Transformator-TTs
- Eine Pytorch -Implementierung der neuronalen Sprachsynthese mit Transformator Network
- Dieses Modell kann etwa 3- bis 4 -mal schneller trainiert werden als das bekannte SEQ2SEQ -Modell wie Tacotron, und die Qualität der synthetisierten Sprache ist fast gleich. Durch Experiment wurde bestätigt, dass es ungefähr 0,5 Sekunden pro Schritt dauerte.
- Ich habe den Wavenet-Vokoder nicht verwendet, sondern das Postnetzwerk mithilfe von Tacotron-Modell-Modell-Modell und das Spektrogramm unter Verwendung des Griffin-Lim-Algorithmus in Rohwellen umgewandelt.
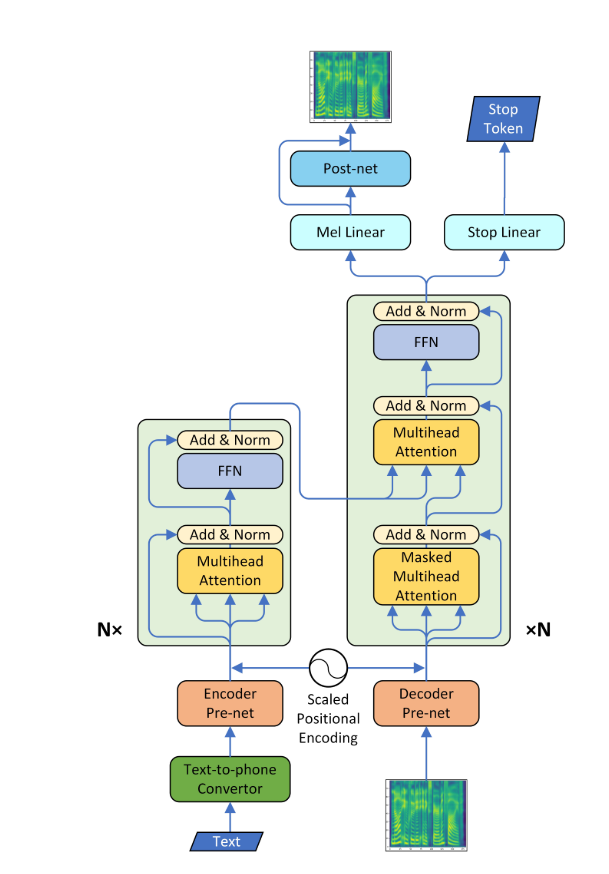
Anforderungen
- Installieren Sie Python 3
- Installieren Sie Pytorch == 0.4.0
- Anforderungen installieren:
pip install -r requirements.txt
Daten
- Ich habe einen LJSpeech -Datensatz verwendet, der aus Textpaaren von Textskript- und WAV -Dateien besteht. Der vollständige Datensatz (13.100 Paare) kann hier heruntergeladen werden. Ich habe auf https://github.com/keithito/tacotron und https://github.com/kyubyong/dc_tts für den Vorverarbeitungscode verwiesen.
Vorbereitetes Modell
- Sie können hier ein vorgezogenes Modell herunterladen (160K für AR -Modell / 100k für PostNet)
- Suchen Sie das vorgezogene Modell am Checkpoint/ Verzeichnis.
Aufmerksamkeitsdiagramme
- Eine diagonale Ausrichtung trat nach etwa 15.000 Schritten auf. Die folgenden Aufmerksamkeitsdiagramme liegen bei 160.000 Schritten. Diagramme repräsentieren die Multihead -Aufmerksamkeit aller Schichten. In diesem Experiment wird H = 4 für drei Aufmerksamkeitsschichten verwendet. Daher wurden 12 Aufmerksamkeitsdiagramme für jeden Encoder-, Decoder- und Encoder-Decoder gezogen. Mit Ausnahme des Decoders zeigten nur wenige Mehrköpfe eine diagonale Ausrichtung.
