Transformer-TTS
- Una implementación de Pytorch de la síntesis de habla neuronal con la red Transformer
- Este modelo puede ser entrenado aproximadamente de 3 a 4 veces más rápido que el conocido modelo SEQ2SEQ como Tacotron, y la calidad del habla sintetizada es casi la misma. Se confirmó a través del experimento que tomó alrededor de 0.5 segundos por paso.
- No usé el Vocoder Wavenet, pero aprendí la red postse utilizando el modelo CBHG de tacotrón y convertí el espectrograma en onda sin procesar usando el algoritmo Griffin-Lim.
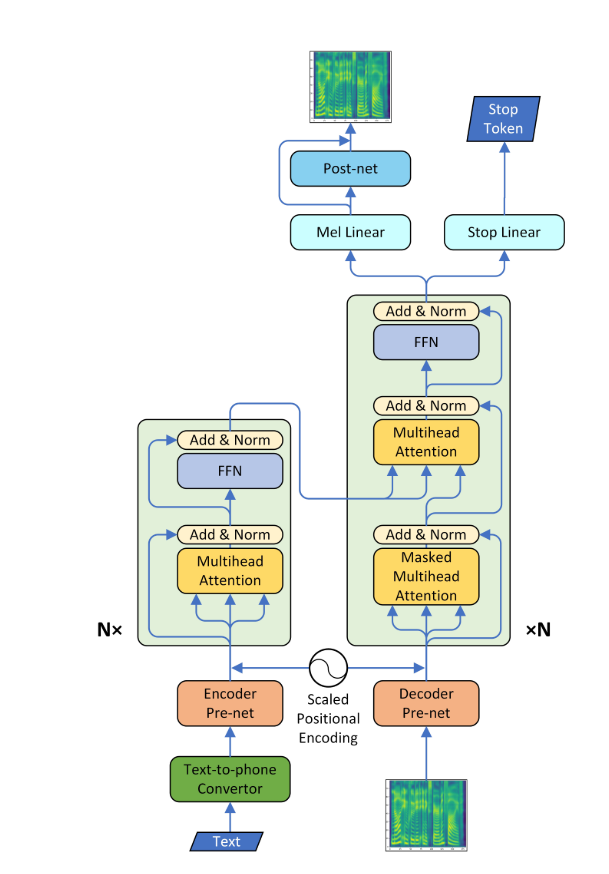
Requisitos
- Instalar Python 3
- Instalar pytorch == 0.4.0
- Requisitos de instalación:
pip install -r requirements.txt
Datos
- Utilicé el conjunto de datos LJSPEECch que consiste en pares de script de texto y archivos WAV. El conjunto de datos completo (13,100 pares) se puede descargar aquí. Me referí https://github.com/keithito/tacotron y https://github.com/kyubyong/dc_tts para el código de preprocesamiento.
Modelo previamente
- Puede descargar el modelo previo a la petróleo aquí (160k para modelo AR / 100k para Postnet)
- Localice el modelo previamente en el punto de control/ directorio.
Tramas de atención
- Apareció una alineación diagonal después de unos 15k pasos. Las parcelas de atención a continuación están en 160k pasos. Las gráficas representan la atención de múltiples cabezas de todas las capas. En este experimento, H = 4 se usa para tres capas de atención. Por lo tanto, se dibujaron 12 gráficos de atención para cada uno de los codificadores, decodificadores y codificadores del codificador. Con la excepción del decodificador, solo unos pocos múltiples cabezas mostraron alineación diagonal.
