Transformer-tts
- Implementasi Pytorch dari sintesis pidato saraf dengan Transformer Network
- Model ini dapat dilatih sekitar 3 hingga 4 kali lebih cepat dari model SEQ2SEQ yang terkenal seperti Tacotron, dan kualitas ucapan yang disintesis hampir sama. Dikonfirmasi melalui percobaan bahwa butuh sekitar 0,5 detik per langkah.
- Saya tidak menggunakan vocoder Wavenet tetapi mempelajari jaringan pos menggunakan model tacotron CBHG dan mengubah spektrogram menjadi gelombang mentah menggunakan algoritma Griffin-Lim.
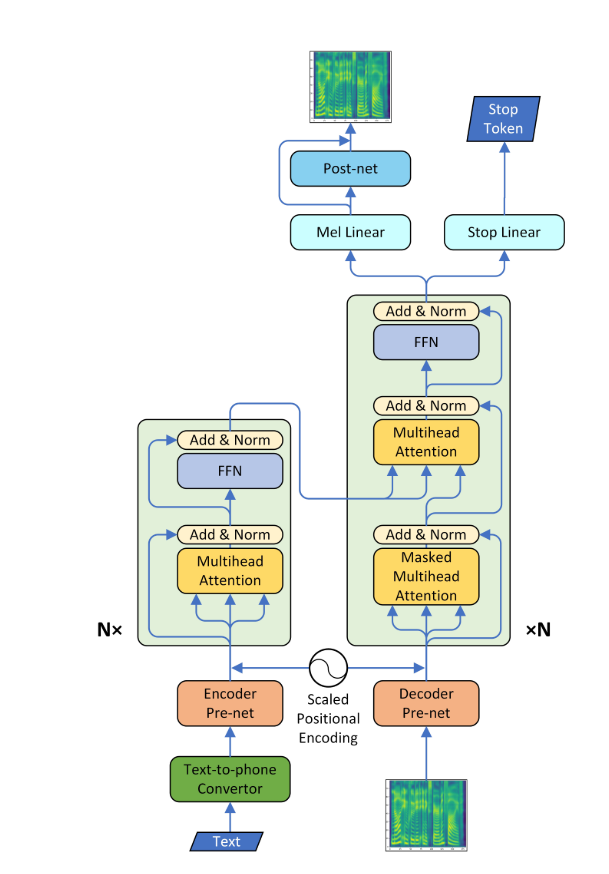
Persyaratan
- Pasang Python 3
- Instal pytorch == 0.4.0
- Instal Persyaratan:
pip install -r requirements.txt
Data
- Saya menggunakan dataset ljspeech yang terdiri dari pasangan skrip teks dan file wav. Dataset lengkap (13.100 pasang) dapat diunduh di sini. Saya merujuk https://github.com/keithito/tacotron dan https://github.com/kyubyong/dc_tts untuk kode preprocessing.
Model pretrained
- Anda dapat mengunduh model pretrained di sini (160K untuk AR Model / 100K untuk PostNet)
- Temukan model pretrained di pos pemeriksaan/ direktori.
Plot perhatian
- Penyelarasan diagonal muncul setelah sekitar 15 ribu langkah. Plot perhatian di bawah ini berada pada langkah 160 ribu. Plot mewakili perhatian multi -kepala dari semua lapisan. Dalam percobaan ini, H = 4 digunakan untuk tiga lapisan perhatian. Oleh karena itu, 12 plot perhatian ditarik untuk masing-masing encoder, dekoder dan encoder-decoder. Dengan pengecualian decoder, hanya beberapa multi -kepala yang menunjukkan keberpihakan diagonal.
