Transformador-tts
- Uma implementação de Pytorch da síntese de fala neural com a Rede de Transformadores
- Esse modelo pode ser treinado cerca de 3 a 4 vezes mais rápido que o conhecido modelo SEQ2SEQ como o Tacotron, e a qualidade da fala sintetizada é quase a mesma. Foi confirmado através do experimento que levou cerca de 0,5 segundo por etapa.
- Não usei o vocoder wavenet, mas aprendi a rede post usando o modelo CBHG de tacotron e converti o espectrograma em onda bruta usando o algoritmo Griffin-Lim.
Requisitos
- Instale o Python 3
- Instale pytorch == 0.4.0
- Instalar requisitos:
pip install -r requirements.txt
Dados
- Usei o conjunto de dados LJSpeech, que consiste em pares de script de texto e arquivos WAV. O conjunto de dados completo (13.100 pares) pode ser baixado aqui. Referi -me https://github.com/keithito/tacotron e https://github.com/kyubyong/dc_tts para o código de pré -processamento.
Modelo pré -terenciado
- Você pode baixar o modelo pré -terenciado aqui (160K para modelo AR / 100k para postnet)
- Localize o modelo pré -treinamento no ponto de verificação/ diretório.
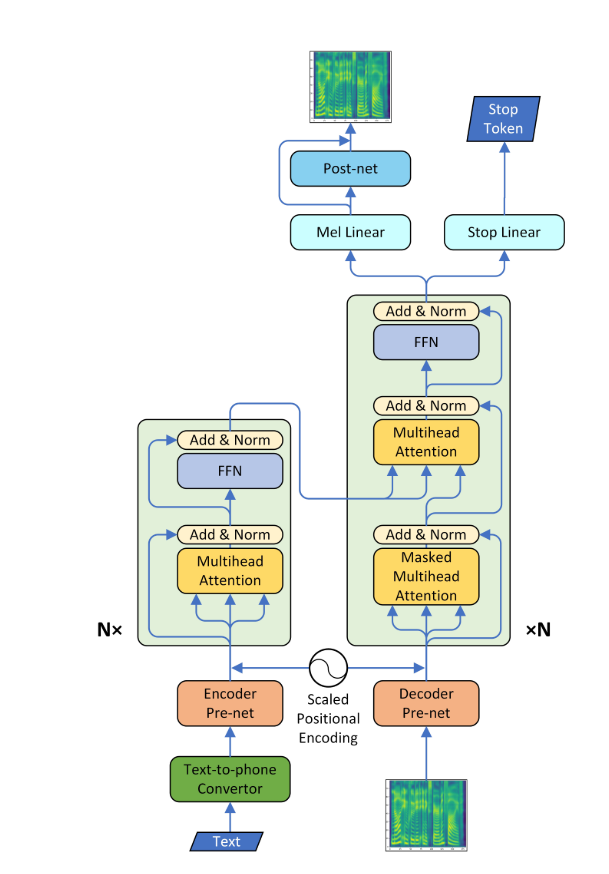
Parcelas de atenção
- Um alinhamento diagonal apareceu após cerca de 15 mil passos. As parcelas de atenção abaixo estão em 160 mil etapas. As parcelas representam a atenção de várias camadas de todas as camadas. Neste experimento, h = 4 é usado para três camadas de atenção. Portanto, 12 gráficos de atenção foram atraídos para cada um dos codificadores, decodificadores e codificadores. Com exceção do decodificador, apenas alguns multiheads mostraram alinhamento diagonal.