Codificador

Decodificador
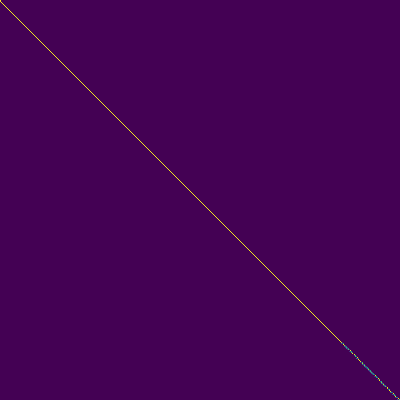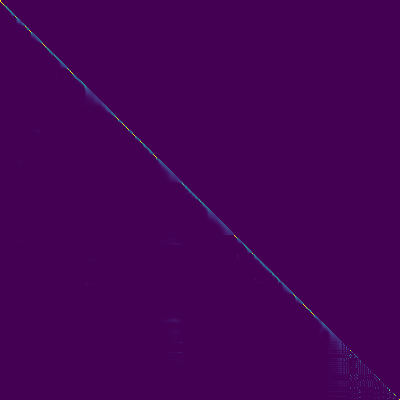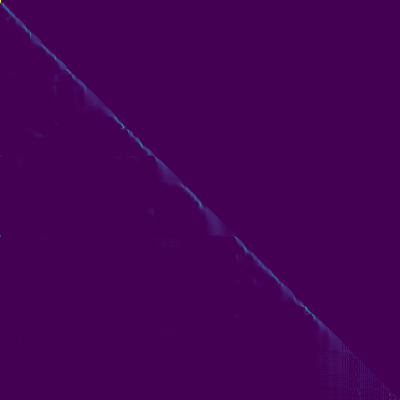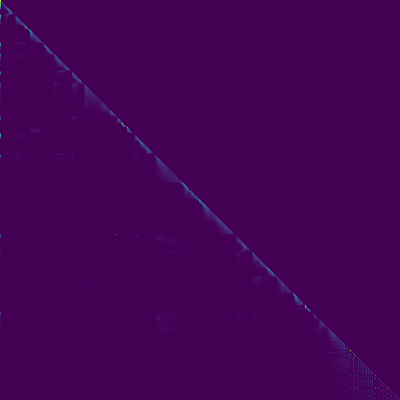
Codador de atención Decoder

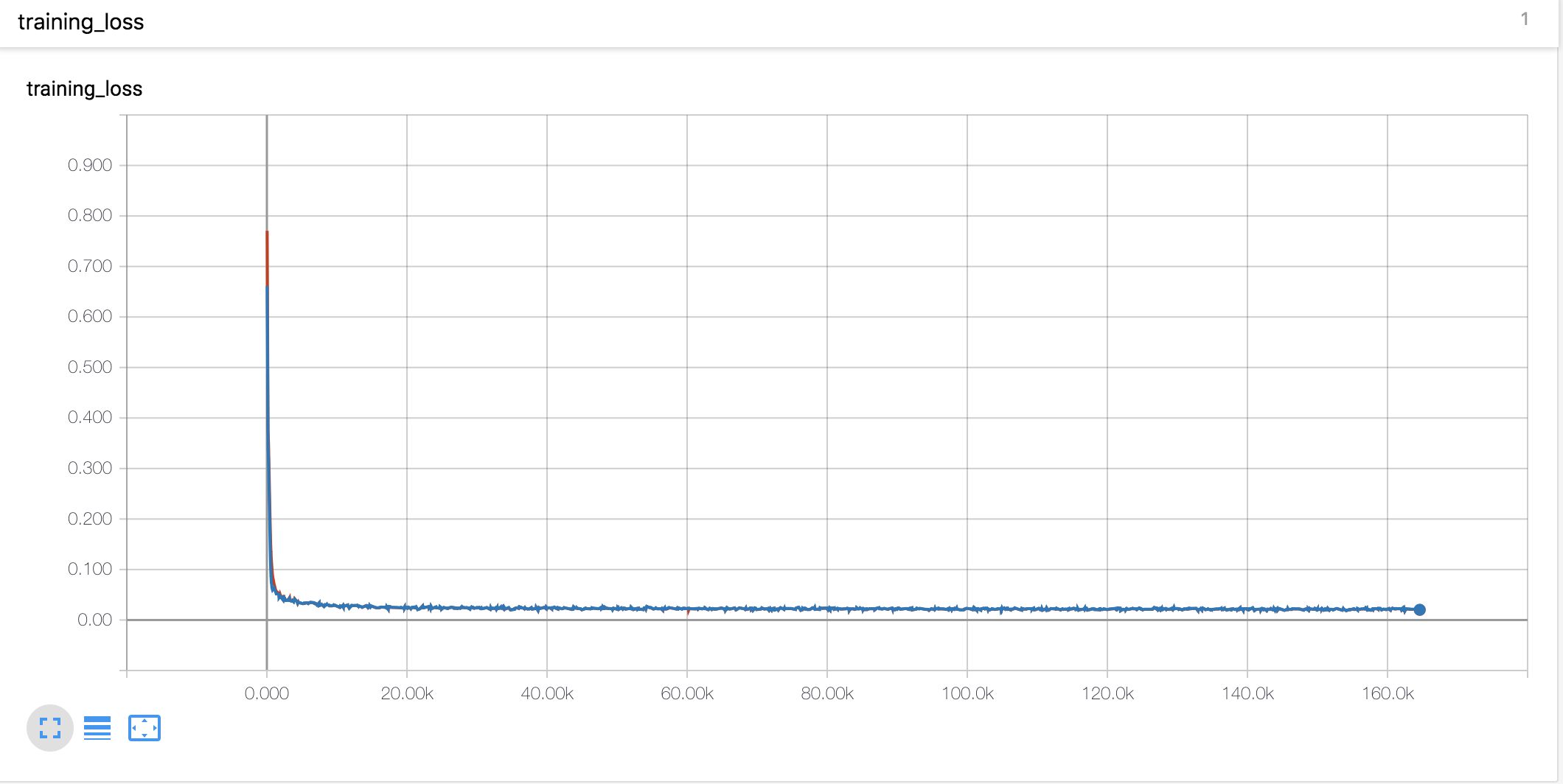
Curvas y alfas de aprendizaje
- Usé el calentamiento de estilo Noam y la descomposición del mismo que Tacotron
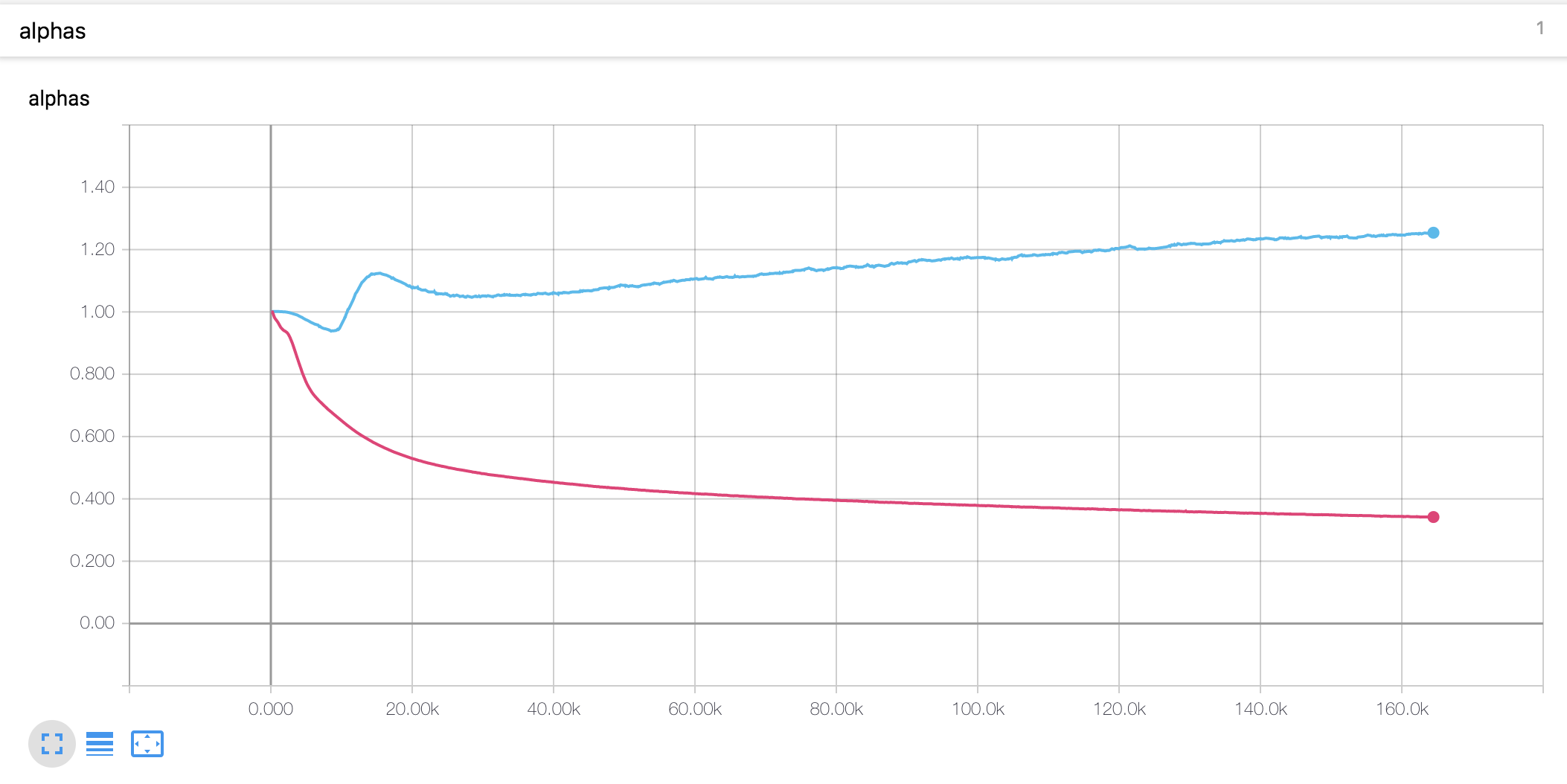
- El valor alfa para la codificación de posición escalada es diferente de la tesis. En el documento, el valor alfa del codificador aumenta a 4, mientras que en el presente experimento, aumentó ligeramente al principio y luego disminuye continuamente. El decodificador alfa ha disminuido constantemente desde el principio.
Notas experimentales
- La tasa de aprendizaje es un parámetro importante para la capacitación. Con una tasa de aprendizaje inicial de 0.001 y el descomposición exponencialmente no funciona.
- El recorte de gradiente también es un parámetro importante para el entrenamiento. Recorté el gradiente con el valor de la norma 1.
