Genaug: Augmentasi Data untuk Generator Teks Finetuning
Kode untuk Genaug, disajikan dalam Genaug: Augmentasi data untuk generator teks yang diterbitkan di EMNLP 2020 Deelio Workshop. Anda dapat mengutipnya sebagai berikut:
@inproceedings{feng-etal-2020-genaug,
title = "{G}en{A}ug: Data Augmentation for Finetuning Text Generators",
author = "Feng, Steven Y. and Gangal, Varun and Kang, Dongyeop and Mitamura, Teruko and Hovy, Eduard",
booktitle = "Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures",
month = nov, year = "2020", address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.deelio-1.4",
doi = "10.18653/v1/2020.deelio-1.4", pages = "29--42",
}
Penulis: Steven Y. Feng, Varun Gangal, Dongyeop Kang, Teruko Mitamura, Eduard Hovy
Bicara dapat ditemukan di sini . Slide dan sumber daya lainnya dapat ditemukan di sini .
Catatan: Pertanyaan harus diarahkan ke [email protected] atau dengan membuka masalah di sini.
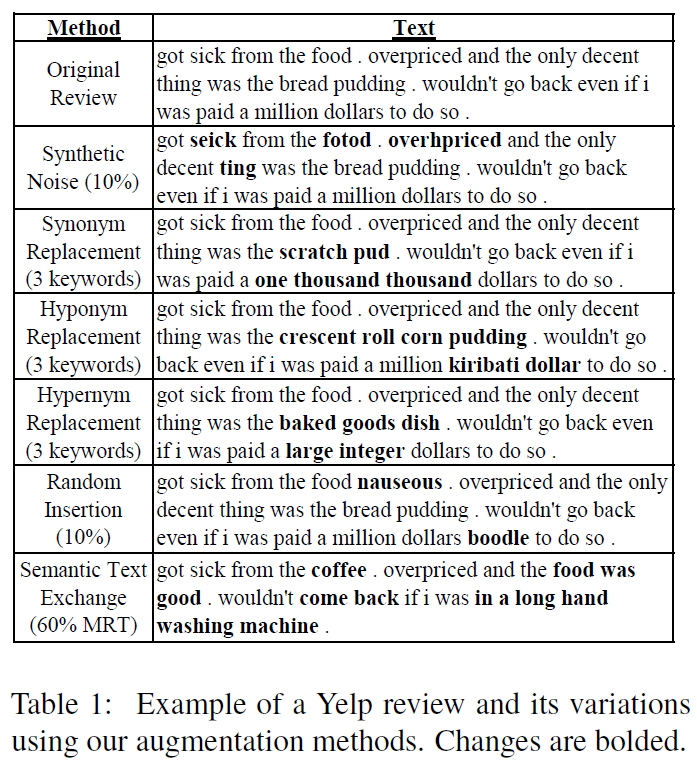
Sumber daya yang diperlukan
- Stanford Pos Tagger: https://nlp.stanford.edu/software/stanford-postagger-2018-10-16.zip
- Stanford Corenlp: http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
Model pretrained/finetuned (di Yelp):
- Bert Sentimen Regressor (finetuned pada ulasan YLR dengan peringkat bintang): https://drive.google.com/drive/folders/1jt07zpxmmo9my5hh3mvjf8vmalzuuugf?usp=sharing
- GPT-2 (Finetuned pada 2 juta ulasan Yelp-untuk evaluasi kebingungan dan slor): https://drive.google.com/drive/folders/1j3jcw-qtdwxcyzv7lonljkvjzpxifs2h ?usp=haring
- Smerti-transformer (dilatih pada subset ylr): https://drive.google.com/drive/folders/1a-jynp5so4lmv3ztgkmwq7be8coftf_b?usp=sharing
Data
- "stopwords.txt" berisi daftar stopword yang digunakan.
- "yelp_train.txt", "yelp_val.txt", dan "yelp_test.txt" berisi seluruh pelatihan, validasi, dan contoh pengujian untuk YLR (baik porsi prompt dan kelanjutan).
- "yelp_train_0.5.txt" dan "yelp_test_0.5.txt" berisi versi babak pertama dari contoh pelatihan dan pengujian YLR (hanya bagian cepat).
- "Smerti_chosen_res.txt" berisi 150 kata benda yang dipilih sebagai entitas pengganti untuk inferensi smerti.
- "Smerti_train.csv" dan "smerti_val.csv" masing-masing berisi pemisahan pelatihan dan validasi untuk Smerti-transformer.
Kode
- Folder "augmentation_methods" berisi kode untuk berbagai metode augmentasi Genaug (tidak termasuk smerti).
- Folder "Evaluasi" berisi kode untuk evaluasi. Secara khusus, "get_unigram_distribution.py" digunakan untuk metrik rare_words (rwords), dan "evaluate_combined.py" berisi kode untuk Sbleu, UTR, TTR, dan RWORDS. Sub-folder "sentimen" berisi kode untuk evaluasi konsistensi sentimen [lebih detail nanti].
- Folder "finetuning_and_generation" berisi skrip dan kode untuk finetuning model GPT-2 dan menghasilkan output dari model GPT-2. Jalankan dua skrip .sh untuk finetune dan hasilkan.
- Folder "processing_and_setup" berisi kode untuk memproses dan mengatur data yang diperlukan untuk percobaan. "Continuate_PostProcessor.py" membersihkan output GPT-2 (misalnya penelusuran tanda seru trailing), "Genaug_finetuning_setup.ipynb" berisi kode untuk mengatur data augmentasi akhir untuk finetuning GPT-2, "Genaug_smerti_processing. "Genaug_yelp_dataset_processing.ipynb" berisi kode untuk memproses dan mengatur data ulasan YELP untuk YLR dan 2 juta ulasan subset untuk evaluasi ppl dan slor.
Kode metode augmentasi smerti
Kode untuk metode augmentasi smerti dapat ditemukan di folder "Genaug Smerti-Transformer" di repo ini . Ini adalah repo resmi untuk "Smerti for Semantic Text Exchange" yang disajikan di Keep Calm and Reaktif! Melestarikan sentimen dan kelancaran dalam pertukaran teks semantik yang diterbitkan di EMNLP-IJCNLP 2019.
Catatan: Perintah lebih lanjut dan contoh untuk semua kode akan ditambahkan di kemudian hari.