Codificador de ATENHORAÇÃO

Decodificador de atenção
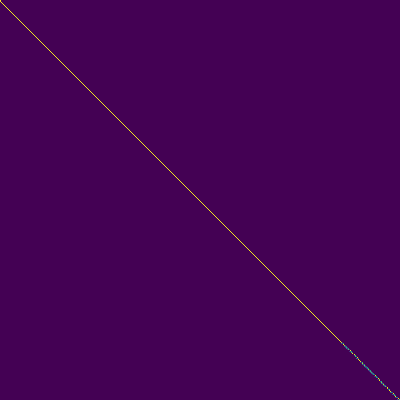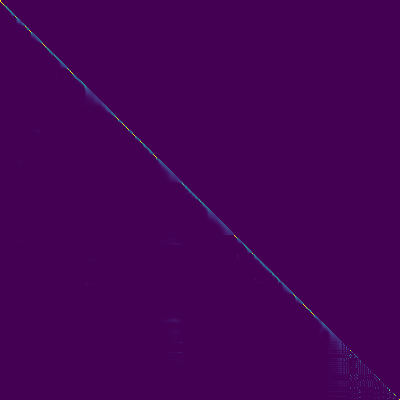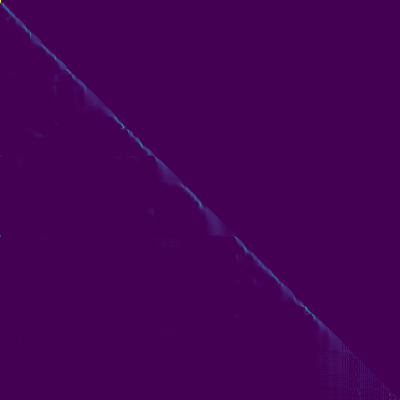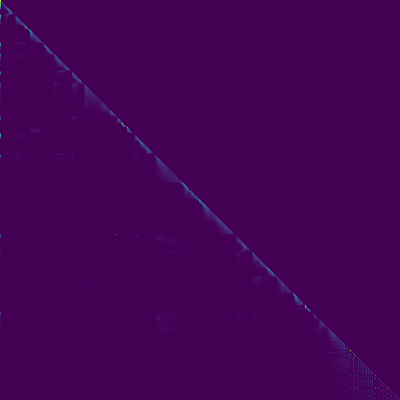
ATENÇÃO ENCODER-DOCODER

Curvas de aprendizado e alfas
- Eu usei o aquecimento e decadência no estilo Noam da mesma forma que o Tacotron
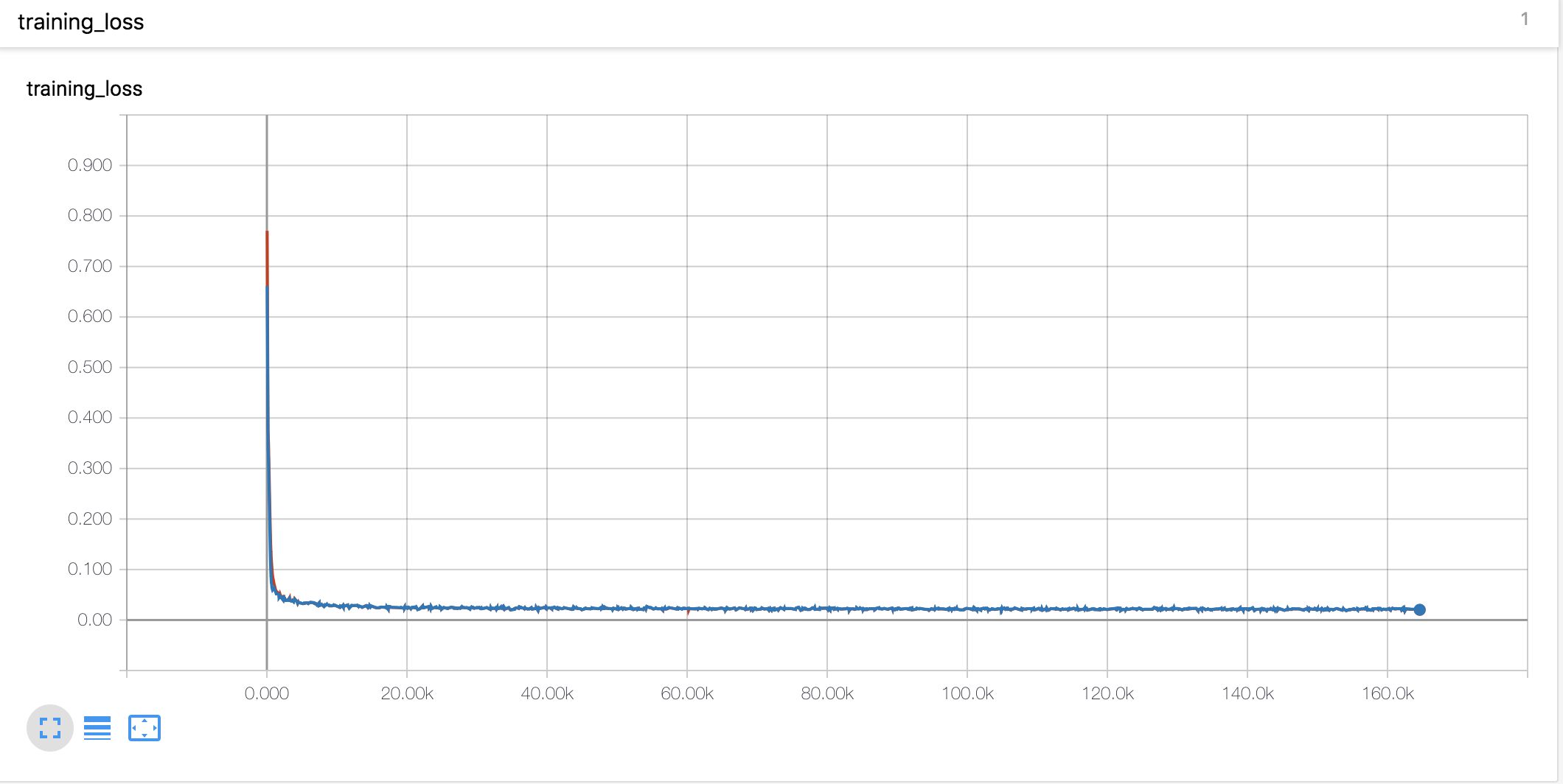
- O valor alfa para a codificação da posição em escala é diferente da tese. No artigo, o valor alfa do codificador é aumentado para 4, enquanto no presente experimento, aumentou ligeiramente no início e depois diminuiu continuamente. O decodificador alfa diminuiu constantemente desde o início.
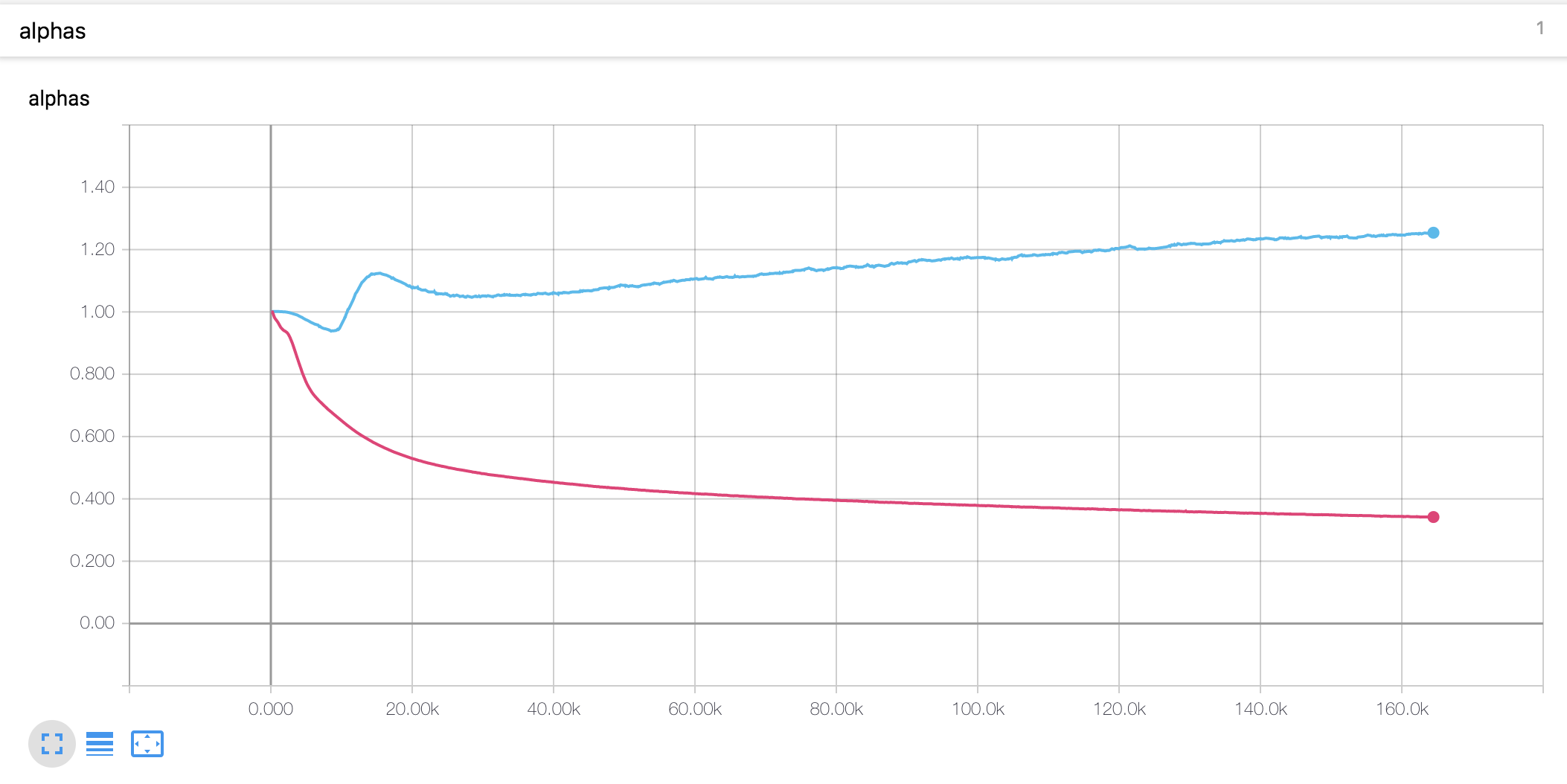
Notas experimentais
- A taxa de aprendizado é um parâmetro importante para o treinamento. Com a taxa de aprendizado inicial de 0,001 e a decadência exponencialmente não funciona.
- O recorte de gradiente também é um parâmetro importante para o treinamento. Acortei o gradiente com o valor da norma 1.
