Transformateur-TTS
- Une mise en œuvre pytorch de la synthèse de la parole neurale avec le réseau de transformateur
- Ce modèle peut être formé environ 3 à 4 fois plus rapide que le modèle SEQ2SEQ bien connu comme le tacotron, et la qualité de la parole synthétisée est presque la même. Il a été confirmé par l'expérience qu'il a fallu environ 0,5 seconde par étape.
- Je n'ai pas utilisé le vocodeur Wavenet mais j'ai appris le réseau post-réseau en utilisant le modèle CBHG de tacotron et converti le spectrogramme en onde brute à l'aide d'un algorithme Griffin-LIM.
Exigences
- Installer python 3
- Installer pytorch == 0.4.0
- Installation des exigences:
pip install -r requirements.txt
Données
- J'ai utilisé un ensemble de données LJSpeech qui se compose de paires de scripts texte et de fichiers WAV. L'ensemble de données complet (13 100 paires) peut être téléchargé ici. J'ai référé https://github.com/keithito/tacotron et https://github.com/kyubyong/dc_tts pour le code de prétraitement.
Modèle pré-entraîné
- Vous pouvez télécharger un modèle pré-entraîné ici (160k pour le modèle AR / 100K pour PostNet)
- Localisez le modèle pré-entraîné au point de contrôle / répertoire.
Complots d'attention
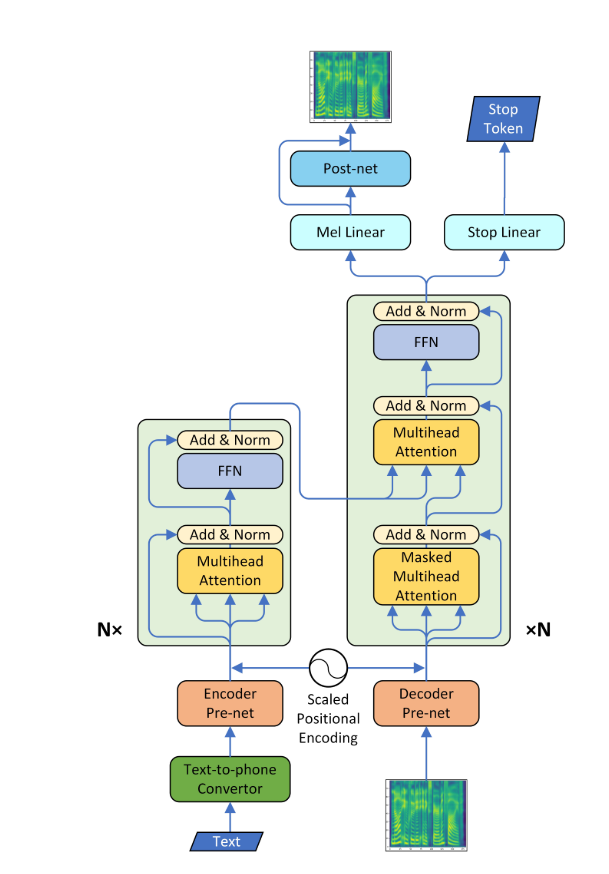
- Un alignement diagonal est apparu après environ 15 000 étapes. Les parcelles d'attention ci-dessous sont à 160 000 étapes. Les parcelles représentent l'attention multi-tête de toutes les couches. Dans cette expérience, H = 4 est utilisé pour trois couches d'attention. Par conséquent, 12 parcelles d'attention ont été dessinées pour chacun des encodeur, du décodeur et de l'encodeur. À l'exception du décodeur, seules quelques multiples multiples ont montré un alignement diagonal.
