kr3
1.0.0
Conjunto de dados de classificação de sentimentos coreanos
? Veja mais
Postagem no blog em coreano
Abraçando o hub de rosto
Conjunto de dados Kaggle
GitLab (repo original): consulte o repo completo e o log git aqui.
Devido ao limite de tamanho do arquivo, não conseguimos incluir o conjunto de dados no repo GitHub.
Verifique os links acima para acessar o conjunto de dados.
Fornecemos duas versões, KR3 e KR3_RAW , em dois formatos, .parquet e .csv .
| É pré -processado? | Colunas | |
|---|---|---|
| KR3 | Sim | 'Classificação' e 'reivew' |
| KR3_RAW | Não | 'Classificação', 'revisão', 'região' e 'categoria' |
Coluna 'Classificação' é o rótulo para classificação de sentimentos.
0 para revisões negativas , 1 para revisões positivas . Estes são os rótulos para o aprendizado supervisionado clássico.
Revisões positivas e revisões negativas são misturadas dentro deste rótulo. Considere isso. A classificação 3 de 5 seria uma revisão positiva para alguém, mas o contrário para outra pessoa. Muitos conjuntos de dados anteriores excluíram esses dados ambíguos , mas os incluímos para fins de pré-treinamento ou outro uso.
| rótulo | #(amostras) |
|---|---|
| 0 (negativo) | 70910 |
| 1 (positivo) | 388111 |
| 2 (ambíguo) | (+182741) |
| Total | 459021 (+182741) |
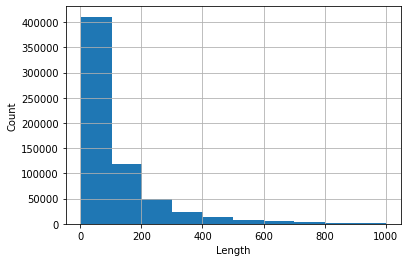
>>> kr3['Review'].str.len().describe()
count 641762.000000
mean 127.470026
std 178.357159
min 3.000000
25% 35.000000
50% 67.000000
75% 149.000000
max 3971.000000
Histograma de revisões cujo comprimento <1000 (estes ocupam mais de 99% do conjunto de dados).
1,'고기가 정말 맛있었어요! 육즙이 가득 있어서 너무 좋았아요 일하시는 분들 너무 친절하고 좋습니다 가격이 조금 있기는 하지만 그만한 맛이라고 생각!'
0,'11시부터 줄을 서서 주문함. 유명해서 가봤는데, 가격은 비싸고 맛은 그럭저럭. 10분 기다리고 먹을만하고, 그 이상 기다려야 하면 안 먹는 게 나음'
1,'맛있어요 항상 가는 단골이에요. 냄새도 안 나고 구수해요.'
2,'유명세에 비해 순대 맛은 그저 그런 순대 속이 그냥 당면이다'
Leia o ReadMe in /data .
Tutorial simples. Veja tutorial.ipynb .
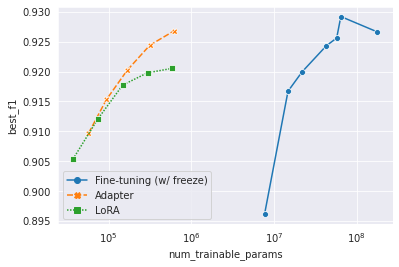
À medida que o tamanho do modelo pré-treinado cresce exponencialmente, é ineficaz ou quase impossível armazenar todos os modelos ajustados. Aprendizado de transferência com eficiência de parâmetro, ou ajuste com eficiência de parâmetro, visa a adaptação apenas com pequenos módulos. Utilizamos o Bert-base de 178m mulitilíngue como modelo pré-treinado. Utilizamos o adaptador (Houlsby et al., 2019) e Lora (Hu et al., 2022) como métodos de aprendizado de transferência. Veja o código em /yejoon . Consulte o painel da W&B para obter registros de treinamento e pesos do modelo.
A propósito, se você estiver interessado neste tópico, ele et al., 2022 é um papel de leitura obrigatória e até um bom ponto de partida para o tópico.
Para utilizar dados não marcados, ou seja, dados ambíguos, seguimos por não parar de pré-treinamento e executar o pré-rano adaptável na Mulitilinguly 178m Bert-Base. Os detalhes e implementações estão em /dongin .
CC BY-NC-SA 4.0
Concluímos que a liberação e o uso do KR3 se enquadram na gama de uso justo (공정 이용 이용) declarado na Lei de Direitos Autorais coreanos (저작권법). Esclarecemos ainda que não concordamos com os termos de serviço de nenhum sites que possam proibir o rastreamento da web. Em outras palavras, o rastreamento da web que fizemos foi prosseguido sem fazer login no site. Apesar de tudo isso, sinta -se à vontade para entrar em contato com qualquer um dos colaboradores se você notar algum problema legal.
(Ordem alfabética)
Dongin Jung
Hyunwoo Kwak
Kaeun Lee
Yejoon Lee
Este trabalho foi realizado como Diya 4 기. Os recursos de computação necessários para o trabalho foram apoiados por DIYA e Surromind.ai.


