kr3
1.0.0
Conjunto de datos de clasificación de sentimientos coreanos
? Ver más
Publicación de blog en coreano
Centro de cara abrazando
Conjunto de datos de Kaggle
GITLAB (Repo original): vea el repositorio completo y el registro de Git aquí.
Debido al límite del tamaño del archivo, no pudimos incluir el conjunto de datos en el repositorio de GitHub.
Verifique los enlaces de arriba para acceder al conjunto de datos.
Proporcionamos dos versiones, KR3 y KR3_RAW , en dos formatos, .Parquet y .csv .
| ¿Está preprocesado? | Columnas | |
|---|---|---|
| KR3 | Sí | 'Calificación' y 'Reivew' |
| kr3_raw | No | 'Calificación', 'Revisión', 'Región' y 'Categoría' |
La 'calificación' de la columna es la etiqueta para la clasificación de sentimientos.
0 Para revisiones negativas , 1 para revisiones positivas . Estas son las etiquetas para el aprendizaje supervisado clásico.
Las revisiones positivas y las revisiones negativas se mezclan dentro de esta etiqueta. Considere esto. La calificación 3 de 5 sería una revisión positiva para alguien, pero lo contrario para otra persona. Muchos conjuntos de datos anteriores excluyeron estos datos ambiguos , pero los incluimos con el propósito de pre-entrenamiento u otro uso.
| etiqueta | #(muestras) |
|---|---|
| 0 (negativo) | 70910 |
| 1 (positivo) | 388111 |
| 2 (ambiguo) | (+182741) |
| Total | 459021 (+182741) |
>>> kr3['Review'].str.len().describe()
count 641762.000000
mean 127.470026
std 178.357159
min 3.000000
25% 35.000000
50% 67.000000
75% 149.000000
max 3971.000000
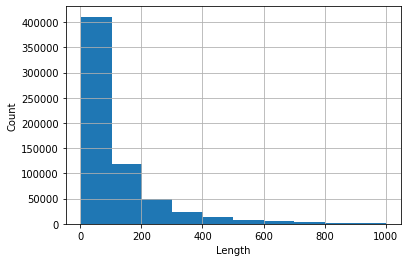
Histograma de revisiones cuya longitud <1000 (estos ocupan más del 99% del conjunto de datos).
1,'고기가 정말 맛있었어요! 육즙이 가득 있어서 너무 좋았아요 일하시는 분들 너무 친절하고 좋습니다 가격이 조금 있기는 하지만 그만한 맛이라고 생각!'
0,'11시부터 줄을 서서 주문함. 유명해서 가봤는데, 가격은 비싸고 맛은 그럭저럭. 10분 기다리고 먹을만하고, 그 이상 기다려야 하면 안 먹는 게 나음'
1,'맛있어요 항상 가는 단골이에요. 냄새도 안 나고 구수해요.'
2,'유명세에 비해 순대 맛은 그저 그런 순대 속이 그냥 당면이다'
Lea Readme In /data .
Tutorial simple. Ver tutorial.ipynb .
A medida que el tamaño del modelo previamente capacitado crece exponencialmente, es ineficiente o casi imposible almacenar todos los modelos ajustados. El aprendizaje de transferencia de parámetros-eficiente, o ajuste de los parámetros eficientes, tiene como objetivo una adaptación de rendimiento solo con pequeños módulos. Utilizamos 178M Bert-Base mulitilingües como modelo previamente capacitado. Utilizamos adaptador (Houlsby et al., 2019) y Lora (Hu et al., 2022) como métodos de aprendizaje de transferencia. Vea el código en /yejoon . Vea el tablero de W&B para obtener registros de entrenamiento y pesos de modelos.
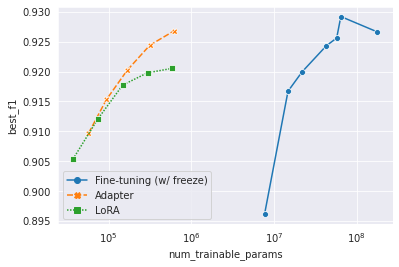
Por cierto, si está interesado en este tema, He et al., 2022 es un documento de lectura obligada e incluso un buen lugar de inicio para el tema.
Para utilizar datos no etiquetados, es decir, datos ambiguos, seguimos por no dejar de pretrarse y realizar un pretrén adaptativo en la base mulitilingüe de 178M. Los detalles e implementaciones están en /dongin .
CC BY-NC-SA 4.0
Llegamos a la conclusión de que el lanzamiento y el uso de KR3 caen en el rango de uso justo (공정 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 이용 공정 공정 공정 이용 공정 공정 이용 공정 공정 공정 공정 공정 공정 공정 공정 공정 공정 eléctrico eléctrica. Además, aclaramos que no aceptamos los términos de servicio de ningún sitio web que pueda prohibir el rastreo web. En otras palabras, el rastreo web que hemos hecho se realizó sin iniciar sesión en el sitio web. A pesar de todo esto, no dude en contactar a cualquiera de los contribuyentes si nota algún problema legal.
(Orden alfabética)
Dongin Jung
Hyunwoo kwak
Kaeun Lee
Yijoon Lee
Este trabajo se realizó como Diya 4 기. Los recursos de cálculo necesarios para el trabajo fueron apoyados por Diya y Surmind.ai.


