FCL taco2
1.0.0
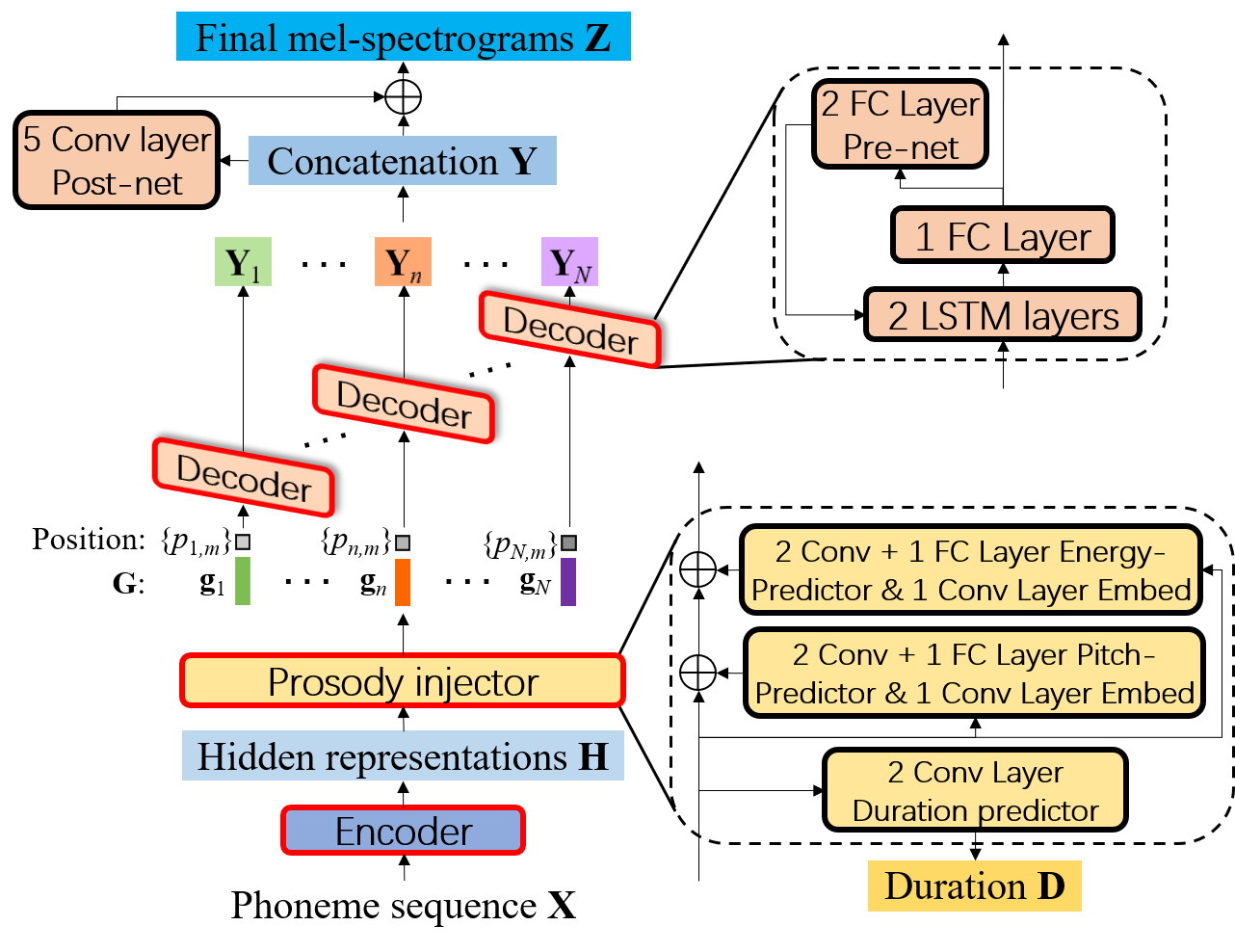
Diagrama de blocos do FCL-Taco2, onde o decodificador gera espectrogramas MEL no modo AR dentro de cada fonema e é compartilhado para todos os fonemas.
Baixe LJSpeech
Desmarque baixado ljspeech-1.1.tar.bz2 para /xx/ljspeech-1.1
Obtenha as informações de alinhamento forçado usando a ferramenta Aligner forçada de Montreal. Ou você pode baixar nossos resultados de alinhamento e descompactá -los para /xx /textGrid
Pré-processo o conjunto de dados para extrair espectrogramas MEL, duração do fonema, afinação, energia e sequência de fonemas por:
python preprocessing.py --data-root /xx/LJSpeech-1.1 --textgrid-root /xx/TextGrid
Professor de treinamento Modelo FCL-Taco2-T:
./teacher_model_training.sh
Treinamento Modelo do aluno FCL-Taco2-S:
./student_model_training.sh
Treinamento do vocoder de onda paralela: Siga as instruções aqui. Você também pode baixar o vocoder PWG pré-treinado e colocar o modelo PWG no diretório "vocoder".
Avaliação Fcl-Taco2-T:
./inference_teacher.sh
Avaliação FCL-TACO2-S:
./inference_student.sh
Se o código for usado em sua pesquisa, estrela nosso repositório e cite nosso artigo:
@inproceedings{wang2021fcl,
title={Fcl-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech Synthesis},
author={Wang, Disong and Deng, Liqun and Zhang, Yang and Zheng, Nianzu and Yeung, Yu Ting and Chen, Xiao and Liu, Xunying and Meng, Helen},
booktitle={ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={5714--5718},
year={2021},
organization={IEEE}
}