Encodeur d'attention

Décodeur d'attention
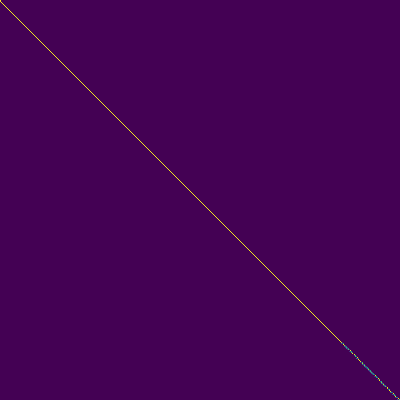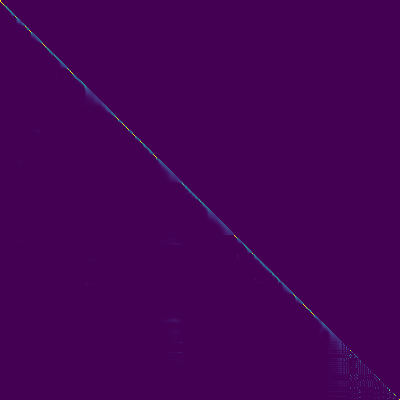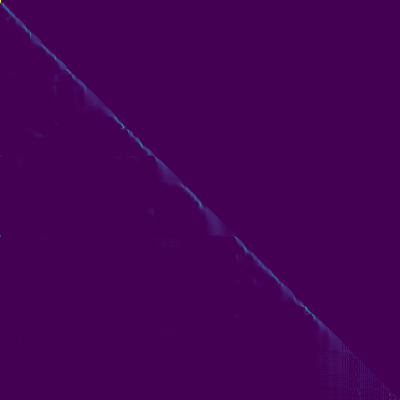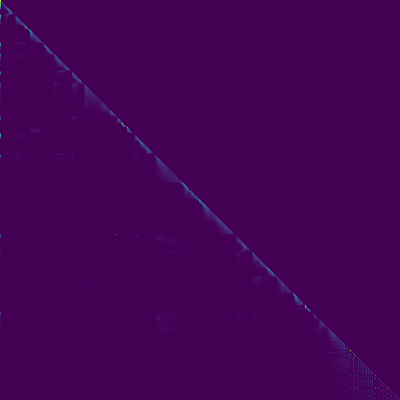
Encodeur d'attention-décodeur

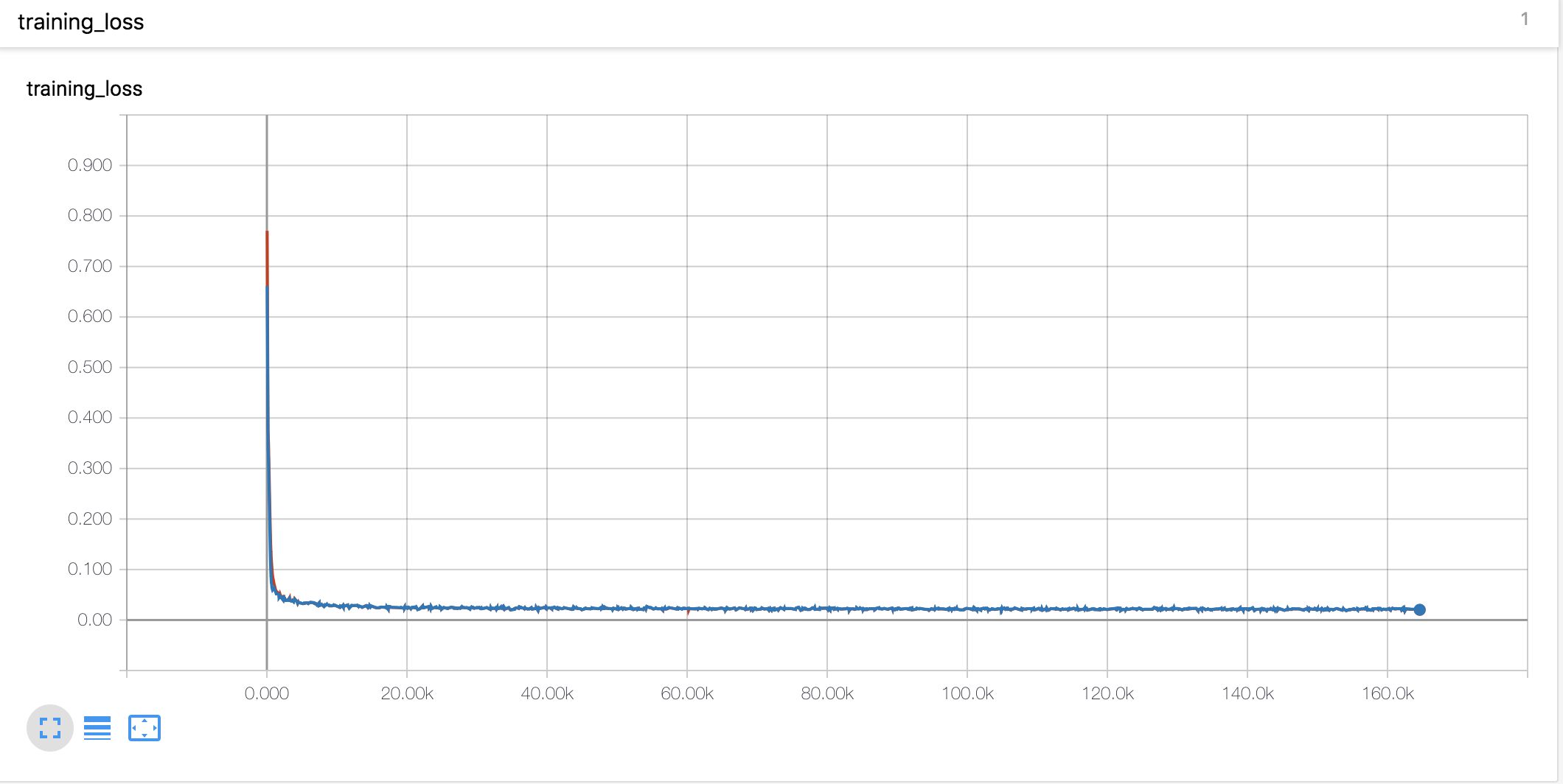
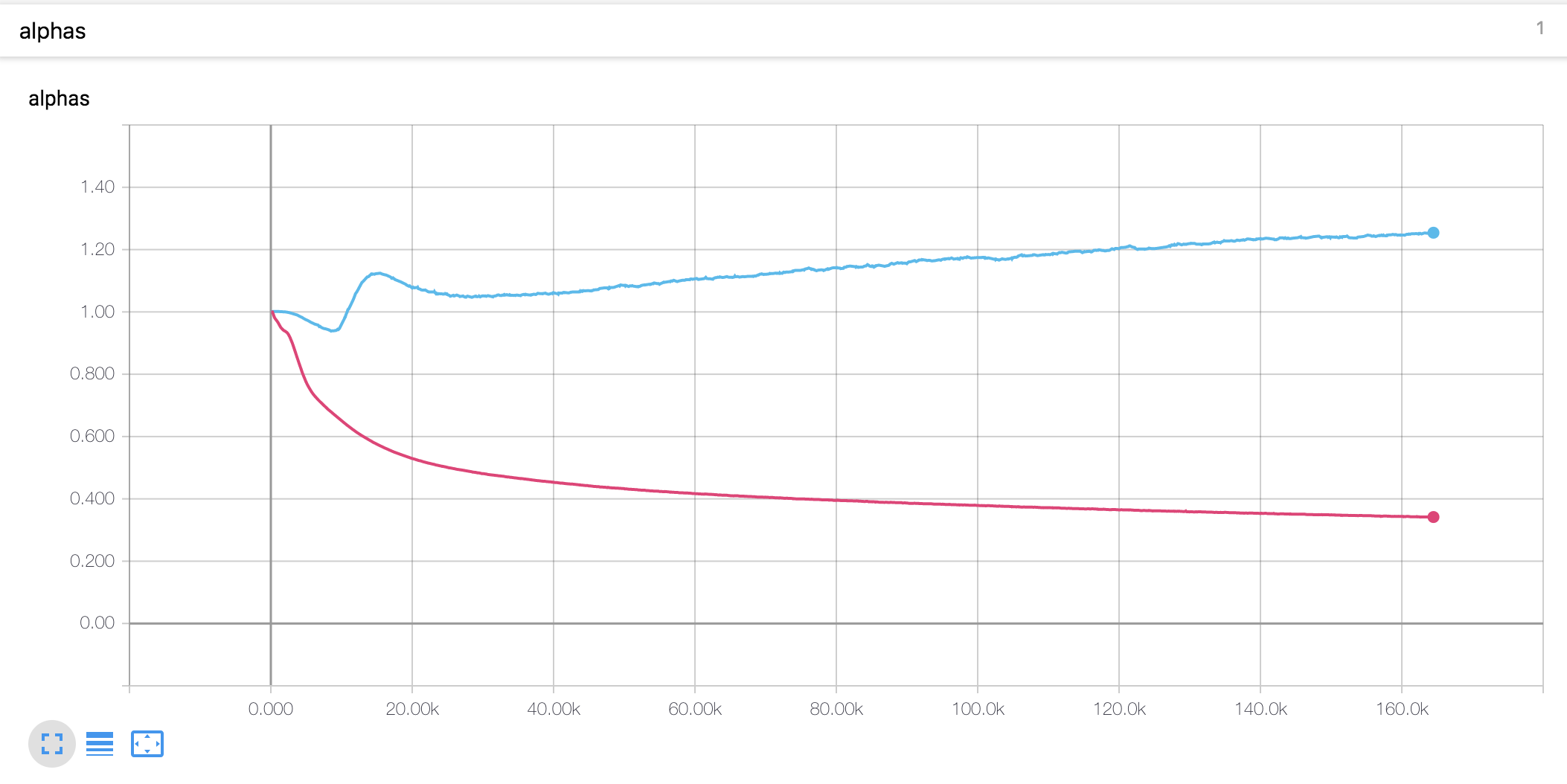
Courbes d'apprentissage et alphas
- J'ai utilisé l'échauffement et la désintégration de style Noam comme le Tacotron
- La valeur alpha pour le codage de position à l'échelle est différente de la thèse. Dans l'article, la valeur alpha de l'encodeur est augmentée à 4, tandis que dans la présente expérience, il a légèrement augmenté au début puis a diminué en continu. Le décodeur alpha a régulièrement diminué depuis le début.
Notes expérimentales
- Le taux d'apprentissage est un paramètre important pour la formation. Avec le taux d'apprentissage initial de 0,001 et la décomposition exponentielle ne fonctionne pas.
- L'écrêtage du gradient est également un paramètre important pour la formation. J'ai coupé le gradient avec la valeur norme 1.
