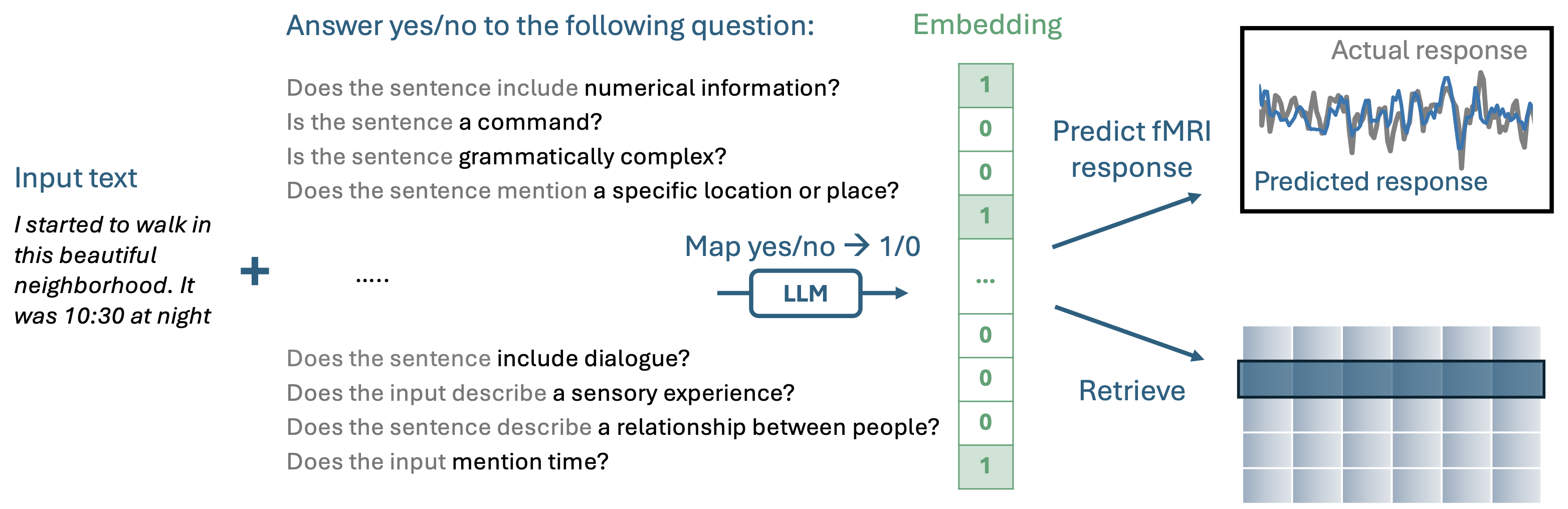
Si vous souhaitez simplement utiliser QA-EMB dans votre propre application, la manière la plus simple est le package IMODELSX. Pour installer, exécutez simplement pip install imodelsx .
Ensuite, vous pouvez générer vos propres intérêts interprétables en proposant des questions pour votre domaine:
from imodelsx import QAEmb
import pandas as pd
questions = [
'Is the input related to food preparation?' ,
'Does the input mention laughter?' ,
'Is there an expression of surprise?' ,
'Is there a depiction of a routine or habit?' ,
'Does the sentence contain stuttering?' ,
'Does the input contain a first-person pronoun?' ,
]
examples = [
'i sliced some cucumbers and then moved on to what was next' ,
'the kids were giggling about the silly things they did' ,
'and i was like whoa that was unexpected' ,
'walked down the path like i always did' ,
'um no um then it was all clear' ,
'i was walking to school and then i saw a cat' ,
]
checkpoint = 'meta-llama/Meta-Llama-3-8B-Instruct'
embedder = QAEmb (
questions = questions , checkpoint = checkpoint , use_cache = False )
embeddings = embedder ( examples )
df = pd . DataFrame ( embeddings . astype ( int ), columns = [
q . split ()[ - 1 ] for q in questions ])
df . index = examples
df . columns . name = 'Question (abbreviated)'
display ( df . style . background_gradient ( axis = None ))
- - - - - - - - DISPLAYS ANSWER FOR EACH QUESTION IN EMBEDDING - - - - - - - -Instructions pour l'installation des ensembles de données requis pour reproduire les expériences IRMf dans l'article.
python experiments/00_load_dataset.pydata Dir sous partout où vous l'exécutez et utilisera Datalad pour télécharger les données prétraitées ainsi que les espaces de fonctions nécessaires pour ajuster les modèles de codage sémantiqueneuro1.config.root_dir à l'endroit où vous souhaitez stocker les données{root_dir}/ds003020/derivative/pycortex-db/em_data à partir d'ici et de déplacer son contenu vers {root_dir}/em_dataneuro1.data.response_utils function load_response{root_dir}/ds003020/derivative/preprocessed_data/{subject} , ils sont stockés dans un fichier H5 pour chaque histoire, par exemple wheretheressmoke.h5neuro1.features.stim_utils Fonction load_story_wordseqs{root_dir}/ds003020/derivative/TextGrids", where each story has a TextGrid file, eg wherethessmoke.textgrid`{root_dir}/ds003020/derivative/respdict.json pour obtenir la durée de chaque histoireInstructions pour l'installation du code ici comme un package pour le développement complet.
pip install -e . Pour installer localement le package neuro1python 01_fit_encoding.py --subject UTS03 --feature eng1000 @ misc { benara2024crafting ,
title = { Crafting Interpretable Embeddings by Asking LLMs Questions },
author = { Vinamra Benara and Chandan Singh and John X. Morris and Richard Antonello and Ion Stoica and Alexander G. Huth and Jianfeng Gao },
year = { 2024 },
eprint = { 2405.16714 },
archivePrefix = { arXiv },
primaryClass = { cs.CL }
}