Encoder perhatian diri

Decoder Perhatian Diri
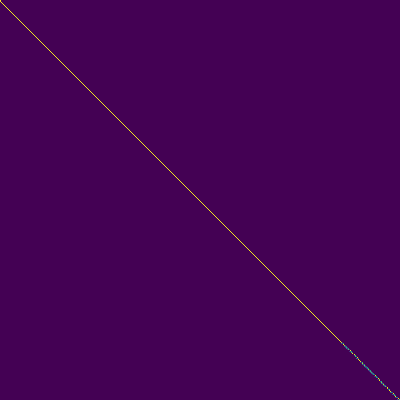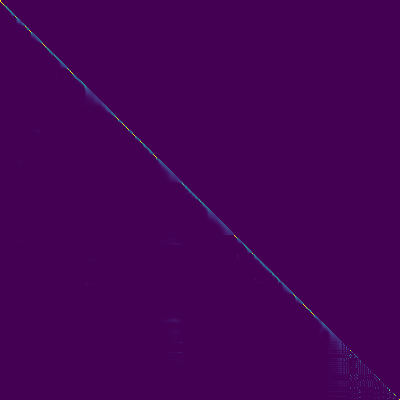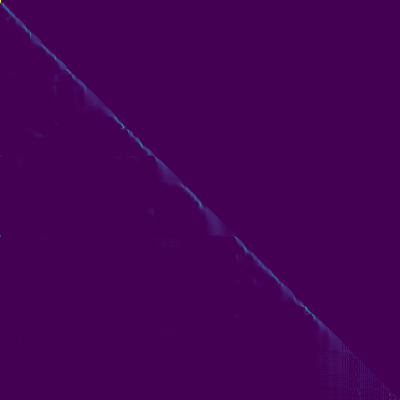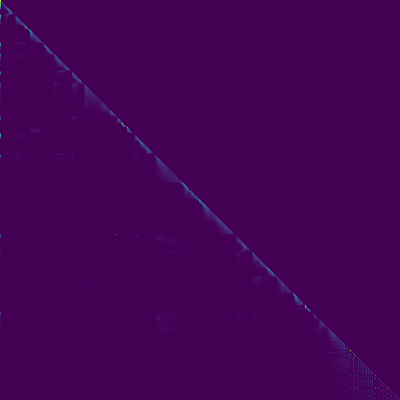
Perhatian Encoder-Decoder

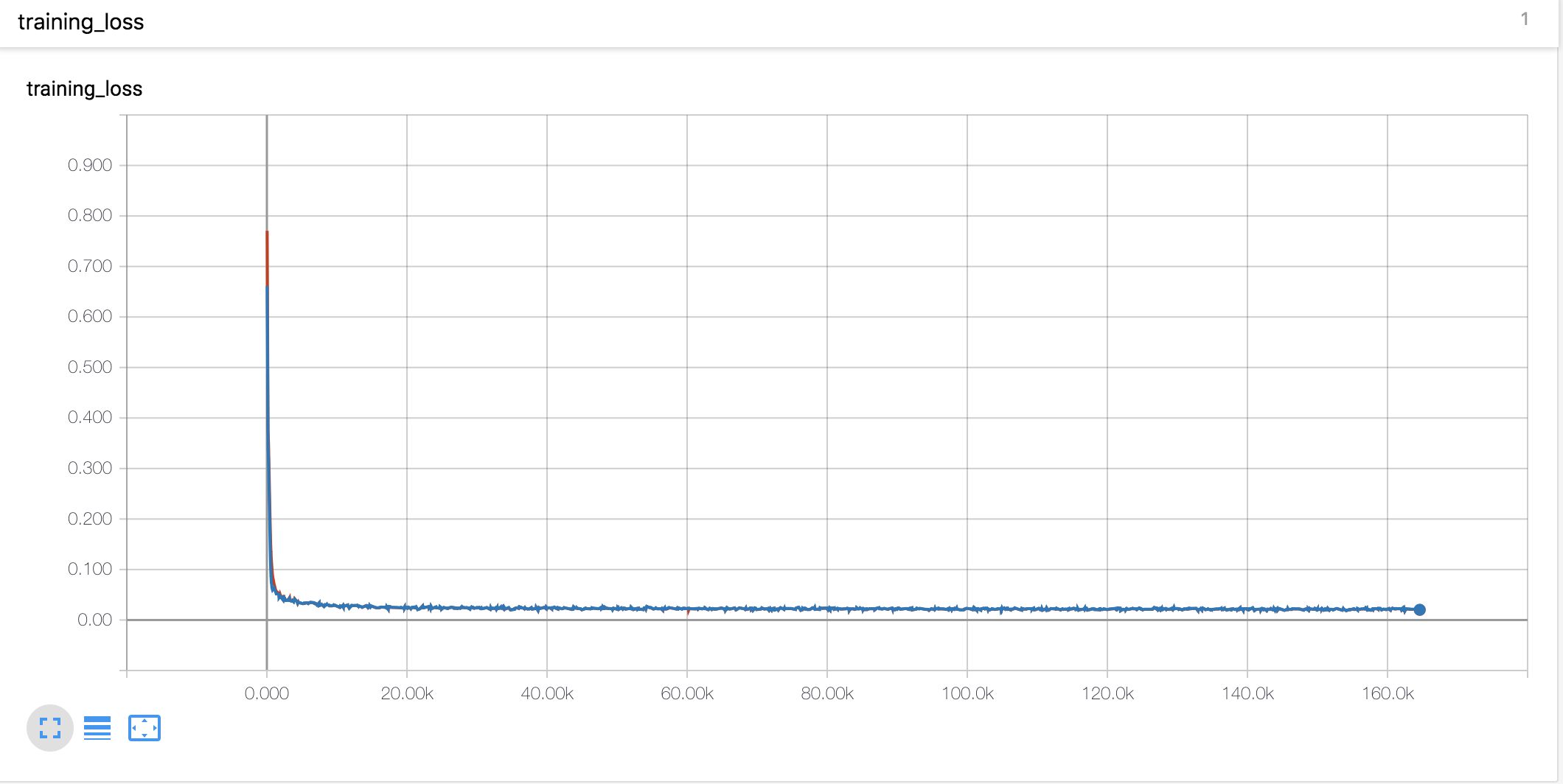
Kurva Belajar & Alfa
- Saya menggunakan pemanasan dan peluruhan gaya Noam sama seperti Tacotron
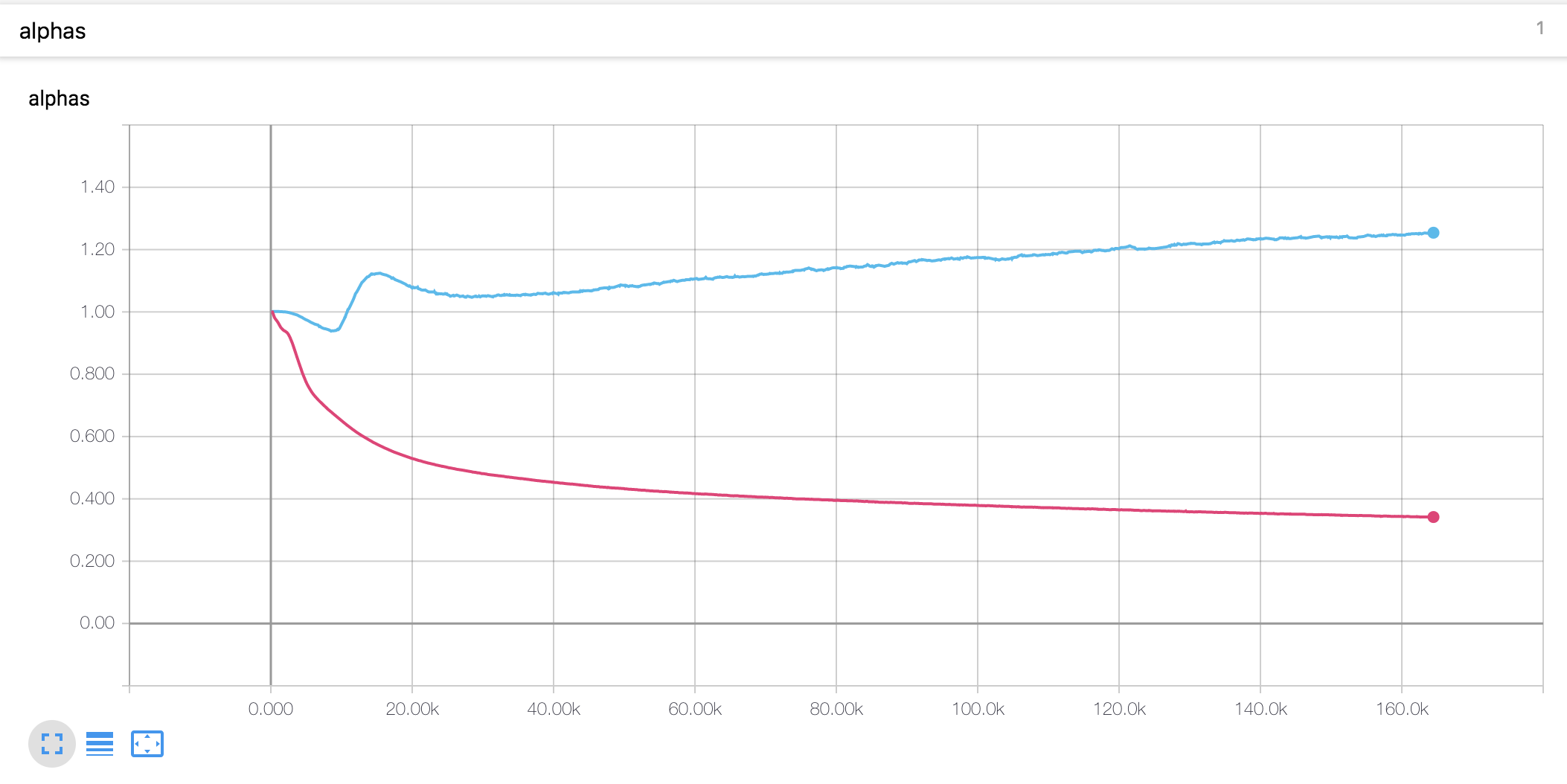
- Nilai alfa untuk pengkodean posisi skala berbeda dari tesis. Dalam makalah, nilai alfa enkoder meningkat menjadi 4, sedangkan dalam percobaan ini, itu sedikit meningkat di awal dan kemudian menurun terus menerus. Decoder Alpha terus menurun sejak awal.
Catatan Eksperimental
- Tingkat pembelajaran adalah parameter penting untuk pelatihan. Dengan tingkat pembelajaran awal 0,001 dan peluruhan secara eksponensial tidak berhasil.
- Kliping gradien juga merupakan parameter penting untuk pelatihan. Saya memotong gradien dengan nilai norma 1.