- Com a perda de token parada, o modelo não treinou.
- Era muito importante concatenar os vetores de entrada e contexto no mecanismo de atenção.
Amostras geradas
Você pode verificar algumas amostras geradas abaixo. Todas as amostras são de 160k, então acho que o modelo ainda não está convergido. Este modelo parece ser um desempenho mais baixo em frases longas.
- amostra1
- amostra2
- amostra3
O primeiro enredo é o espectrograma MEL previsto, e o segundo é a verdade fundamental.


Descrição do arquivo
-
hyperparams.py inclui todos os hiper parâmetros necessários. -
prepare_data.py Os arquivos WAV de pré -processamento para MEL, Spectrogram linear e salve -os para um tempo de treinamento mais rápido. Os códigos de pré -processamento para texto estão no texto/ diretório. -
preprocess.py inclui todos os códigos de pré -processamento quando você carrega dados. -
module.py contém todos os métodos, incluindo atenção, pré -rede, pós -rede e assim por diante. -
network.py contém redes, incluindo codificador, decodificador e rede de pós-processamento. -
train_transformer.py é para treinamento da rede de atenção autoregressiva. (texto -> mel) -
train_postnet.py é para treinamento Post Network. (Mel -> Linear) -
synthesis.py é para gerar amostra TTS.
Treinando a rede
- Etapa 1. Download e extrair dados LJSpeech em qualquer diretório desejar.
- Etapa 2. Ajuste os hiperparâmetros em
hyperparams.py , especialmente 'data_path', que é um diretório que você extrai arquivos e os outros, se necessário. - Etapa 3. Execute
prepare_data.py . - Etapa 4. Execute
train_transformer.py . - Etapa 5. Execute
train_postnet.py .
Gerar arquivo WAV TTS
- Etapa 1. Execute
synthesis.py . Verifique se a etapa da restauração.
Referência
- Keith Ito: https://github.com/keithito/tacotron
- Kyubyong Park: https://github.com/kyubyong/dc_tts
- jadore801120: https://github.com/jadore801120/attion-is-all-you-need-pytorch/
Comentários
- Quaisquer comentários para os códigos são sempre bem -vindos.


