kr3
1.0.0
Dataset Klasifikasi Sentimen Korea
? Lihat lebih banyak
Posting blog dalam bahasa Korea
Memeluk hub wajah
Kaggle Dataset
GitLab (Repo Asli): Lihat repo lengkap dan login git di sini.
Karena batas ukuran file, kami tidak dapat menyertakan dataset di Github Repo.
Silakan periksa tautan di atas untuk mengakses dataset.
Kami menyediakan dua versi, KR3 dan KR3_RAW , dalam dua format, .parquet dan .csv .
| Apakah itu preprosesed? | Kolom | |
|---|---|---|
| KR3 | Ya | 'Peringkat' dan 'Reivew' |
| KR3_RAW | TIDAK | 'Rating', 'Review', 'Region', dan 'Category' |
Kolom 'Rating' adalah label untuk klasifikasi sentimen.
0 untuk ulasan negatif , 1 untuk ulasan positif . Ini adalah label untuk pembelajaran klasik yang diawasi.
Ulasan positif dan ulasan negatif dicampur dalam label ini. Pertimbangkan ini. Peringkat 3 dari 5 akan menjadi ulasan positif bagi seseorang, tetapi sebaliknya bagi orang lain. Banyak set data sebelumnya mengecualikan data ambigu ini, tetapi kami memasukkannya untuk tujuan pra-pelatihan atau penggunaan lainnya.
| label | #(sampel) |
|---|---|
| 0 (negatif) | 70910 |
| 1 (positif) | 388111 |
| 2 (ambigu) | (+182741) |
| Total | 459021 (+182741) |
>>> kr3['Review'].str.len().describe()
count 641762.000000
mean 127.470026
std 178.357159
min 3.000000
25% 35.000000
50% 67.000000
75% 149.000000
max 3971.000000
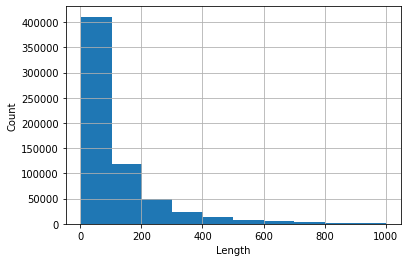
Histogram ulasan yang panjangnya <1000 (ini memakan lebih dari 99% dari dataset).
1,'고기가 정말 맛있었어요! 육즙이 가득 있어서 너무 좋았아요 일하시는 분들 너무 친절하고 좋습니다 가격이 조금 있기는 하지만 그만한 맛이라고 생각!'
0,'11시부터 줄을 서서 주문함. 유명해서 가봤는데, 가격은 비싸고 맛은 그럭저럭. 10분 기다리고 먹을만하고, 그 이상 기다려야 하면 안 먹는 게 나음'
1,'맛있어요 항상 가는 단골이에요. 냄새도 안 나고 구수해요.'
2,'유명세에 비해 순대 맛은 그저 그런 순대 속이 그냥 당면이다'
Baca ReadMe di /data .
Tutorial sederhana. Lihat tutorial.ipynb .
Karena ukuran model pra-terlatih tumbuh secara eksponensial, tidak efisien atau hampir tidak mungkin untuk menyimpan semua model yang disesuaikan. Pembelajaran transfer yang efisien parameter, atau penyetelan parameter-efisien, bertujuan untuk mencapai adaptasi hanya dengan modul kecil. Kami menggunakan mulityual 178m Bert-base sebagai model pra-terlatih. Kami menggunakan adaptor (Houlsby et al., 2019) dan Lora (Hu et al., 2022) sebagai metode pembelajaran transfer. Lihat kode di /yejoon . Lihat Dasbor W&B untuk catatan pelatihan dan bobot model.
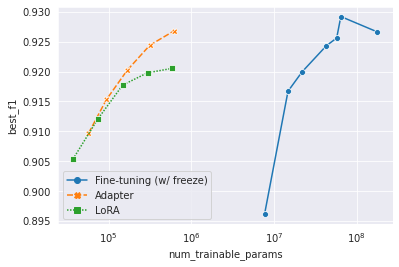
Ngomong-ngomong, jika Anda tertarik dengan topik ini, He et al., 2022 adalah kertas yang harus dibaca dan bahkan tempat awal yang baik untuk topik tersebut.
Untuk memanfaatkan data yang tidak berlabel, yaitu data yang ambigu, kami diikuti oleh Don't Stop Pretraining dan melakukan pretrain adaptif pada mulityual 178m Bert-base. Detail dan implementasinya ada di /dongin .
CC BY-NC-SA 4.0
Kami menyimpulkan bahwa rilis dan penggunaan KR3 termasuk dalam berbagai penggunaan yang adil (공정 이용) yang dinyatakan dalam Undang -Undang Hak Cipta Korea (저작권법). Kami lebih lanjut mengklarifikasi bahwa kami tidak menyetujui ketentuan layanan dari situs web mana pun yang mungkin melarang merangkak web. Dengan kata lain, perayapan web yang telah kami lakukan telah dilanjutkan tanpa masuk ke situs web. Terlepas dari semua ini, jangan ragu untuk menghubungi salah satu kontributor jika Anda melihat masalah hukum.
(Urutan abjad)
Dongin Jung
Hyunwoo Kwak
Kaeun Lee
Yejoon Lee
Pekerjaan ini dilakukan sebagai Diya 4 기. Hitung sumber daya yang dibutuhkan untuk pekerjaan didukung oleh Diya dan Surromind.ai.


