Genaug: Augmentation des données pour les générateurs de texte de finetuning
Code pour Genaug, présenté dans Genaug: Augmentation des données pour les générateurs de texte de finetuning publiés à l'atelier EMNLP 2020 Deelio. Vous pouvez le citer comme suit:
@inproceedings{feng-etal-2020-genaug,
title = "{G}en{A}ug: Data Augmentation for Finetuning Text Generators",
author = "Feng, Steven Y. and Gangal, Varun and Kang, Dongyeop and Mitamura, Teruko and Hovy, Eduard",
booktitle = "Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures",
month = nov, year = "2020", address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.deelio-1.4",
doi = "10.18653/v1/2020.deelio-1.4", pages = "29--42",
}
Auteurs: Steven Y. Feng, Varun Gangal, Dongyeop Kang, Teruko Mitamura, Eduard Hovy
La conversation peut être trouvée ici . Des diapositives et d'autres ressources peuvent être trouvées ici .
Remarque: Les demandes doivent être adressées à [email protected] ou en ouvrant un numéro ici.
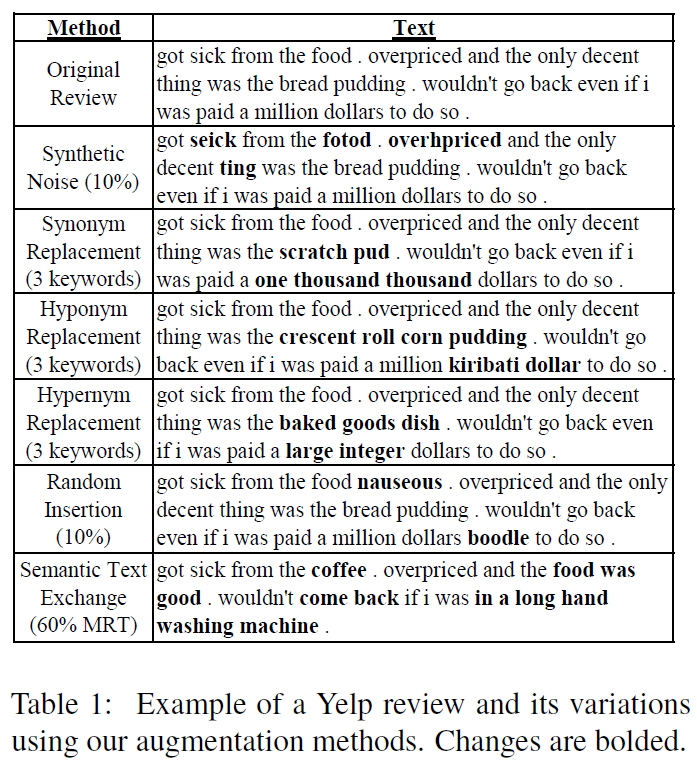
Ressources requises
- Stanford Pos Tagger: https://nlp.stanford.edu/software/stanford-postagger-2018-10-16.zip
- Stanford Corenlp: http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
Modèles pré-entraînés / finetunés (sur Yelp):
- Bert Sentiment Regressor (Finetuned sur les critiques YLR avec des notes étoiles): https://drive.google.com/drive/folders/1jt07zpxmmo9my5hh3mvjf8vmalzuuugf?usp=sharing
- GPT-2 (Finetuned sur 2 millions de critiques de Yelp - pour la perplexité et l'évaluation des slor): https://drive.google.com/drive/folders/1j3jcw-qtdwxcyzv7lonljkvjzpxifs2h?usp=sharing
- SMERI-TRANSFORMATE
Données
- "Stopwords.txt" contient une liste des mots d'arrêt utilisés.
- "yelp_train.txt", "yelp_val.txt", et "yelp_test.txt" contiennent l'ensemble des exemples de formation, de validation et de test pour YLR (portions d'invite et de continuation).
- "yelp_train_0.5.txt" et "yelp_test_0.5.txt" contiennent les versions au premier secondaire des exemples de formation et de test de YLR (parties invites uniquement).
- "Smitti_chosen_res.txt" contient les 150 noms choisis comme entités de remplacement pour l'inférence SMERTI.
- "Smitti_train.csv" et "smerti_val.csv" contiennent les divisions de formation et de validation pour SMERI-Transformateur, respectivement.
Code
- Le dossier "Augmentation_Methods" contient du code pour les différentes méthodes d'augmentation de Genaug (à l'exclusion de Smerti).
- Le dossier "Évaluation" contient du code pour l'évaluation. Plus précisément, "get_unigram_distribution.py" est utilisé pour la métrique rare_words (rwords), et "evaluate_combined.py" contient du code pour Sbleu, Utr, Ttr et Rwords. Le sous-dossier "Sentiment" contient du code pour l'évaluation de la cohérence du sentiment [plus de détails plus tard].
- Le dossier "finetuning_and_generation" contient des scripts et du code pour les modèles GPT-2 finetuning et la génération de sorties à partir de modèles GPT-2. Exécutez les deux scripts .sh à Finetune et générer.
- Le dossier "Processing_and_SetUp" contient du code pour traiter et configurer les données requises pour les expériences. "Continuation_postprocessor.py" nettoie les sorties GPT-2 (par exemple, les marques d'exclamation de fin de décapage), "Genaug_Finetuning_Settup.ipynb" contient du code pour configurer les données d'augmentation finales pour le GPT-2 Finetuning " "Genaug_yelp_dataset_processing.ipynb" contient du code pour traiter et configurer les données de revue YELP pour YLR et 2 millions de sous-ensembles de revues pour l'évaluation PPL et SLOR.
Code de méthode d'augmentation SMERTI
Le code de la méthode d'augmentation SMERTI peut être trouvé dans le dossier "Genaug Smerti-Transformateur" dans ce repo . Ceci est le dépôt officiel de "Smerti pour l'échange de texte sémantique" présenté dans Keep Calm et s'allume! Préservation du sentiment et de la maîtrise de l'échange de texte sémantique publié sur EMNLP-IJCNLP 2019.
Remarque: Plus de détails et d'exemples de commandes pour tout le code seront ajoutés à une date ultérieure.


