Genaug: Datenvergrößerung für Finetuning -Textgeneratoren
Code für Genaug, präsentiert in Genaug: Datenvergrößerung für Finetuning -Textgeneratoren, die im EMNLP 2020 Deelio Workshop veröffentlicht wurden. Sie können es wie folgt zitieren:
@inproceedings{feng-etal-2020-genaug,
title = "{G}en{A}ug: Data Augmentation for Finetuning Text Generators",
author = "Feng, Steven Y. and Gangal, Varun and Kang, Dongyeop and Mitamura, Teruko and Hovy, Eduard",
booktitle = "Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures",
month = nov, year = "2020", address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.deelio-1.4",
doi = "10.18653/v1/2020.deelio-1.4", pages = "29--42",
}
Autoren: Steven Y. Feng, Varun Gangal, Dongyeop Kang, Teruko Mitamura, Eduard Hovy
Reden finden Sie hier . Folien und andere Ressourcen finden Sie hier .
Hinweis: Anfragen sollten an [email protected] oder durch Eröffnung eines Problems hier angewiesen werden.
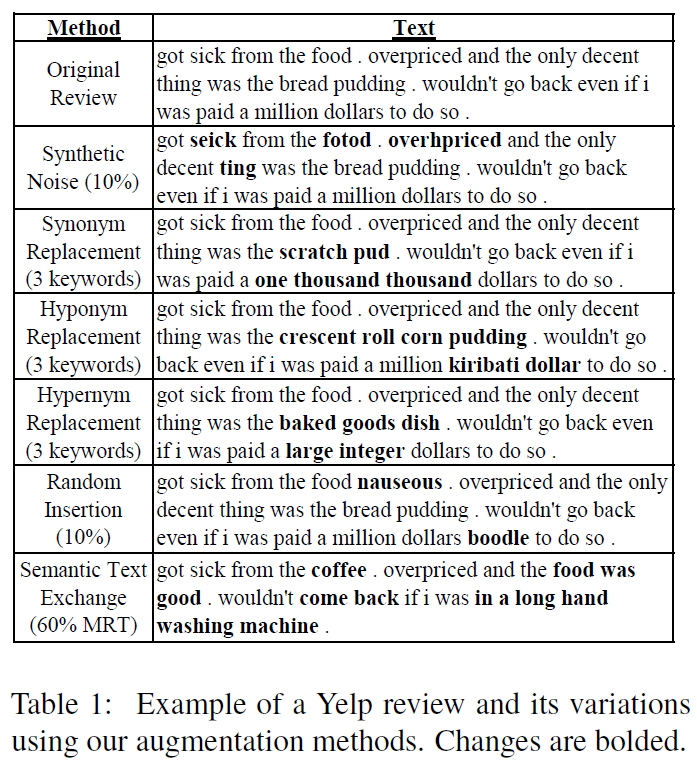
Erforderliche Ressourcen
- Stanford POS Tagger: https://nlp.stanford.edu/software/stanford-postagger-2018-10-16.zip
- Stanford Corenlp: http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
Vorbereitete/finatunierte Modelle (auf Yelp):
- Bert Sentiment Regressor (bei YLR -Bewertungen mit Sternenbewertungen abgeschlossen): https://drive.google.com/drive/folders/1jt07zpxmmo9my5HHH3MVJF8VMALzuuugf?usp=sharing
- GPT-2 (mit 2 Millionen yelp-Bewertungen abgeschlossen
- Smerti-transformator (ausgebildet auf einer Teilmenge von YLR)
Daten
- "Stopwords.txt" enthält eine Liste der verwendeten Stoppwörtern.
- "yelp_train.txt", "yelp_val.txt" und "yelp_test.txt" enthalten die gesamten Beispiele für das Training, die Validierung und das Testen für YLR (sowohl Eingabeaufforderungen als auch Fortsetzung).
- "yelp_train_0.5.txt" und "yelp_test_0.5.txt" enthalten Versionen des Trainings- und Testbeispiels von YLR (nur Eingabeaufforderungen).
- "SMERTI_CHOSE_RES.TXT" enthält die ausgewählten 150 Substantive als Ersatzeinheiten für SMERTI -Inferenz.
- "SMERTI_TRAIN.CSV" und "SMERTI_VAL.CSV" enthalten die Trainings- und Validierungsaufteilungen für Smerti-Transformer.
Code
- Der Ordner "Augmentation_Methods" enthält Code für die verschiedenen Genaug -Augmentationsmethoden (ohne SMERTI).
- Der Ordner "Evaluation" enthält Code für die Bewertung. Insbesondere "get_unigram_distribution.py" wird für die metrische Seltene_Words (RWords) verwendet, und "evaluate_combed.py" enthält Code für SBLU, UTR, TTR und RWords. Der Unterordner "Sentiment" enthält Code für die Bewertung der Sentiment-Konsistenz [weitere Details später].
- Der Ordner "FELLETUNININING_AND_GENERATION" enthält Skripte und Code für die Finetuning-GPT-2-Modelle und das Generieren von Ausgängen aus GPT-2-Modellen. Führen Sie die beiden .SH -Skripte aus, um zu beenden und zu generieren.
- Der Ordner "Processing_and_setup" enthält Code zum Verarbeiten und Einrichten der für die Experimente erforderlichen Daten. "Continuation_PostProcessor.py" reinigt die GPT-2-Ausgänge (z. B. abgestreifte nachfolgende Ausrufezeichen), "Genaug_finetuning_setup.ipynb" enthält Code, um die endgültigen Augmentationsdaten für GPT-2-Finetuning einrichten. "Genaug_yelp_dataset_processing.ipynb" enthält Code zum Verarbeiten und Einrichten der Yelp -Überprüfungsdaten für YLR- und 2 Millionen Überprüfungen für die PPL- und SLOR -Bewertung.
Smerti Augmentation Method Code
Der Code für die Smerti-Augmentationsmethode finden Sie in diesem Repo im Ordner "Genaug Smerti-Transformator". Dies ist das offizielle Repo für "Smerti for Semantic Text Exchange", das in Keep Calle und Switch einschaltet! Erhaltung der Stimmung und fließender Fließfähigkeit im semantischen Textaustausch, veröffentlicht am EMNLP-IJCNLP 2019.
Hinweis: Weitere Details und Beispielbefehle für den gesamten Code werden zu einem späteren Zeitpunkt hinzugefügt.