- Con la pérdida de token de parada, el modelo no entrenó.
- Era muy importante concatenar los vectores de entrada y contexto en el mecanismo de atención.
Muestras generadas
Puede verificar algunas muestras generadas a continuación. Todas las muestras son un paso a 160k, por lo que creo que el modelo aún no está convergido. Este modelo parece ser un rendimiento más bajo en oraciones largas.
- muestra 1
- muestra2
- muestra3
La primera trama es el espectrograma MEL predicho, y el segundo es la verdad del suelo.


Descripción del archivo
-
hyperparams.py incluye todos los parámetros Hyper que se necesitan. -
prepare_data.py Preprocess WAV Archivos a MEL, espectrograma lineal y guárdelos para un tiempo de entrenamiento más rápido. Los códigos de preprocesamiento para el texto están en texto/ directorio. -
preprocess.py incluye todos los códigos de preprocesamiento cuando carga datos. -
module.py contiene todos los métodos, que incluyen atención, prenet, postnet, etc. -
network.py contiene redes que incluyen el codificador, el decodificador y la red de postprocesamiento. -
train_transformer.py es para capacitar la red de atención autorregresiva. (Texto -> Mel) -
train_postnet.py es para entrenamiento de la red post. (Mel -> Lineal) -
synthesis.py es para generar una muestra TTS.
Entrenando la red
- Paso 1. Descargue y extraiga los datos de LJSpeech en cualquier directorio que desee.
- Paso 2. Ajuste los hiperparámetros en
hyperparams.py , especialmente 'data_path', que es un directorio que extrae archivos, y los demás si es necesario. - Paso 3. Ejecute
prepare_data.py . - Paso 4. Ejecute
train_transformer.py . - Paso 5. Ejecute
train_postnet.py .
Generar archivo WAV TTS
- Paso 1. Ejecute
synthesis.py . Asegúrese de que el paso de restauración.
Referencia
- Keith Ito: https://github.com/keithito/tacotron
- Parque Kyubyong: https://github.com/kyubyong/dc_tts
- jadore801120: https://github.com/jadore801120/attention-is-all-you-need-pytorch/
Comentario
- Cualquier comentario para los códigos siempre es bienvenido.