- Dengan kehilangan token stop, model tidak berlatih.
- Sangat penting untuk menggabungkan input dan vektor konteks dalam mekanisme perhatian.
Sampel yang dihasilkan
Anda dapat memeriksa beberapa sampel yang dihasilkan di bawah ini. Semua sampel adalah langkah 160K, jadi saya pikir modelnya belum bertemu. Model ini tampaknya lebih rendah kinerja dalam kalimat panjang.
Plot pertama adalah prediksi MEL Spectrogram, dan yang kedua adalah kebenaran dasar.


Deskripsi file
-
hyperparams.py mencakup semua parameter hiper yang diperlukan. -
prepare_data.py preprocess wav file ke Mel, spektrogram linier dan simpan untuk waktu pelatihan yang lebih cepat. Kode preprocessing untuk teks ada dalam teks/ direktori. -
preprocess.py mencakup semua kode preprocessing saat Anda memuat data. -
module.py berisi semua metode, termasuk perhatian, prenet, postnet dan sebagainya. -
network.py berisi jaringan termasuk encoder, decoder dan jaringan pasca pemrosesan. -
train_transformer.py adalah untuk melatih jaringan perhatian autoregresif. (Teks -> Mel) -
train_postnet.py adalah untuk pelatihan jaringan pos. (Mel -> Linear) -
synthesis.py adalah untuk menghasilkan sampel TTS.
Melatih jaringan
- Langkah 1. Unduh dan ekstrak data ljspeech di direktori mana pun yang Anda inginkan.
- Langkah 2. Sesuaikan hyperparameter di
hyperparams.py , terutama 'data_path' yang merupakan direktori yang Anda ekstrak file, dan yang lainnya jika perlu. - Langkah 3. Jalankan
prepare_data.py . - Langkah 4. Jalankan
train_transformer.py . - Langkah 5. Jalankan
train_postnet.py .
Menghasilkan file tts wav
- Langkah 1. Jalankan
synthesis.py . Pastikan langkah pemulihan.
Referensi
- Keith Ito: https://github.com/keithito/tacotron
- Taman Kyubyong: https://github.com/kyubyong/dc_tts
- JADORE801120: https://github.com/jadore801120/attention-is-all-you-need-pytorch/
Komentar
- Setiap komentar untuk kode selalu diterima.