Selbstaufschlagscodierer

Self -Re -Decoder
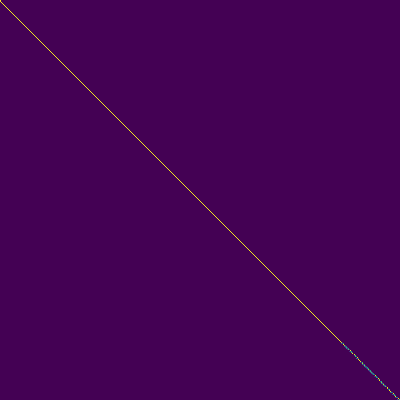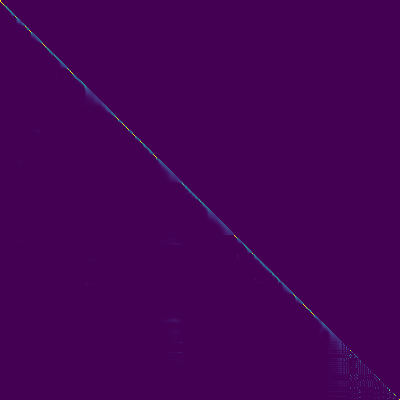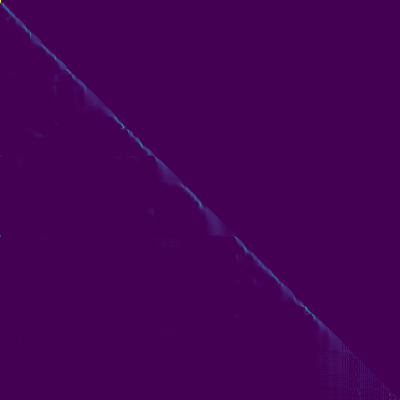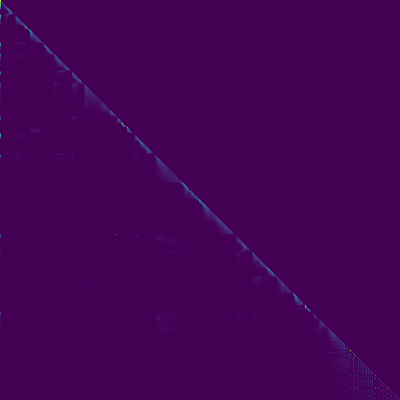
Aufmerksamkeitscodierer-Decoder

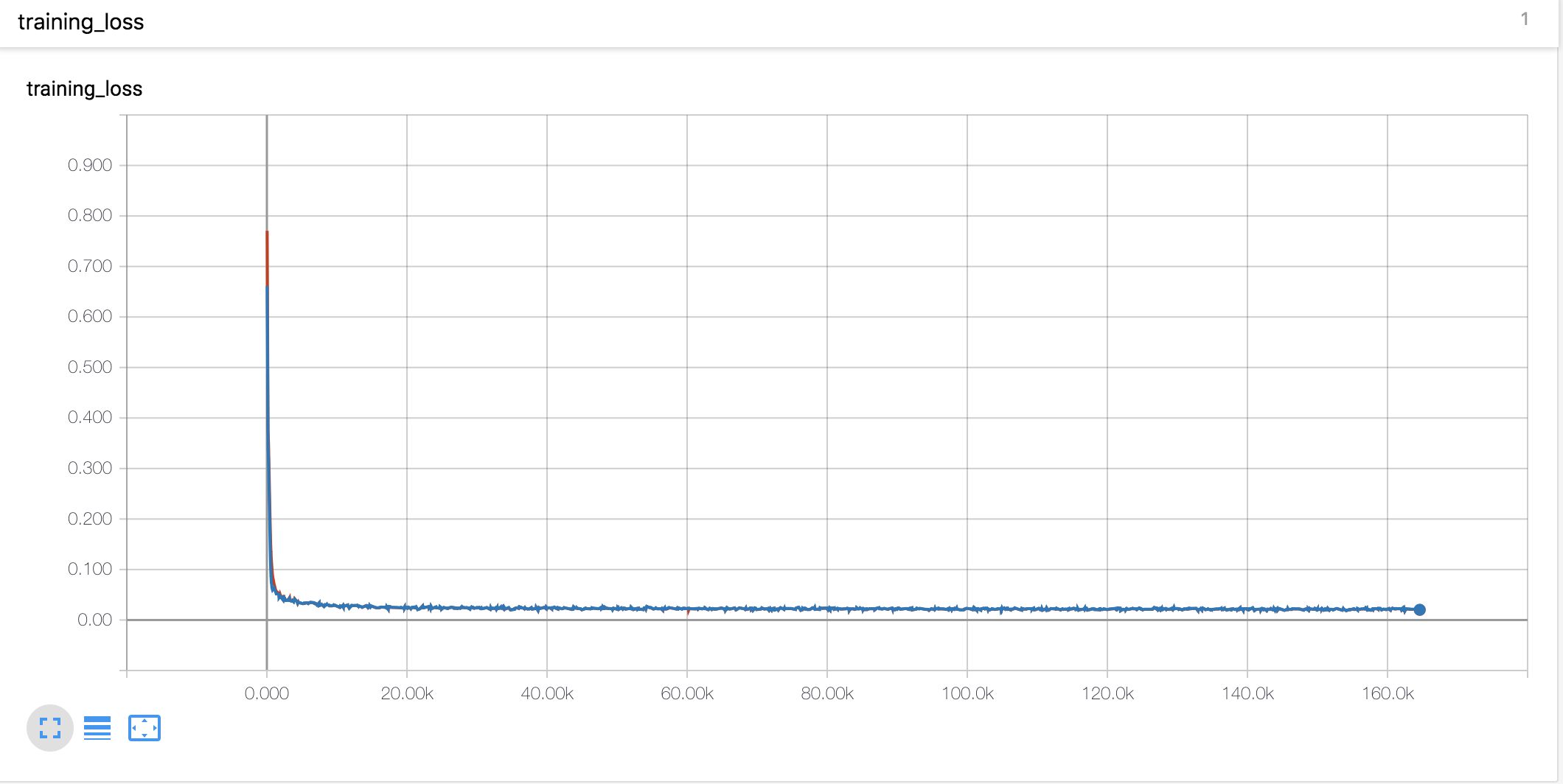
Lernkurven & Alphas
- Ich habe das Aufwärmen und Verfall von Noam -Stil genauso verwendet wie Tacotron
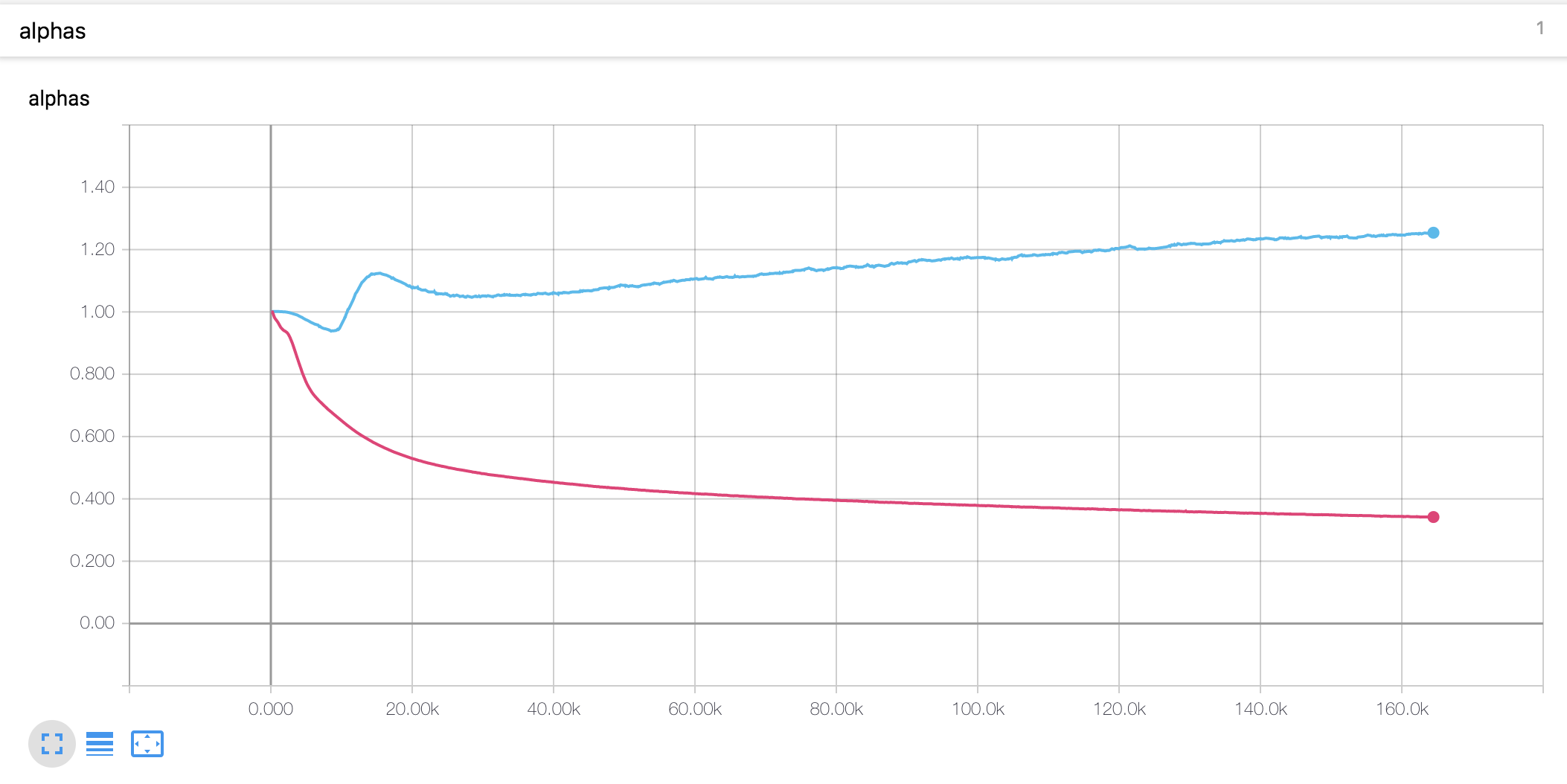
- Der Alpha -Wert für die skalierte Positionscodierung unterscheidet sich von der These. In der Arbeit wird der Alpha -Wert des Encoders auf 4 erhöht, während er in dem vorliegenden Experiment am Anfang geringfügig erhöht und dann kontinuierlich abnahm. Der Decoder Alpha ist seit Anfang an stetig gesunken.
Versuchsnotizen
- Die Lernrate ist ein wichtiger Parameter für das Training. Mit der anfänglichen Lernrate von 0,001 und einer exponentiell Verfall funktioniert nicht.
- Das Gradientenausschnitt ist auch ein wichtiger Parameter für das Training. Ich habe den Gradienten mit Normwert 1 abgeschnitten.
