kr3
1.0.0
Korean Sentiment Classification Dataset
? Sehen Sie mehr
Blog -Beitrag auf Koreanisch
Umarmung des Gesichtszentrums
Kaggle -Datensatz
GitLab (Original Repo): Siehe das vollständige Repo und Git Anmeldung hier.
Aufgrund der Dateigrößengrenze konnten wir den Datensatz in GitHub Repo nicht aufnehmen.
Bitte überprüfen Sie die obigen Links, um auf den Datensatz zuzugreifen.
Wir bieten zwei Versionen, KR3 und Kr3_RAW , in zwei Formaten, Parquet und .csv .
| Ist es vorverarbeitet? | Spalten | |
|---|---|---|
| KR3 | Ja | 'Rating' und 'Reivew' |
| KR3_RAW | NEIN | "Rating", "Überprüfung", "Region" und "Kategorie" |
Die Spalte 'Bewertung' ist das Etikett für die Stimmungsklassifizierung.
0 für negative Bewertungen, 1 für positive Bewertungen. Dies sind die Etiketten für klassisches überwachtes Lernen.
Positive Bewertungen und negative Bewertungen werden in diesem Etikett durcheinander gebracht. Betrachten Sie das. Die Bewertung von 3 von 5 wäre eine positive Bewertung für jemanden, aber das Gegenteil für jemand anderen. Viele frühere Datensätze haben diese mehrdeutigen Daten ausgeschlossen, aber wir schließen sie zum Zweck der Vorausbildung oder anderer Verwendung ein.
| Etikett | #(Proben) |
|---|---|
| 0 (negativ) | 70910 |
| 1 (positiv) | 388111 |
| 2 (mehrdeutig) | (+182741) |
| Gesamt | 459021 (+182741) |
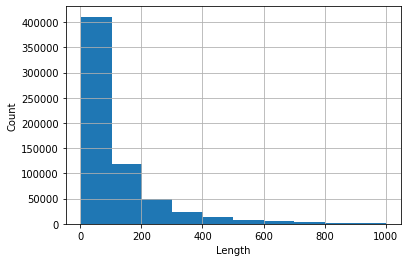
>>> kr3['Review'].str.len().describe()
count 641762.000000
mean 127.470026
std 178.357159
min 3.000000
25% 35.000000
50% 67.000000
75% 149.000000
max 3971.000000
Histogramm von Bewertungen, deren Länge <1000 (diese nehmen mehr als 99% des Datensatzes auf).
1,'고기가 정말 맛있었어요! 육즙이 가득 있어서 너무 좋았아요 일하시는 분들 너무 친절하고 좋습니다 가격이 조금 있기는 하지만 그만한 맛이라고 생각!'
0,'11시부터 줄을 서서 주문함. 유명해서 가봤는데, 가격은 비싸고 맛은 그럭저럭. 10분 기다리고 먹을만하고, 그 이상 기다려야 하면 안 먹는 게 나음'
1,'맛있어요 항상 가는 단골이에요. 냄새도 안 나고 구수해요.'
2,'유명세에 비해 순대 맛은 그저 그런 순대 속이 그냥 당면이다'
ReadMe in /data .
Einfaches Tutorial. Siehe tutorial.ipynb .
Wenn die Größe des vorgebreiteten Modells exponentiell wächst, ist es ineffiv oder nahezu unmöglich, alle fein abgestimmten Modelle zu speichern. Parameter-effizientes Transferlernen oder parametereffizientes Tuning zielt darauf ab, die Anpassung nur mit kleinen Modulen zu erreichen. Wir verwendeten mulituale 178m Bert-Base als vorgebildetes Modell. Wir verwendeten Adapter (Houlsby et al., 2019) und Lora (Hu et al., 2022) als Transferlernmethoden. Siehe den Code in /yejoon . In W & B Dashboard finden Sie Trainingsaufzeichnungen und Modellgewichte.
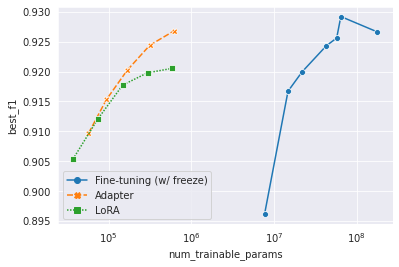
Übrigens, wenn Sie an diesem Thema interessiert sind, ist er et al., 2022 ein Muss und sogar ein guter Startplatz für das Thema.
Um unbezeichnete Daten zu verwenden, dh mehrdeutige Daten, folgen wir nicht, dass die Vorbereitung auf die Vorbereitung stoppt und adaptive Vorbereitungen für mulitellinuelle 178m-Bert-Base durchführen. Die Details und Implementierungen sind in /dongin .
CC BY-NC-SA 4.0
Wir kamen zu dem Schluss, dass die Veröffentlichung und Verwendung von KR3 in den Bereich des fairen Gebrauchs (공정 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용) in den im koreanischen copyright) angegeben. Wir stellen ferner klar, dass wir den Nutzungsbedingungen von Websites, die das Web -Crawling möglicherweise verbieten könnten, nicht zustimmen. Mit anderen Worten, Web Crawling, das wir getan haben, wurde ohne Anmeldung auf der Website fortgesetzt. Trotz all dessen können Sie sich gerne an einen der Mitwirkenden in Verbindung setzen, wenn Sie rechtliche Probleme bemerken.
(Alphabetische Ordnung)
Dongin Jung
Hyunwoo Kwak
Kaeun Lee
Yejoon Lee
Diese Arbeit wurde als Diya 4 기 durchgeführt. Rechenressourcen für die Arbeit wurden von Diya und Surromind.ai unterstützt.


