Genaug: زيادة البيانات لمولدات النص
رمز Genaug ، المقدم في Genaug: زيادة البيانات لمولدات النصوص المحددة المنشورة في ورشة عمل EMNLP 2020 DEELIO. يمكنك الاستشهاد بها على النحو التالي:
@inproceedings{feng-etal-2020-genaug,
title = "{G}en{A}ug: Data Augmentation for Finetuning Text Generators",
author = "Feng, Steven Y. and Gangal, Varun and Kang, Dongyeop and Mitamura, Teruko and Hovy, Eduard",
booktitle = "Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures",
month = nov, year = "2020", address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.deelio-1.4",
doi = "10.18653/v1/2020.deelio-1.4", pages = "29--42",
}
المؤلفون: ستيفن ي. فنغ ، فارون جانجال ، دونجيوب كانغ ، تيروكو ميتامورا ، إدوارد هوفي
يمكن العثور على الكلام هنا . يمكن العثور على الشرائح والموارد الأخرى هنا .
ملاحظة: يجب توجيه الاستفسارات إلى [email protected] أو عن طريق فتح مشكلة هنا.
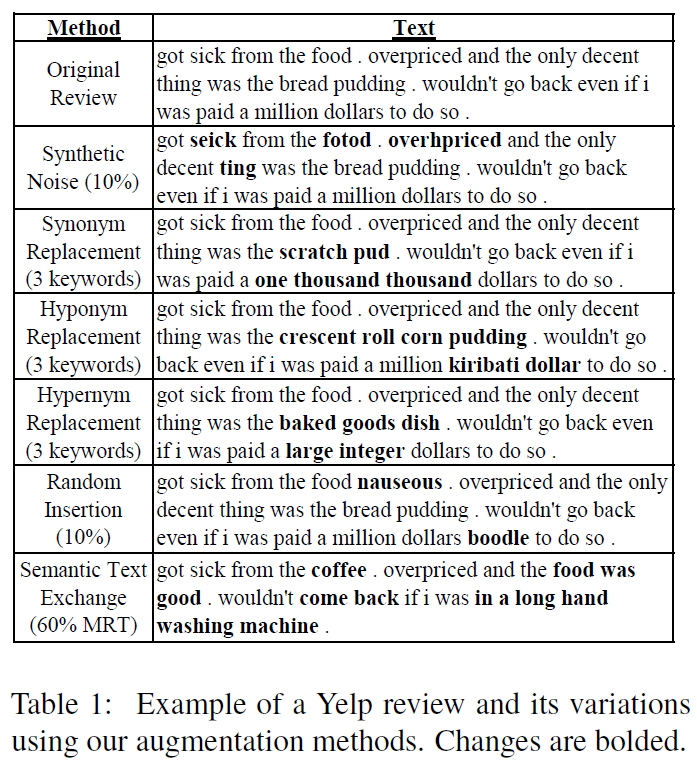
الموارد المطلوبة
- Stanford POS Tagger: https://nlp.stanford.edu/software/stanford-postagger-2018-10-16.zip
- Stanford Corenlp: http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
نماذج مسبقة/محفوظة بالحيوية (على Yelp):
- Bert Sentiment Regressor (Finetuned on ylr مع مراجعات النجوم): https://drive.google.com/drive/folders/1jt07zpxmmo9my5hh3mvjf8vmalzuuugf؟usp=sharing
- GPT-2 (Finetuned على 2 مليون مراجعات Yelp-للتقييم بين الحيرة وتقييم Slor): https://drive.google.com/drive/folders/1j3jcw-qtdwxcyzv7lonljkvjzpxfs2h؟usp=sharing=sharing
- Smerti-transformer (تم تدريبه على مجموعة فرعية من YLR): https://drive.google.com/drive/folders/1a-jynp5so4lmv3ztgkmwq7be8coftf_b؟usp=shark
بيانات
- يحتوي "stopwords.txt" على قائمة من الكلمات المتوقفة المستخدمة.
- يحتوي "yelp_train.txt" و "yelp_val.txt" و "yelp_test.txt" على أمثلة التدريب والتحقق من الصحة والاختبار بالكامل لـ YLR (أجزاء موجهة واستمرار).
- "yelp_train_0.5.txt" و "yelp_test_0.5
- "Smerti_chosen_res.txt" يحتوي على 150 اسمًا تم اختياره ككيانات بديلة لاستنتاج Smerti.
- "smerti_train.csv" و "smerti_val.csv" يحتويان على انقسامات التدريب والتحقق من صحة Smerti ، على التوالي.
شفرة
- يحتوي المجلد "mupmentation_methods" على رمز لمختلف أساليب تكبير Genaug (باستثناء Smerti).
- يحتوي مجلد "التقييم" على رمز للتقييم. على وجه التحديد ، يتم استخدام "get_unigram_distribution.py" لمقياس Rare_words (Rwords) ، و "alualate_combined.py" يحتوي على رمز لـ Sbleu و UTR و TTR و Rwords. يحتوي المجلس الفرعي "المشاعر" على رمز لتقييم تناسق المشاعر [مزيد من التفاصيل لاحقًا].
- يحتوي المجلد "Finetuning_and_generation" على البرامج النصية ورمز نماذج GPT-2 وتوليد مخرجات من نماذج GPT-2. تشغيل اثنين من البرامج النصية .sh إلى Finetune وتوليد.
- يحتوي المجلد "Processing_and_setup" على رمز لمعالجة البيانات المطلوبة وإعدادها للتجارب. "continuation_postprocessor.py" ينظف مخرجات GPT-2 (على سبيل المثال علامات التعجب المتخلف) ، "genaug_finetuning_setup.ipynb" يحتوي على رمز لإعداد بيانات التعزيز النهائية لتجهيزات GPT-2 ، "genaug_smerti_processing.ipynb conduct to smerti. "genaug_yelp_dataset_processing.ipynb" يحتوي على رمز لمعالجة وإعداد بيانات مراجعات YELP لـ YLR و 2 مليون مراجعات فرعية لتقييم PPL و SLOR.
رمز طريقة تكبير Smerti
يمكن العثور على رمز لطريقة تكبير Smerti في مجلد "Genaug Smerti-Transformer" في هذا الريبو . هذا هو الريبو الرسمي لـ "Smerti for Exchange Deforce Exchange" المقدمة في Keep Call and Switch! الحفاظ على المشاعر والطلاقة في تبادل النص الدلالي المنشور في EMNLP-IJCNLP 2019.
ملاحظة: سيتم إضافة مزيد من التفاصيل والأوامر المثالية لجميع الكود في وقت لاحق.