- Avec la perte de jeton d'arrêt, le modèle ne s'est pas entraîné.
- Il était très important de concaténer les vecteurs d'entrée et de contexte dans le mécanisme d'attention.
Échantillons générés
Vous pouvez vérifier certains échantillons générés ci-dessous. Tous les échantillons sont étapés à 160k, donc je pense que le modèle n'est pas encore convergé. Ce modèle semble être des performances plus faibles dans les phrases longues.
- échantillon 1
- échantillon2
- échantillon3
Le premier tracé est le spectrogramme MEL prévu, et le second est la vérité au sol.


Description du fichier
-
hyperparams.py comprend tous les paramètres hyper nécessaires. -
prepare_data.py Fichiers WAV préprocesseurs vers MEL, Spectrogramme linéaire et les enregistrer pour un temps de formation plus rapide. Les codes de prétraitement pour le texte se trouvent dans le texte / répertoire. -
preprocess.py comprend tous les codes de prétraitement lorsque vous chargez des données. -
module.py contient toutes les méthodes, y compris l'attention, le prénet, le postnet et ainsi de suite. -
network.py contient des réseaux, y compris l'encodeur, le décodeur et le réseau de post-traitement. -
train_transformer.py est pour la formation du réseau d'attention autorégressif. (Texte -> Mel) -
train_postnet.py est pour la formation du réseau post-post. (Mel -> linéaire) -
synthesis.py est pour générer un échantillon TTS.
Former le réseau
- Étape 1. Téléchargez et extraire les données LJSpeech dans n'importe quel répertoire que vous souhaitez.
- Étape 2. Ajustez les hyperparamètres dans
hyperparams.py , en particulier 'data_path' qui est un répertoire que vous extraire les fichiers, et les autres si nécessaire. - Étape 3. Exécutez
prepare_data.py . - Étape 4. Exécutez
train_transformer.py . - Étape 5. Exécutez
train_postnet.py .
Générer le fichier TTS WAV
- Étape 1. Exécutez
synthesis.py . Assurez-vous que l'étape de restauration.
Référence
- Keith Ito: https://github.com/keithito/tacotron
- Park Kyubyong: https://github.com/kyubyong/dc_tts
- Jadore801120: https://github.com/jadore801120/attention-is-all-you-need-pytorch/
Commentaires
- Tous les commentaires pour les codes sont toujours les bienvenus.


