kr3
1.0.0
Ensemble de données de classification des sentiments coréens
? Voir plus
Article de blog en coréen
Hub étreint
Ensemble de données Kaggle
GitLab (Repo original): Voir le repo complet et Git Connectez-vous ici.
En raison de la limite de taille du fichier, nous n'avons pas pu inclure l'ensemble de données dans le dépôt GitHub.
Veuillez vérifier les liens ci-dessus pour accéder à l'ensemble de données.
Nous fournissons deux versions, KR3 et KR3_RAW , en deux formats, .Parquet et .csv .
| Est-ce prétraité? | Colonnes | |
|---|---|---|
| kr3 | Oui | «Évaluation» et «Reivew» |
| kr3_raw | Non | «Évaluation», «revue», «région» et «catégorie» |
La «note» de la colonne est l'étiquette de la classification des sentiments.
0 pour les critiques négatives , 1 pour les revues positives . Ce sont les étiquettes de l'apprentissage supervisé classique.
Les critiques positives et les critiques négatives sont mitigées dans cette étiquette. Considérez ceci. La note de 3 sur 5 serait une revue positive pour quelqu'un, mais le contraire pour quelqu'un d'autre. De nombreux ensembles de données précédents ont exclu ces données ambiguës , mais nous les incluons à des fins de pré-formation ou d'une autre utilisation.
| étiquette | # (échantillons) |
|---|---|
| 0 (négatif) | 70910 |
| 1 (positif) | 388111 |
| 2 (ambigu) | (+182741) |
| Total | 459021 (+182741) |
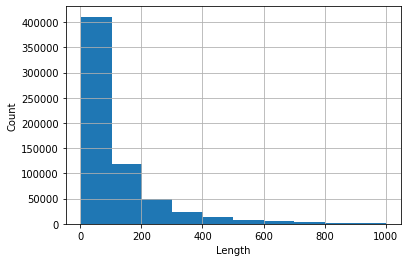
>>> kr3['Review'].str.len().describe()
count 641762.000000
mean 127.470026
std 178.357159
min 3.000000
25% 35.000000
50% 67.000000
75% 149.000000
max 3971.000000
Histogramme des revues dont la longueur <1000 (celles-ci occupent plus de 99% de l'ensemble de données).
1,'고기가 정말 맛있었어요! 육즙이 가득 있어서 너무 좋았아요 일하시는 분들 너무 친절하고 좋습니다 가격이 조금 있기는 하지만 그만한 맛이라고 생각!'
0,'11시부터 줄을 서서 주문함. 유명해서 가봤는데, 가격은 비싸고 맛은 그럭저럭. 10분 기다리고 먹을만하고, 그 이상 기다려야 하면 안 먹는 게 나음'
1,'맛있어요 항상 가는 단골이에요. 냄새도 안 나고 구수해요.'
2,'유명세에 비해 순대 맛은 그저 그런 순대 속이 그냥 당면이다'
Lisez la lecture dans /data .
Tutoriel simple. Voir tutorial.ipynb .
Au fur et à mesure que la taille du modèle pré-formé augmente de façon exponentielle, il est ineffect ou presque impossible de stocker tous les modèles affinés. L'apprentissage du transfert économe en paramètres, ou un réglage économe en paramètres, vise à atteindre l'adaptation uniquement avec de petits modules. Nous avons utilisé la base de Bert Mulitilingue de 178m comme modèle pré-formé. Nous avons utilisé l'adaptateur (Houlsby et al., 2019) et Lora (Hu et al., 2022) comme méthodes d'apprentissage du transfert. Voir le code dans /yejoon . Voir le tableau de bord W&B pour la formation des enregistrements et les poids du modèle.
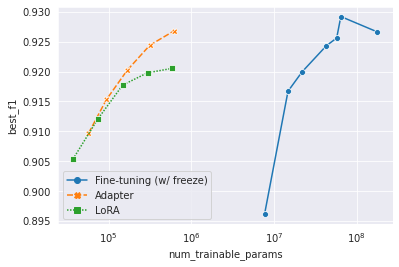
Soit dit en passant, si vous êtes intéressé par ce sujet, il et al., 2022 est un article incontournable et même un bon point de départ pour le sujet.
Pour utiliser des données non marquées, c'est-à-dire des données ambiguës, nous avons suivi de Don’t Stop Pretaining et effectuer une prétrainte adaptative sur la base de Bert Mulitilingue de 178m. Les détails et les implémentations sont dans /dongin .
CC BY-NC-SA 4.0
Nous avons conclu que la libération et l'utilisation de KR3 entrent dans la gamme d'utilisation équitable (공정 공정) énoncée dans la loi coréenne sur le droit d'auteur (저작권법). Nous clarifions en outre que nous n'avons pas accepté les conditions d'utilisation des sites Web qui pourraient interdire le compromis Web. En d'autres termes, le compromis Web que nous avons fait a été procédé sans se connecter au site Web. Malgré tous ces éléments, n'hésitez pas à contacter l'un des contributeurs si vous remarquez des problèmes juridiques.
(Ordre alphabétique)
Dongin Jung
Hyunwoo Kwak
Kaeun Lee
Yejoon Lee
Ce travail a été effectué comme diya 4 기. Les ressources de calcul nécessaires pour le travail ont été soutenues par Diya et Surromind.ai.


