Genaug: Aumentação de dados para geradores de texto Finetuning
Código para Genaug, apresentado em Genaug: Aumentação de dados para geradores de texto Finetuning publicados no EMNLP 2020 Deelio Workshop. Você pode citar o seguinte:
@inproceedings{feng-etal-2020-genaug,
title = "{G}en{A}ug: Data Augmentation for Finetuning Text Generators",
author = "Feng, Steven Y. and Gangal, Varun and Kang, Dongyeop and Mitamura, Teruko and Hovy, Eduard",
booktitle = "Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures",
month = nov, year = "2020", address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.deelio-1.4",
doi = "10.18653/v1/2020.deelio-1.4", pages = "29--42",
}
Autores: Steven Y. Feng, Varun Gangal, Dongyeop Kang, Teruko Mitamura, Eduard Hovy
A conversa pode ser encontrada aqui . Slides e outros recursos podem ser encontrados aqui .
Nota: As consultas devem ser direcionadas para [email protected] ou abrindo um problema aqui.
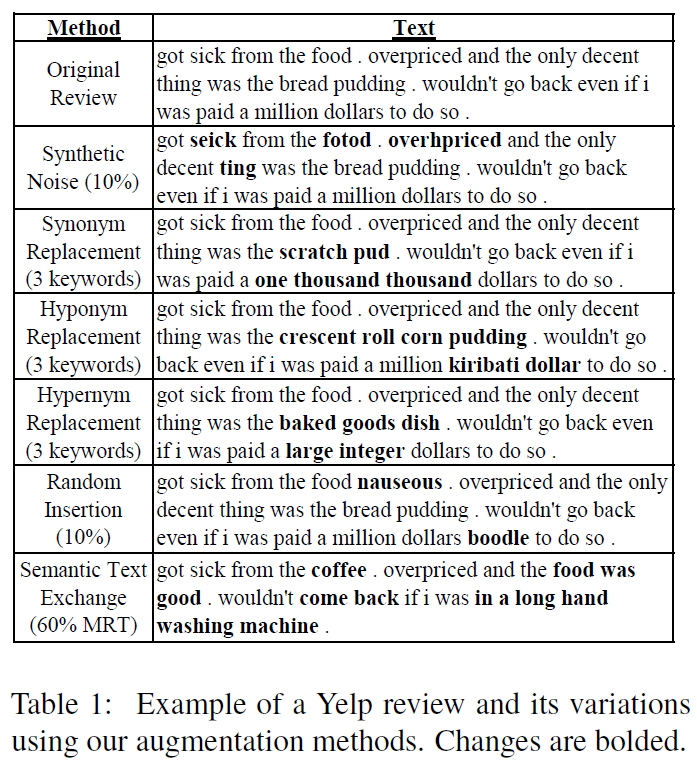
Recursos necessários
- Stanford Pos Tagger: https://nlp.stanford.edu/software/stanfordposger-2018-10-16.zip
- Stanford Corenlp: http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
Modelos pré -treinados/Finetuned (no Yelp):
- Bert Sentiment Regressor (FinetUned on YLR Reviews with Star Ratings): https://drive.google.com/drive/folders/1jt07zpxmmo9my5hh3mvjf8vmalzuuugf?usp=Sharing
- GPT-2 (FinetUned em 2 milhões de revisões de Yelp-para avaliação perplexidade e SLOR): https://drive.google.com/drive/folders/1j3jcw-qtdwxcyzv7lnjkvjzzpxifs2h?usp=Sharining
- Smerti-transformer (treinado em um subconjunto de ylr): https://drive.google.com/drive/folders/1a-jynp5so4lmv3ztgkmwq7be8coftf_b?usp=sharing
Dados
- "Stopwords.txt" contém uma lista de palavras de parada usadas.
- "yelp_train.txt", "yelp_val.txt" e "yelp_test.txt" contêm os exemplos inteiros de treinamento, validação e teste para YLR (porções de prompt e continuação).
- "yelp_train_0.5.txt" e "yelp_test_0.5.txt" contêm versões da primeira metade dos exemplos de treinamento e teste de YLR (somente partes do prompt).
- "Smerti_chosen_res.txt" contém os 150 substantivos escolhidos como entidades de reposição para a inferência de Smerti.
- "Smerti_train.csv" e "smerti_val.csv" contêm as divisões de treinamento e validação para Smerti-transformer, respectivamente.
Código
- A pasta "Augmentation_methods" contém código para os vários métodos de aumento da Genaug (excluindo Smerti).
- A pasta "avaliação" contém código para a avaliação. Especificamente, "get_unigram_distribution.py" é usado para a métrica rare_words (rwords) e "avaliar_combined.py" contém código para sbleu, utr, ttr e rwords. O subpasto "sentimento" contém código para avaliação de consistência do sentimento [mais detalhes posteriormente].
- A pasta "Finetuning_and_generation" contém scripts e código para modelos Finetuning GPT-2 e gerar saídas a partir de modelos GPT-2. Execute os dois scripts .sh para Finetune e gerar.
- A pasta "Processing_and_setup" contém código para processar e configurar os dados necessários para as experiências. "Continuação_postprocessor.py" limpa as saídas do GPT-2 (por exemplo, removendo marcas de exclamação à direita), "Genaug_finetuning_setup.ipynb" contém código para configurar os dados finais de aumento e a figura gpt-2, "GENAUG_SMERTI_PROCESSING.IPINB e Set. "Genaug_yelp_dataset_processing.ipynb" contém código para processar e configurar os dados do Yelp Reviews para YLR e 2 milhões de análises subconjuntos para avaliação de PPL e SLOR.
Código do método de aumento de Smerti
O código para o método de aumento de Smerti pode ser encontrado na pasta "Genaug Smerti-Transformer" neste repo . Este é o repositório oficial do "Smerti for Semantic Text Exchange" apresentado em manter a calma e ligar! Preservando o sentimento e a fluência na troca de texto semântico publicada no EMNLP-IJCNLP 2019.
Nota: Mais detalhes e comandos de exemplo para todo o código serão adicionados posteriormente.