- Mit dem Stop -Token -Verlust hat das Modell nicht trainiert.
- Es war sehr wichtig, die Eingabe- und Kontextvektoren im Aufmerksamkeitsmechanismus zu verkettet.
Erzeugte Proben
Sie können einige generierte Proben unten überprüfen. Alle Stichproben sind bei 160.000 Schritt, daher denke ich, dass das Modell noch nicht konvergiert ist. Dieses Modell scheint in langen Sätzen eine geringere Leistung zu sein.
Das erste Diagramm ist das vorhergesagte MEL -Spektrogramm, und das zweite ist die Grundwahrheit.


Dateibeschreibung
-
hyperparams.py enthält alle benötigten Hyperparameter. -
prepare_data.py Precess -WAV -Dateien in Mel, lineares Spektrogramm und speichern Sie sie für eine schnellere Trainingszeit. Die Vorverarbeitungscodes für Text befinden sich im Text/ Verzeichnis. -
preprocess.py enthält alle Vorverarbeitungscodes, wenn Sie Daten laden. -
module.py enthält alle Methoden, einschließlich Aufmerksamkeit, Prenet, PostNet und so weiter. -
network.py enthält Netzwerke wie Encoder, Decoder und Nachverarbeitungsnetzwerk. -
train_transformer.py ist für das autoregressive Aufmerksamkeitsnetzwerk für das Training. (Text -> mel) -
train_postnet.py ist für das Trainingspostnetzwerk. (mel -> linear) -
synthesis.py dient zur Erzeugung von TTS -Proben.
Training des Netzwerks
- Schritt 1. Download und extrahieren Sie LJSpeech -Daten in jedem gewünschten Verzeichnis.
- Schritt 2. Passen Sie die Hyperparameter in
hyperparams.py an, insbesondere in "Data_Path", ein Verzeichnis, das Sie bei Bedarf Dateien und die anderen extrahieren. - Schritt 3. Run
prepare_data.py . - Schritt 4. Run
train_transformer.py . - Schritt 5. Run
train_postnet.py .
Generieren Sie die TTS -WAV -Datei
- Schritt 1. Ausführen
synthesis.py . Stellen Sie sicher, dass der Wiederherstellungsschritt.
Referenz
- Keith Ito: https://github.com/keithito/tacotron
- Kyubyong Park: https://github.com/kyubyong/dc_tts
- Jadore801120: https://github.com/jadore801120/attention-all-all-you-need-pytorch/
Kommentare
- Alle Kommentare zu den Codes sind immer willkommen.


